读过Java并发包JUC的同学都知道,如果不理解volatile关键字的含义和CAS机制,好多知识点都非常的模糊,根本体会不了JUC的精髓,在JUC中大部分都是利用volatile关键字+CAS在不用锁的情况来保证 线程安全 的,但是volatile和CAS又是那么的抽象,刚接触Java的开发人员完全弄不懂volatile到底是干什么用的,不明白CAS是怎样保证在不加锁的情况下能够线程安全的,导致在读并发包的每一个类中都是非常的吃力,在全面分析JUC之前,我通过本篇文章把这两个知识点给大家一个清晰的解析,只有掌握了关键字volatile和CAS机制,你才能对JUC包有一个彻底的理解。此篇文章内容较长,但是如果你想学好Java的并发包,必须学会这两个知识点,我是一个一个字敲出来的,也请您一个一个字仔细读一下,详细读完后会有很好的收获。
本篇文章的主要内容:
1:Java内存模型(JMM)可见性的问题 2:Java内存模型(JMM)的重排序的问题 3:Java原子性的问题 4:关键字volatile 5:CAS机制
一、Java的内存模型JMM
1.1、Java的内存模型(JMM)
要想彻底明白volatile到底是干什么的,你必须知道Java的内存模型(JMM)。网上有很多关于对JMM定义的描述,如果我在按照他们的列出来,那么这一篇文章就变了味道,所以我用自己理解的去阐述Java内存模型,不会用长篇大论去介绍概念,而是依据例子去阐述,我觉得更有意义。
我们知道,共享变量属于所有的 线程 共享的,为了提高性能,每一个线程都会保存一份共享变量的副本,就是说每一个线程都会从 主存 中复制一份共享变量到自己的工作内存中去。举例说明:
有一个全局变量count=0,线程1和线程2同时将count+1
上面是一个非常简单的例子,如果对JMM不熟悉的同学很容易脱口而出最终结果为2,但是在 多线程 下的环境下真的就是我们期望的结果吗?答案是不一定,可能就会出现不同的现象了。
第一个现象:线程1首先获取到CPU的执行权 ,如下图

1:线程1首先获取CPU的执行权,所以从主存中获取count=0,然后复制一份到自己的工作内存中去。 2:线程1将工作内存中的count+1,此时工作内存count=1,还未来得及刷新到主存中,这时线程2获取了CPU的执行权 3:线程2获取CPU的执行权,所以也从主存中获取count=0,然后复制一份到自己的工作内存中去。 4:线程2将工作内存中的count+1,此时工作内存count=1。 5:是线程1首先刷新到主存中,还是线程2首先刷新到主存中,这个不确定。
上面线程1和线程2两个线程的工作内存的count都是1,但是它们什么时候刷新到主存中,无法确定,可能是线程1首先将count=1刷新到主存中,也可能是线程2首先将count=1刷新到主存中,不管哪一个线程首先将它的工作内存中count刷新到主存中,那此时主存也会count=1,这个结果与我们想象的不一样。
第二个现象:线程2首先获取到CPU的执行权 ,如下图:
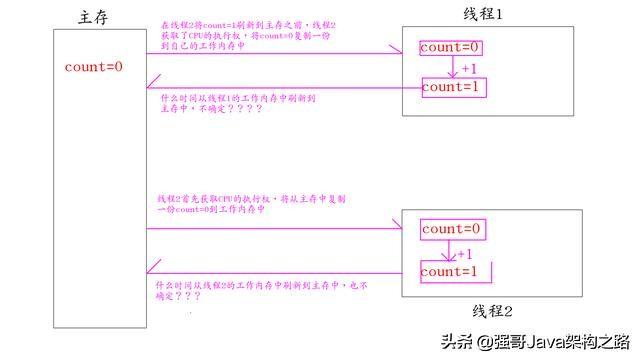
1:线程2首先获取CPU的执行权,所以从主存中获取count=0,然后保存到自己的工作内存中 2:线程2的count副本+1,此时count=1,但是还未来得及刷新到主存中,线程1获取了CPU的执行权。 3:线程1获取CPU执行权后,会从主存中拷贝一份count=0,到自己的工作内存中去。 4:线程1的count副本+1,此时count=1. 5:是线程2首先刷新到主存中,还是线程1首先刷新到主存中,这个不确定
上面两种现象不管是线程1首先获取CPU执行权,还是线程2获取CPU执行权,最终的结果是一样的,那就是count=1。这个结果并不是我们要的结果, 导致出现这个结果的原因就是并不知道工作内存中的值什么时间才会刷新到主存中去
第三种现象:线程1首先获取到CPU执行权,然后count+1,并刷新到主存中后线程2才获取CPU的执行权。 如下图:

1:线程1首先获取CPU的执行权,从主存中复制一份count=0到自己的工作内存中去。 2:线程1将工作内存的count+1,此时count=1 3:在线程2获取CPU执行权之前,线程1就将自己工作内存count=1刷新到主存中去。 4:此时主存中的count=1 5:线程2获取CPU的执行权,从主存中复制一份count=1到自己的工作内存中去。 6:线程2将工作内存count+1,此时count=2 7:在适当的某个时候,线程2把count=2刷新到主存中去。
第四种线程:线程2首先获取到CPU的执行权,然后count+1,并刷新到主存中后线程1才获取到CPU的执行权 。如下图:

1:线程2首先获取CPU的执行权,从主存中复制一份count=0到自己的工作内存中。 2:线程2将工作内存中count+1,此时count=1 3:在线程1获取CPU之前,线程2将工作内存count=1刷新到主存中 4:此时主存中的count=1 5:线程1说去CPU的执行权,从主存中复制一份count=1到工作内存中。 6:线程1将工作内存中的count+1,此时count=2 7:在适当的某个时候,线程1把count=2刷新到主存中去。
第三个和第四个现象是我们想要的结果,当另一个线程获取CPU执行权之前,前一个线程已经把修改的count刷新到主存中去了。
通过上面的四个现象,我们可以总结如下特点:
1:线程不能直接操作主存中的共享变量,而是复制一份副本到自己的工作内存,并对这个副本进行操作。 2:每个线程对副本的修改,在刷新到主存之前,其他线程是看不到的。 3:每个线程对工作内存中的副本进行修改后,至于什么时候刷新到主存中,这个不确定。
从上面的一个实例中引出了JMM的可见性问题,在并发情况下,一个线程对共享变量的修改可能对其他线程并不可见,导致计算的值和我们想象的不一致,所以在多线程下,要想线程安全必须要解决可见性的问题。
二、Java内存模型的重排序问题
上面我们说了多线程并发修改共享变量可能会出现可见性的问题,为了性能,Java内存模型可能对代码进行重排序,这种重排序在单线程下不会影响最终的结果,但是在多线程下就会出现问题.
举例1:
有3个变量: int a = 0; int b = 1; int c = 2;
上面这3个变量既没有 数据依赖 ,也没有 控制依赖 ,所以为了提高性能,编译器可能对这3段代码进行重排序,代码的执行结果有以下几种情况:
第一种情况:a->b->c 第二种情况:a->c->b 第三种情况:b->a->c 第四种情况:b->c->a 第五种情况:c->a->b 第六种情况:c->b->a
这种重排序在单线程下不会影响最终的结果,但是在多线程情况下就存在不确定因素了。
刚才我提到了数据依赖和控制依赖,那这两种是什么情况呢?解释如下:
数据依赖性:写后读、写后写、读后写
第一种:写后读,例如:int a = 1;int b = a; 第二种:写后写,例如:int a = 1;a = 2; 第三种:读后写,例如:int a = b; b=1;
上面三种情况都存在数据依赖性,如果对它们进行重排序,会导致结果错误,所以编译器不会对它们进行重排序,在单线程情况下结果是正确的,但是在多线程情况下可能就有问题了。
举例如下:
class MyTest1{
private int a = 0;
private int b = 0;
public void test1(){
a = 1;//$1
}
public void test2(){
b = a;//$2
}
public int getA() {
return a;
}
public int getB() {
return b;
}
}
class Test{
public static void main(String[] args) throws InterruptedException {
MyTest1 mt = new MyTest1();
CountDownLatch cd = new CountDownLatch(1);
CountDownLatch cd1 = new CountDownLatch(2);
new Thread(()->{
try {
cd.await();
mt.test1();
cd1.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
new Thread(()->{
try {
cd.await();
mt.test1();
cd1.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
cd.countDown();
cd1.await();
System.out.println("a="+mt.getA());
System.out.println("b="+mt.getB());
}
}
上面的CountDownLatch是并发包的一个类,大家先理解能够为能够使一个或这多个线程等待其他线程完成后在执行就可以了,上面这个代码线程1执行test1(),线程2执行test2().那最终结果会怎样的?
第一种结果:
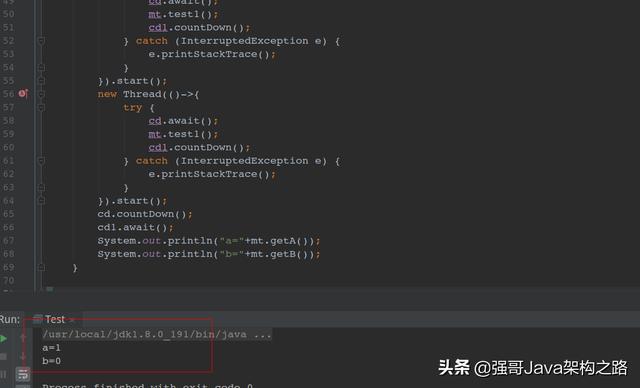
第二种结果:

上面两种执行结果不同,说明在多线程下,数据依赖虽然保证单线程结果正确,但是在多线程下就有不确定因素了。
数据依赖:
int a = 1;
int b = a;
变量b依赖变量a的结果,所以编译器不会对这两行代码进行重排序。
-------------------------------------------------
控制依赖:
int a = 0;
boolean b = false
public void test1(){
a=1;//$1
b=true;//$2
}
if(b){//$3
int c = a+a;//$4
}
上面的操作$3和操作$4就存在控制依赖了。
当程序中存在控制依赖时,会影响指令序列执行的并行度,编译器通过猜测来克服这个问题,线程2可以提前读取并计算a+a,然后把结果保存到一个名为重排序缓冲中。当$3中b==true时,就把结果写入到c中,但是在单线程下虽然可以重排序,但是不会破坏结果,但是在多线程下就不一定了。
举例说明如下:
class MyTest{
private int a = 0;
private boolean b = false;
private int c = 0;
public void test1(){
a = 1;//$1
b = true;//$2
}
public void test2(){
if(b){//$3
c = a+a;//$4
}
}
public int getA() {
return a;
}
public boolean isB() {
return b;
}
public int getC() {
return c;
}
}
class Test{
public static void main(String[] args) throws InterruptedException {
MyTest mt = new MyTest();
CountDownLatch cd = new CountDownLatch(1);
CountDownLatch cd1 = new CountDownLatch(2);
new Thread(()->{
try {
cd.await();
mt.test1();
cd1.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
new Thread(()->{
try {
cd.await();
mt.test1();
cd1.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
cd.countDown();
cd1.await();
System.out.println("a="+mt.getA());
System.out.println("b="+mt.getB());
}
}
第一种执行结果:
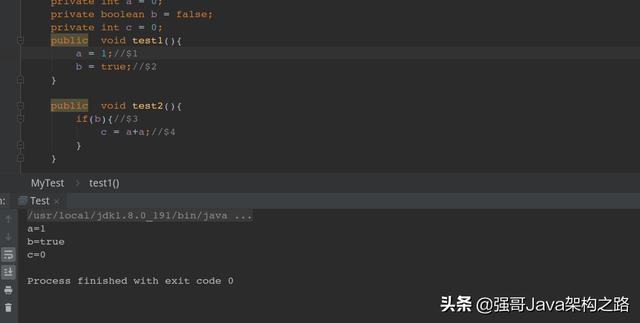
第二种执行结果:
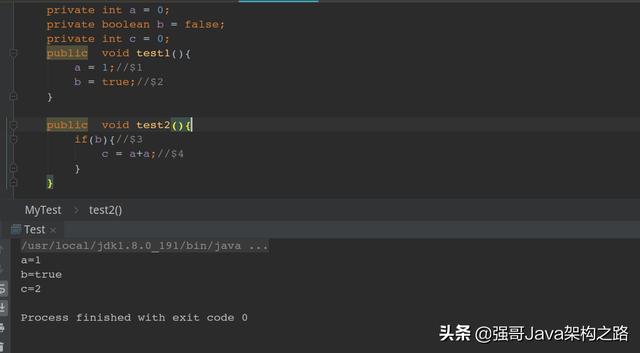
通过上面的讲解,我们知道了为了提高性能,在单线程下的重排序不会影响结果,但是在多线程下结果就不确定了。所以在多线程下如果要想保证线程安全,需要对有序性进行保证,禁止指令重排序。
三、Java原子性的问题
要想在多线程下安全的修改一个共享变量,保证可见性和有序性的同时,也要保证原子性,就是一个操作是不可分的,必须是连续的,要么成功,要么失败,例如i++这种操作就不是连续的,它包含以下几个操作:
1:读:首先读取i 2:改:将i进行++ 3:写:然后写修改后的值写入
可以看出上面的一个i++操作涉及到3个内容,它不符合原子行不可分割的特点,这样在多线程情况下就有不确定的因素了,所以如果只保证可见性和有序性,不保证原子性仍无法保证线程安全。
通过上面的讲解,我们知道要想保证线程安全,必须符合 可见性、有序性、原子性 三个特点,那么在Java中是怎样去保证这三个特点的呢?大家很容易会想到加锁,这种想法是完全正确的,关于锁的知识点,本篇文章不会涉及到,我会用大量的篇幅对锁进行分析,这一篇文章我们看看通过关键字volatile和CAS来保证线程安全的。
四、关键字volatile
首先我先写出来关键字volatile的作用,如下:
1:volatile能保证可见性 2:volatile能保证有序性
上面我列出了volatile的作用,但是可以看出来volatile并不保证原子性,接下来我开始分析它是怎样保证可见性和有序性的。在分析之前总结volatile的特点
1:任何对volatile变量的写,JMM会立刻把工作内存的值被刷新到主存中 2:任何对volatile变量的读,都会从主存中拷贝一份最新的数据到自己的工作内存中去。
我还是用举例的方法来解释上面的两个特点:
假设有一个成员变量:
private volatile int a = 0;
//$1:表示任何对volatile的写,JMM会立刻把值刷新到主存中
public void write(){
a = 1;
}
//$2:表示任何对volatile的读,JMM会把当前线程的工作内存对应的副本置为无效,然后从主存中读取一份。
public void read(){
int b = a;
}
假设线程1首先执行write()方法,然后线程2执行read()方法。
$1用图表示如下:

$2用图表示如下:
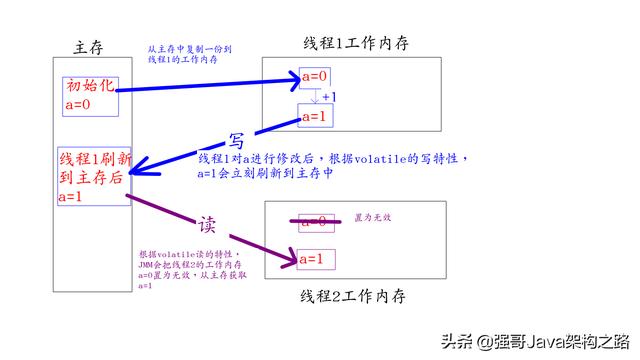
上面分析了volatile的写和读的特性,通过这个特性能够解决多线程下 可见性 的问题,volatile除了能解决可见性的问题,同时也能禁止指令重排序,它是通过加如内存屏障来保证指令重排序的,从而能保证有序性,因为内存屏障牵涉到JVM的一些特性,这里就不在展开讲了,如果有机会,我会有一个专题用来介绍JVM,到那时我会着重讲解以下,这里只是让大家了解以下volatile既能保证可见性又能保证有序性。
讲到这,大家思考以下volatile能保证线程安全吗?以我的感觉,这个不一定。
1:如果是对单个变量的读或者写,能够保证线程安全,也可以认为volatile具有原子性。 2:如果是复合操作,比如i++,这种就保证不了原子性了,从而也无法保证线程安全。
所以volatile只能保证可见性和有序性,并不能保证原子性,对单个变量的操作能保证原子性,只是一个特殊而已,并不能说volatile就具有原子性,所以只利用volatile去保证线程安全是远远不够的,还需要一个方法去保证原子性,这样才能复合线程安全的特性,进而才能保证多线程下对共享变量的安全操作。那怎样才能保证原子性呢?请继续看下面的CAS机制。
五、CAS机制
上面讲解了volatile拥有了线程安全的两个特性,但是缺少原子性,所以无法保证线程安全,那么CAS的出现就是解决原子性的问题的。
CAS是compare and swap的简写,从字面上理解就是比较和交换。它的定义如下:
CAS(V,E,N) V:表示要更改的变量 E:表示变量的预期值 N:表示变量要更新的新值
它的原理就是通过比较预期值E和当前V的真正值是否相同,如果相同,则更新为N,如果不相同,则自旋判断,直到更新成功为止。 它的流程图如下:

CAS能够保证对一个变量的原子操作,CPU能够保证这种原子操作,在Java中Unsafe对CAS进行了封装。
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5); --------------------------------- public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5); ------------------------------------- public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
上面只是简单的介绍了CAS是干什么的,CAS能够保证对一个变量的原子操作,它的一些概念和深入的地方就不在阐述了。
上面通过对JMM的介绍,从而引出了多线程安全的3个特性: 原子性、可见性、有序性 ,也可通过关键字volatile+CAS来保证对一个变量的安全操作,并发包JUC中大部分都是利用这种机制处理的,如果你学会了,那接下来的并发包中的内容就很容易理解了。接下来我们就一起进入并发包的学习。


