为什么要了解xml 报文 的解析方式呢?我觉得有两种情况:
- 项目需求,比如接口调用时,接收到的数据是xml报文,这时候你需要解析xml报文,然后将其封装成对应的实体类,最后将报文中的数据写入库中。
- 有利于阅读框架源码,在Java众多优秀的开源框架中,有许多框架用到xml报文解析,比如,强大的Spring(虽然后来官方推荐采用注解的方式创建对象),Mybatis框架(解析Mybatis-config.xml和对应的XxxMapper.xml文件)等。
那么xml报文有哪些解析方式呢?答案有4种,前两种与平台无关,后两种是在Java环境中封装前两种方式,使调用者更加方便地使用。
XML解析的四种方式
- DOM解析
- SAX解析
- JDOM解析
- DOM4J解析
下面,分别介绍这4种解析方式的特点。
一、DOM解析
优点:
- 将xml文档转换为树形结构,易于理解
- 解析过程中,熟悉结构在内存中保存,易于修改
缺点:
- 一次性读取整个xml报文,占用内存,对机器性能要求较高
>代码逻辑实现:采用工厂模式创建实例对象
基本流程:
- 实例化 Document BuilderFactory对象
- 调用newDocumentBuilder()方法生成DocumentBuilder对象
- 调用parse()方法,解析xml,生成Document对象
- 用Document对象处理节点数据
1. xml报文 :
<?xml version="1.0" encoding="UTF-8" ?>
<father id="张大">
<child id="张三">
<age value = "18"/>
<height>172</height>
</child>
<child id="张四">
<age value="19"/>
<height>173</height>
</child>
</father> 2. 代码举例:
public class DOMResolve {
private static final InputStream in;
static {
in = DOMResolve.class.getClassLoader().getResourceAsStream("test.xml");
if (in != null) {
System.out.println("加载成功...");
}
}
public static void main(String[] args) {
// 定义一个工厂API,该API使应用程序能够获取从XML文档生成DOM对象树的解析器
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
try {
// 通过DocumentBuilderFactory生成DocumentBuilder对象,该对象通过加载xml文件生成Document对象
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
// 调用parse()方法,解析xml,生成Document对象
Document document = documentBuilder.parse(in);
// 获取父节点father
node List father = document.get element sByTagName("father");
if (father.getLength() != 1) {
throw new RuntimeException("xml报文父节点为空或多于1个");
}
Node item = father.item(0);
System.out.println("父节点:" + item.getNodeName());
NamedNodeMap attributes1 = item.getAttributes();
for (int i = 0; i < attributes1.getLength(); i++) {
Node attr = attributes1.item(i);
// 属性名、 属性值
System.out.println(attr.getNodeName() + " = " + attr.getNodeValue());
}
// 获取指定的子节点child
NodeList childNodes = document.get Element sByTagName("child");
for (int i = 0; i < childNodes.getLength(); i++) {
Node node = childNodes.item(i);
System.out.println("t二级节点:" + node.getNodeName());
// 获取子节点的属性
NamedNodeMap attributes = node.getAttributes();
for (int j = 0; j < attributes.getLength(); j++) {
Node node1 = attributes.item(j);
System.out.print("tt" + node1.getNodeName() + "=" + node1.getNodeValue());
}
// 如果有子标签
if (node.hasChildNodes()) {
// 获取子节点下面的所有子标签
NodeList nodeChildNodes = node.getChildNodes();
for (int j = 0; j < nodeChildNodes.getLength(); j++) {
Node item2 = nodeChildNodes.item(j);
// 如果标签类型为Element
if (item2.getNodeType() == Node.ELEMENT_NODE) {
// 如果有属性标签,则打印出来
if (item2.hasAttributes()) {
NamedNodeMap attributes2 = item2.getAttributes();
for (int k = 0; k < attributes2.getLength(); k++) {
Node item1 = attributes2.item(0);
System.out.print("t" + item1.getNodeName() + "=" + item1.getNodeValue());
}
System.out.println();
}
System.out.println("ttt子节点=" + item2.getNodeName() + ", content = " + item2.getTextContent().trim());
}
}
}
}
} catch (ParserConfigurationException | SAXException | IOException e) {
e.printStackTrace();
}
}
} 二、SAX解析
SAX(Simple APIs for Xml) 简单的XML操作API,它是基于事件驱动的顺序访问模式,从头到尾逐个元素读取内容。
优点:
- 基于事件驱动,消耗内存小
缺点:
- 编码麻烦,需要重写DefaultHandler类的方法
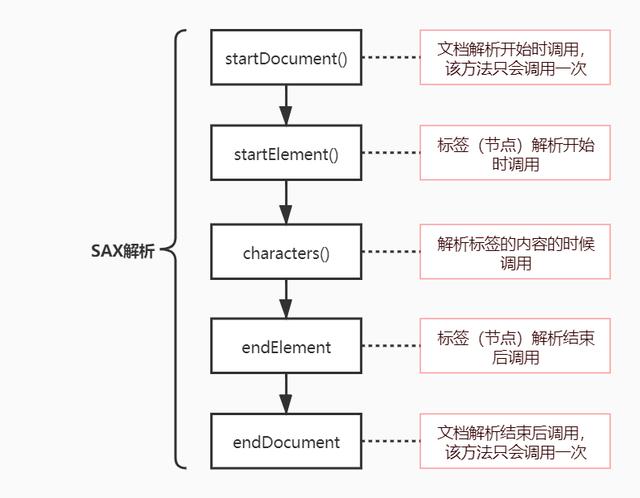
SAX解析流程
- xml报文
<?xml version="1.0" encoding="UTF-8"?>
<father id="张大">
<child id="1">
<age>18</age>
<name>jack</name>
</child>
<child id="2">
<age>20</age>
<name>michael</name>
</child>
</father> - 自定义Handler,该Handler继承DefaultHandler
public class ChildHandler extends DefaultHandler {
/**
* startDocument开始索引
*/ private static int startIndex = 0;
/**
* endDocument结束所有
*/ private static int endIndex = 0;
/**
* 当前解析到的节点名称
*/ private String currentTag;
/**
* 当前的节点对象
*/ private Child child;
/**
* 文档集合
*/ private List<Child> list;
public List<Child> getList() {
return list;
}
/**
* 文档解析时开始调用,该方法只会被调用一次
*
* @throws SAXException
*/ @Override
public void startDocument() throws SAXException {
super.startDocument();
list = new ArrayList<>();
startIndex = startIndex + 1;
System.out.println("xml文档解析开始,调用次数:" + startIndex);
}
/**
* 标签开始解析时调用
*
* @param uri xml文档的命名空间
* @param localName 包含名称空间的标签,如果没有名称空间,则为空
* @param qName 不包含名称空间的标签
* @param attributes 标签的属性集
* @throws SAXException
*/ @Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
if ("child".equals(qName)){
// 遍历属性
for (int i = 0; i < attributes.getLength(); i++) {
child = new Child();
if ("id".equals(attributes.getLocalName(i))){
child.setId(attributes.getValue(i));
}
}
}
currentTag = qName;
}
/**
* 解析标签的内容的时候调用
*
* @param ch 当前读取到的TextNode(文本节点)的字节数组
* @param start 字节开始的位置,为0表示读取全部
* @param length 当前TextNode的长度
* @throws SAXException
*/ @Override
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
// 将当前读取TextNode转换为String
String value = new String(ch, start, length);
if ("age".equals(currentTag)){
child.setAge(Integer.parseInt(value));
}else if ("name".equals(currentTag)){
child.setName(value);
}
}
/**
* 标签结束时调用
*
* @param uri xml文档的命名空间
* @param localName 包含名称空间的标签,如果没有名称空间,则为空
* @param qName 不包含名称空间的标签
* @throws SAXException
*/ @Override
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
if ("child".equals(qName)){
list.add(child);
child = null;
}
// 当碰到结束标签时,将当前标签置为null
currentTag = null;
}
/**
* 文档解析结束时调用,该方法只会被调用一次
*
* @throws SAXException
*/ @Override
public void endDocument() throws SAXException {
super.endDocument();
endIndex = endIndex + 1;
System.out.println("xml文档解析结束,调用次数:" + endIndex);
}
} - 加载配置文件,测试
public class SaxBuilderTest {
private static final InputStream in;
static {
in = SaxBuilderTest.class.getResourceAsStream("users.xml");
}
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
// 实例化SAXParserFactory,由于SAXParserFactory的构造方法受保护的,因此无法new,必须的调用其提供的实例化方法newInstance
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
// 实例化SAXParser解析器
SAXParser parser = saxParserFactory.newSAXParser();
// 创建自定义Handler,该Handler继承DefaultHandler
ChildHandler handler = new ChildHandler();
// Handler顺序解析配置文件
parser.parse(in, handler);
List<Child> list = handler.getList();
for (Child child : list) {
System.out.println(child);
}
}
}
输出:
Child{id='1', age=18, name='jack'}
Child{id='2', age=20, name='michael'} 三、JDOM解析
JDOM是一个开源项目,它基于树形结构,利用纯Java的技术对XML文档实现解析、生成、序列化及多种操作。
JDOM与DOM非常类似,它是处理XML的纯JAVA API,API大量使用了Collections类,且JDOM仅使用具体类而不使用接口。JDOM 它自身不包含解析器。它通常使用 SAX2 解析器来解析和验证输入 XML 文档(尽管它还可以将以前构造的 DOM 表示作为输入)。
导入依赖:
<dependency>
<groupId>org.jdom</groupId>
<artifactId>jdom2</artifactId>
</dependency>
@SpringBootTest
public class JDOMTest {
@Test
public void jdomTest(){
try{
InputStream in = new FileInputStream(new File("src/test/resources/test.xml"));
List<Child> list = new ArrayList<>();
SAXBuilder saxBuilder = new SAXBuilder();
Document document = saxBuilder.build(in);
//获取xml文档的根节点
Element root = document.getRootElement();
// 获取根节点下的所有子节点
List<Element> childrens = root.getChildren();
// 遍历子节点
for (Element children : childrens) {
Child child = new Child();
child.setId(children.getAttributeValue("id"));
Element element = children.getChild("age");
Element element1 = children.getChild("height");
child.setAge(Integer.parseInt(element.getText()));
child.setHeight(Integer.parseInt(element1.getText()));
list.add(child);
}
System.out.println(list);
} catch (IOException | JDOMException e) {
e.printStackTrace();
}
}
} 四、DOM4j解析
dom4j是一款基于Java性能最好的xml解析工具,它使用接口和抽象类等方法来完成xml文件解析,因此,这个工具大家需要掌握。
操作步骤:
1. 创建Document对象
// 1. 读取XML文件,获得document对象
SAXReader reader = new SAXReader();
Document document = reader.read(in);
// 2. 解析xml报文
Document document = DocumentHelper.parseText("");
// 3. 主动创建document,主要用来生成XML文件的
Document document = DocumentHelper.createDocument(); 2. 获取元素节点Element
1. 获取文档的根节点.
Element root = document.getRootElement();
2. 取得某个节点的子节点.
Element element=node.element("age");
3. 取得节点的内容
String text=node.getText();
4. 取得某节点下所有名为"age"的子节点,并进行遍历.
List nodes = rootElm.elements("age");
for (Iterator it = nodes.iterator(); it.hasNext();) {
Element elm = (Element) it.next();
}
5. 对某节点下的所有子节点进行遍历.
for(Iterator it=root.elementIterator();it.hasNext();){
Element element = (Element) it.next();
}
6. 在某节点下添加子节点
Element elm = newElm.addElement("朝代");
7. 设置节点文字. elm.setText("明朝");
8. 删除某节点.//childElement是待删除的节点,parentElement是其父节点 parentElement.remove(childElment);
9. 添加一个CDATA节点.Element contentElm = infoElm.addElement("content");contentElm.addCDATA(“cdata区域”); 3. 获取节点中的属性Attributes
1.取得某节点下的某属性
Element root=document.getRootElement();//属性名name
Attribute attribute=root.attribute("id");
2.取得属性的文字
String text=attribute.getText();
3.删除某属性
Attribute attribute=root.attribute("size"); root.remove(attribute);
4.遍历某节点的所有属性
Element root=document.getRootElement();
for(Iterator it=root.attributeIterator();it.hasNext();){
Attribute attribute = (Attribute) it.next();
String text=attribute.getText();
System.out.println(text);
}
5.设置某节点的属性和文字. newMemberElm.addAttribute("name", "sitinspring");
6.设置属性的文字 Attribute attribute=root.attribute("name"); attribute.setText("csdn"); 测试:
XML报文:
<?xml version="1.0" encoding="UTF-8" ?>
<father id="张大">
<child id="张三">
<age>18</age>
<height>172</height>
</child>
<child id="张四">
<age>19</age>
<height>173</height>
</child>
</father>
public class Dom4jTest {
private static InputStream in;
static {
in = Dom4jTest.class.getResourceAsStream("/test.xml");
}
@Test
public void test() {
SAXReader reader = new SAXReader();
//解析xml报文
try {
Document document = reader.read(in);
Element rootElement = document.getRootElement();
Iterator it = rootElement.elementIterator();
while (it.hasNext()) {
Element element = (Element) it.next();
List<Attribute> attributes = element.attributes();
for (Attribute attr : attributes) {
System.out.println("节点名:" + attr.getName() + ",节点值:" + attr.getValue());
}
for(Iterator iterator = element.elementIterator(); iterator.hasNext();){
Element childElement = (Element)iterator.next();
if ("age".equals(childElement.getName())){
System.out.println("age = " + childElement.getText());
}
if ("height".equals(childElement.getName())){
System.out.println("height = " + childElement.getText());
}
}
}
} catch (DocumentException e) {
e.printStackTrace();
} finally {
if (in != null){
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
输出:
节点名:id,节点值:张三
age = 18
height = 172
节点名:id,节点值:张四
age = 19
height = 173 

