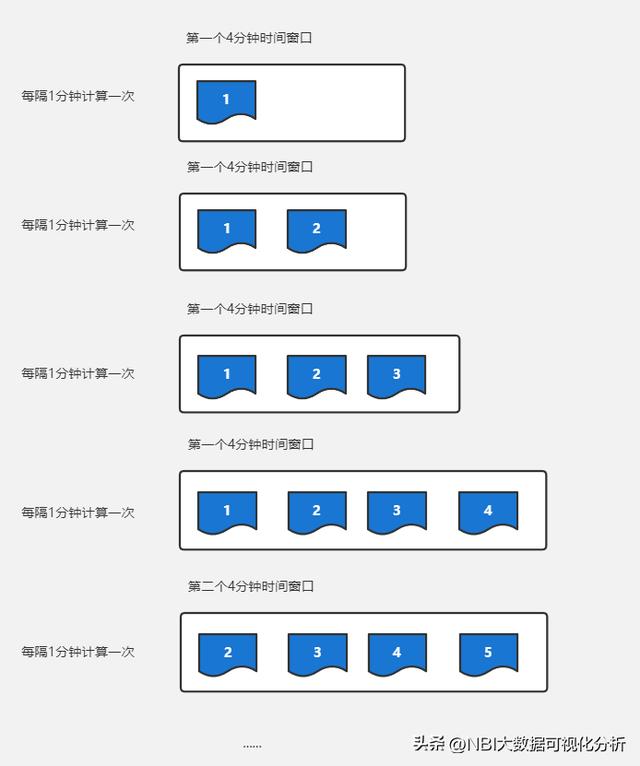
一、滚动窗口(Tumbling Windows) 滚动窗口有固定的大小,是一种对数据进行均匀切片的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有一个,就是窗口的大小(window size)。

在 spark streaming中,滚动窗口需要设置窗口大小和滑动间隔,窗口大小和滑动间隔都是StreamingContext的间隔时间的倍数,同时窗口大小和滑动间隔相等,如:
.window(Seconds(10),Seconds(10)) 10秒的窗口大小和10秒的滑动大小,不存在重叠部分
package com.examples;
import com.pojo.WaterSensor;
import org.apache. Spark .SparkConf;
import org.apache.spark.api. Java .JavaRDD;
import org.apache.spark.api.java. Function .Function;
import org.apache.spark.api.java.function. void Function2;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.Time;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
/**
* Created by lj on 2022-07-12.
*/
public class SparkSql_ socket _Tumble {
private static String appName = "spark.streaming.demo";
private static String master = "local[*]";
private static String host = "localhost";
private static int port = 9999;
public static void main(String[] args) {
//初始化sparkConf
SparkConf sparkConf = new SparkConf().setMaster(master).setAppName(appName);
//获得JavaStreamingContext
java StreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.minutes(1));
/**
* 设置日志的级别: 避免日志重复
*/
ssc.sparkContext().setLogLevel("ERROR");
//从socket源获取数据
JavaReceiverInputDStream<String> lines = ssc.socketTextStream(host, port);
JavaDStream<WaterSensor> mapDStream = lines.map(new Function<String, WaterSensor>() {
private static final long serialVersionUID = 1L;
public WaterSensor call(String s) throws Exception {
String[] cols = s.split(",");
WaterSensor waterSensor = new WaterSensor(cols[0], Long.parseLong(cols[1]), Integer .parseInt(cols[2]));
return waterSensor;
}
}).window(Durations.minutes(3), Durations.minutes(3)); //滚动窗口:需要设置窗口大小和滑动间隔,窗口大小和滑动间隔都是StreamingContext的间隔时间的倍数,同时窗口大小和滑动间隔相等。
mapDStream.foreachRDD(new VoidFunction2<JavaRDD<WaterSensor>, Time>() {
@Override
public void call(JavaRDD<WaterSensor> waterSensorJavaRDD, Time time) throws Exception {
SparkSession spark = JavaSparkSessionSingleton. getInstance (waterSensorJavaRDD.context().getConf());
Dataset <Row> dataFrame = spark.createDataFrame(waterSensorJavaRDD, WaterSensor.class);
// 创建临时表
dataFrame.createOrReplaceTempView("log");
Dataset<Row> result = spark.sql("select * from log");
System.out.println("========= " + time + "=========");
//输出前20条数据
result.show();
}
});
//开始作业
ssc.start();
try {
ssc.awaitTermination();
} catch (Exception e) {
e.printStackTrace();
} finally {
ssc.close();
}
}
}
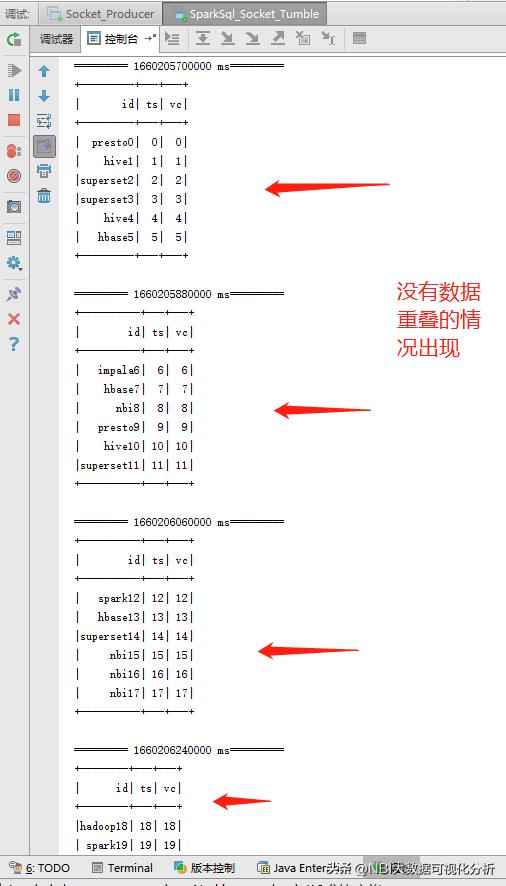
代码中定义了一个3分钟的时间窗口和3分钟的滑动大小,运行结果可以看出数据没有出现重叠,实现了滚动窗口的效果:
二、滑动窗口(Sliding Windows)与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。如果看作一个窗口的运动,那么就像是向前小步“滑动”一样。定义滑动窗口的参数有两个:除去窗口大小(window size)之外,还有一个滑动步长(window slide),代表窗口计算的频率。
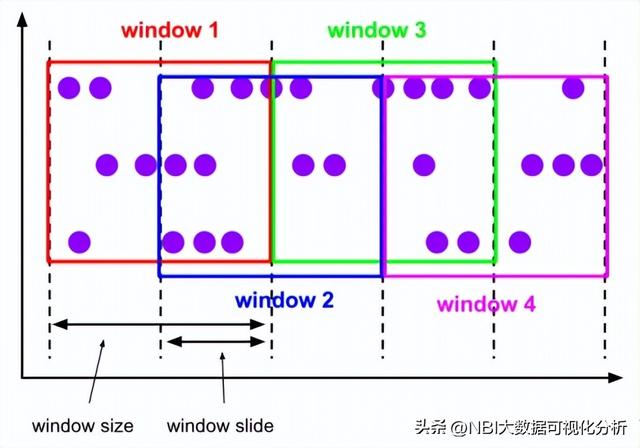
在sparkstreaming中,滑动窗口需要设置窗口大小和滑动间隔,窗口大小和滑动间隔都是StreamingContext的间隔时间的倍数,同时窗口大小和滑动间隔不相等,如:
.window(Seconds(10),Seconds(5)) 10秒的窗口大小和5秒的活动大小,存在重叠部分
package com.examples;
import com.pojo.WaterSensor;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.*;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.Time;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import java.util.ArrayList;
import java.util.List;
/**
* Created by lj on 2022-07-12.
*/
public class SparkSql_Socket {
private static String appName = "spark.streaming.demo";
private static String master = "local[*]";
private static String host = "localhost";
private static int port = 9999;
public static void main(String[] args) {
//初始化sparkConf
SparkConf sparkConf = new SparkConf().setMaster(master).setAppName(appName);
//获得JavaStreamingContext
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.minutes(1));
/**
* 设置日志的级别: 避免日志重复
*/
ssc.sparkContext().setLogLevel("ERROR");
//从socket源获取数据
JavaReceiverInputDStream<String> lines = ssc.socketTextStream(host, port);
JavaDStream<WaterSensor> mapDStream = lines.map(new Function<String, WaterSensor>() {
private static final long serialVersionUID = 1L;
public WaterSensor call(String s) throws Exception {
String[] cols = s.split(",");
WaterSensor waterSensor = new WaterSensor(cols[0], Long.parseLong(cols[1]), Integer.parseInt(cols[2]));
return waterSensor;
}
}).window(Durations.minutes(4), Durations.minutes(2)); //滑动窗口:指定窗口大小 和 滑动频率 必须是批处理时间的整数倍
mapDStream.foreachRDD(new VoidFunction2<JavaRDD<WaterSensor>, Time>() {
@Override
public void call(JavaRDD<WaterSensor> waterSensorJavaRDD, Time time) throws Exception {
SparkSession spark = JavaSparkSessionSingleton.getInstance(waterSensorJavaRDD.context().getConf());
Dataset<Row> dataFrame = spark.createDataFrame(waterSensorJavaRDD, WaterSensor.class);
// 创建临时表
dataFrame.createOrReplaceTempView("log");
Dataset<Row> result = spark.sql("select * from log");
System.out.println("========= " + time + "=========");
//输出前20条数据
result.show();
}
});
//开始作业
ssc.start();
try {
ssc.awaitTermination();
} catch (Exception e) {
e.printStackTrace();
} finally {
ssc.close();
}
}
}
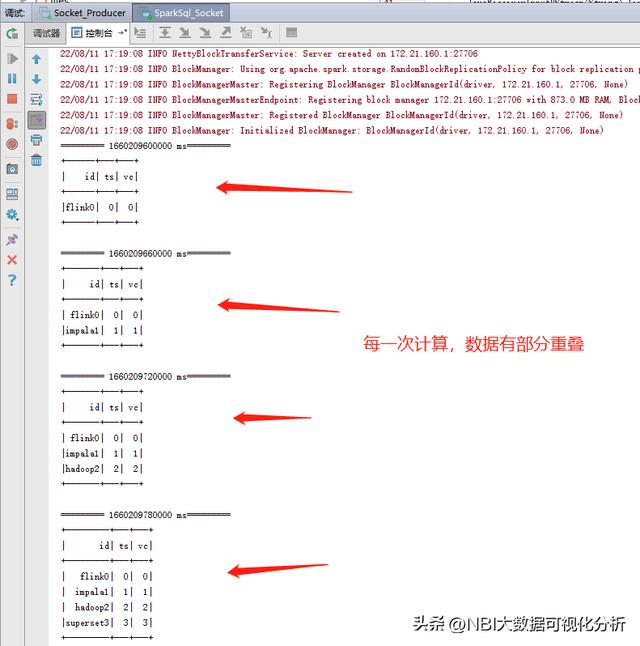
数据演进过程解释: