
1、概述
Spark早期版本时,MLlib是基于RDD来进行分析的,其使用的是 spark. mllib包。而言2.0版本后,由RDD这种抽象数据结构转换到了基于 dataframe上,其相关API也被封装到了 spark.ml包下。而在 spark MLlib/ML中为了方便数据的整理和分析,将存储数据的格式转化为 向量 和 矩阵 进行存储和计算,以便将数据定量化。
1.1 向量和矩阵的概念
向量:类比于数学中的概念,在spark中可以将其理解为由一维数组刻画的数据模型;
矩阵:是由行和列组成的数据类型,是由多组向量构成的,较向量而言计算效率更高。
1.2 向量和矩阵的应用场景
向量:标签向量因其带有标记,常被用在监督学习算法中,如回归( Regression)和分类( Classification)等。
矩阵:以向量为基础,可以用来处理更多的数据,可以应用于回归预测,协同过等算法中。
2、Spark中的使用说明
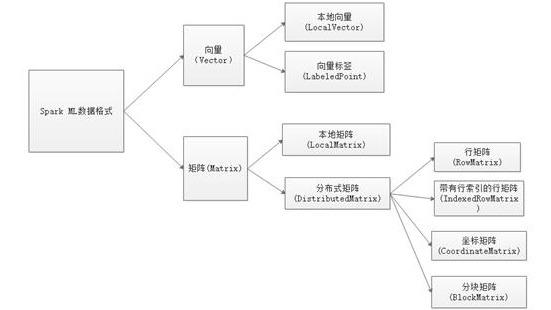
Spark MLlib使用的数据格式类型是矩阵和向量,而两者又可以分为本地向量,向量标签,本地矩阵, 分布式 矩阵,其中,分布式矩阵又可以细分为行矩阵,带有索引的行矩阵,坐标矩阵和分块矩阵。
2.1 本地向量(LocalVector
本地化向量集主要由稀疏型数据集(sparse)和密集型数据集(dense),而两者是基于数组(Array)的向量的顶级接囗是 Vector。两者主要区别如下:
密集型数据集的数值数组中的元素类型为 double 类型;
稀疏性数据集的向量格式由索引(下标)数组和数值数组组成,其中,索引的类型为整型,数组元素的类型仍旧为double双精度类型, 密集型数据简而言之就是每个索引位置都有数值,而稀疏型矩阵则是可以只在特定位置有数值。
创建密集型数据集的方式:
//创建一个密集型向量,官方推荐使用Vectors工厂方式创建
Vector v = Vectors.dense(1.0,2.0,3.0);
//第二种创建方
Vector v2 = Vectors.dense(new double[] {1.0, 2.0 3.0});
创建稀疏型索引的方式:
//创建一个稀疏型索引,参数一表示向量最多可以存9个数据,参数二表示给定的索引,
//该例中给定的索引是0和2,没有给定1,参数三便是给定的数据,这里的数据是1.0和2.0,
//索引个数和元素的个数要严格一致,且索引要呈现递增趋势
Vector v1 = Vectors.sparse(9,new int[]{0,2},new double[]{8.0,2.0});
2.2 向量标签( LabeledPoint)
向量标签,是一种基于密集型向量和稀疏型向量而额外给定一个标签(Label)的类型,这些统称为一个标记点。这些标签点的设置是有用户自己给定的,标记常用double类型的数据予以给定,这些值的给定是对数据进行标记,目的是为了分类和回归算法中的应用。简单理解就是一个向量组会对应的一个特殊值,但是这些标记值是可以重复的。
创建密集型向量标签的方式:
//创建一个带有标记点的密集型数据 LabeledPoint pos = new LabeledPoint(1.0, Vectors.dense(1.0, 2.0,3.0));
创建稀疏型向量标签的方式:
//创建一个带有标记点的稀疏型数据:
LabeledPoint neg = new LabeledPoint(0.0, Vectors.sparse(3, new int[]{0,2},new double[]{1.0,2.5}));
另外,Spak还提供了一种读取特定文件格式的方式来获取标签向量:
//使用外来文件(格式需要符合LIBSVM)创建labeledPoint //使用该API需要注意下面几点: 1)、文件格式必须符合LIBSVM要求:label index1:value1 index2:value2 2)、其中的label可以相同,但是index必须保证唯一性, 3)、index是从0开始的,且必须呈现出递增的趋势 4)、若其中index2的value值为0,则可以不写,那么index1和index2的数据就可以写为index1:value1 index3:value3 JavaRDD<LabeledPoint> examples = MLUtils.loadLibSVMFile(jsc.sc(),"src/main/resources/labeled.txt").tpJavaRDD();
2.3 本地矩阵(LocalMatrix)
同样矩阵也分为集型矩阵和稀型矩阵,推荐使用工厂方法 Matrices来创建,需要额外注意的是矩阵是以列为优先存储的,简单而言,对于一组数据,会优先墳充列值,再埴充行值。对于密集型矩阵,数据类型为数组,元素类型为 double:但与向量不同的是,矩阵需要指定行和列:对于稀疏型矩阵,数据类型为 double,采用的是CSC格式(一种存储稀疏教据的矩阵方式)。
创建密集向矩阵的方式:
//创建一个密集型矩阵,明确指定行为3,列为2
Matrix dm = Matrices dense(3, 2, new double[]{1.0, 2.0, 3.0,4.0,5.0, 6.0});
//打印出的格式是:
//1.0 4.0
//2.0 5.0
//3.0 6.0
//这表明使用给定的数据,矩阵会优先进行列的存储
创建稀疏型矩阵的方式:
//创建一个稀疏型矩阵,spark使用的是CSC格式的稀疏矩阵
//①参是指定矩阵的行
//②参是指定矩阵的列
//③参,其元素的个数的矩阵的列数加1,该例矩阵的列数为2,则该参数个数有3个,
//且该数组中的第一个元素一直是0,第二个元素是第一列的非零元素的数量,
//后续的值为前一个元素的值加上下一列非零元素的数量
Matrix sm= Matrices. sparse(3, 2, new int[] {0, 1, 3}, new int[] {0, 2, 3}, new double[] {9, 6, 8});
2.4 分布式矩阵(DistributedMatrix)
分布式矩阵,见名知意,采用的是分布式架构处理教据,因此分布式矩阵存储的数据量是非常大的。其处理速度和选用的存储格式有关,mblib提供了4中分布式矩阵存储格式,行和列均是Long类型,而存储的数据内容是 double类型。这4种矩阵分别是行矩阵,带有行索引的行矩阵,坐标矩阵和分块矩阵。应用比较广泛的是带有行索引的行矩阵和坐标矩阵。
2.4.1 行矩阵(RowMatrix)
行矩阵是分布式矩阵下的最基本的矩阵类型,行矩阵是以行作为基本方向的矩阵存储格式,列的作用相对较小,可以将其理解为行矩阵是一个巨大的特征向量的集合,每行就是具有相同格式的向量数据,且每一行的向量内容是可以单独取出来进行操作的。但是不能按照行号访问。
创建行矩阵的格式如下:
SparkConf conf = new SparkConf().setMaster(“local”).setAppName(“DistributedMatrixRowMatrix”); JavaSparkContext jsc = new JavaSparkContext(conf); JavaRDD<Vector> rows = jsc.parallelize(Arrays.asList(Vectors.dense(4.0,5.0,6.0),Vectors.dense(2.0,12.0,6.0))); RowMatrix matrix = new RowMatrix(rows.rdd());
2.4.2带有索引的行矩阵( IndexedRowMatrix)
为了后续回归,分类等算法应用不同的 特征值 ,需要对不同的行向量打不同的标记点,因此可以为每一行向量打上能够代表该行的索引,素引是可以重复的,但类型为Long。
创建带有索引行的行矩阵的方式:
SparkConf conf = new SparkConf(). setMaster ("local").setAppName("DistributedMatrixIndexedRowMatrix");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<IndexedRow> rows = jsc.parallelize(Arrays.asList(new IndexedRow(1, Vectors. dense(1. 0, 2.3, 2.6)), new Indexed Row (2, Vectors.dense(1.0,2.3,50.6));
IndexedRow Matrix mat = new IndexedRowMatrix(rows. Rdd());
2.4.3 坐标矩阵(Coordinatematrix)
顾名思义,坐标矩阵就是给每个数据都用一组坐标进行标识,其类型格式为( x Long y Long, value: Double),这种矩阵的应用场一般是数据比较多且数据较为分散的情形下或者是矩阵维度比较大,即矩阵中含0或某个具体值较多的情况下。
创建坐标矩阵的格式如下:
SparkConf conf new SparkConfo. setMaster("local" ).setAppName("spark-standalone");
JavaSparkContext jsc = new JavaSparkContext(conf);
//创建一个坐标矩阵,如果两个value的坐标点相同,后者的数据会覆盖前者数据
JavaRDD<MatrixEntry> rows = jsc.parallelize(Arrays.asList(new MatrixEntry(0,0,1.0), new MatrixEntry (1,0,2.0)));
CoordinatMatrix mat = new CoordinateMatrix(rows.rdd());
2.4.4 分块矩阵( BlockMatrix)
分块矩阵是基于矩阵块构成的RDD的分布式矩阵,其中每个矩阵块部是一个元组((Int,Int) Matrix)其中( Int,Int)是块的索引,而Matrix是对应位置的子矩阵,其尺寸由 rowsPerBlock和 colPerBlock决央定,默认1024*1024,分块矩阵支持和另一个分块矩阵的加法和乘法,并提供了 validate()来判断分块矩阵是否创建成功,分块矩阵可以由索引行短阵和坐标矩阵调用 toBlockMatrix0方法获得,默认块的大小是1024*1024,也可使用 toBlockMatrix( rowsPerBlock, colPerBlock来调整分块的尺寸。
创建分块矩阵:
SparkConf conf new SparkConfo. setMaster("local" ).setAppName("spark-standalone");
JavaSparkContext jsc = new JavaSparkContext(conf);
//创建一个坐标矩阵,如果两个value的坐标点相同,后者的数据会覆盖前者数据
JavaRDD<MatrixEntry> rows = jsc.parallelize(Arrays.asList(new MatrixEntry(0,0,1.0), new MatrixEntry (1,0,2.0)));
CoordinatMatrix mat = new CoordinateMatrix(rows.rdd());
BlockMatrix matA = mat.toBlockMatrix().cache();
3、Spark中的实践
3.1 本地向量( Localvector)
//创建一个密集型向量,官方推荐用Vectors工厂模式创建
Vector v = Vectors. dense(5.0, 2.0,3.0);
//第二种创建方式
Vector v2= Vectors. dense(new double[] {1.0, 2.0, 3.0});
//获取指定下标元素的值
v.apply(0);
//获取最大的元素数值所在的索引
v.argmax();
//获取向量中元素的个数
v.size();
//转化为double[]
v.toArray();
//转化为一个稀疏型向量
v.toSparse();
//与另一个向量做比较,判断是否完全一致
v.equals(v2);
//转化为一个JSON格式的字符串
v.toString();
//创建一个密集型索引,表明给向量最多可以存9个数据,该例中给定的下标是0和2,没//有给定1,给定的数据是1.0和2.0,这里的索引个数要和元素的个数严格一致,且索引要
//呈现出递增趋势
Vector v1 = Vectors.sparse(9,new int[]{0,2},new double[]{8.0,2.0});
//在稀疏型矩阵中,获取的下标如果没有给定值,那么为0
v1.apply(0);
//获取向量中最大的值
v.agrmax();
//转为密集型向量
//结果为:[8.0,0.0,2.0,0.0,0.0,0.0,0.0,0.0,0.0]
v1.toDense();
3.2 向量标签( LabeledPoint)
SparkConf conf = new SparkConf().setMaster ("local").setAppName("LabeledpointDemo"); JavasparkContext jsc = new JavasparkContext(conf);
LabeledPoint pos= new LabeledPoint(1.0, Vectors. dense(1.0,2.0,3.0,5.9));
//获取向量数据-成为特征值
pos.features();
//获取标记
pos.label();
//将向量标签转化为String类型的数据
pos.toString();
//获取该向量标签中的元素
pos.productElement(0);
//获取该向量标签中的迭代集
pos.productIterator();
//创建一个带有标记点的稀疏型数据
LabeledPoint neg = new LabeledPoint(0. 0, Vectors. sparse(3, new int[](0, 2), new double[]{1.0, 2.5}));
//获取向量数据成为特征值
neg.features();
//获取标记值
neg.label();
//比较两个向量标签是否完全一致,要求标记点一致,对应的数据一致才判定为true
pos.equals(neg);
3.3 本地矩阵( LocalMatrix)
//创建一个密集型矩阵,明确指定行为3,列为2
Matrix dm = Matrices. dense(3,2, new double[]{1.0,2.0,3.0,4.0,5.0,6.0});
//打印出的数据格式为
//1.0 4.0
//2.0 5.0
//3.0 6.0
//这表明使用给定的数据,矩阵会优先进行列的存储
System. out.println(dm);
//依据(i,j)来获取数值,需要注意的是,在sparkMatrix中,起始下标为0,因此(2,1)拿到的是6.0
dm.apply(2,1);
//获取列式的一个向量迭代器,因为spark中的矩阵是以列进行优先存储的
Iterator<Vector> it =dm. colIter();
while(it.haxNext()){
System. out. println(it next();}
//获取行式的一个向量迭代器
dm.rowIter()
//获取该坐标对应数组中的索引位置
dm.index(2,1)
获取行数,列数等基本信息
dm.numRows();
dm.numCols();
//依据列来获得一个double[]数组
dm.toArray();
//更新一个位置的元素
dm, update(0,1,5.6);
3.4 分布式矩阵( DistributedMatrix)
3.4.1 行矩阵( RowMatrix)
SparkConf conf = new SparkConf().setMaster(“local”).setAppName(“DistributedMatrixRowMatrix”); JavaSparkContext jsc = new JavaSparkContext(conf); //建立行矩阵的前期是创建JavaRDD<Vector>,这里要用到的是MLlib包下的类 JavaRDD<Vector> rowd = jsc.parallize(Arrays.asList(Vectors.dense(4.0,8.0,6.0),Vectors.dense(12.0,2.0,3.0))); //从JavaRDD中可以单独提取出每一行向量 List<Vector> s = rows.take(1); //使用RowMatrix创建行矩阵 RowMatrix matrix = new RowMatrix(rows.rdd()); //获取行矩阵的行数 matrix.numRows(); //获取行矩阵的列数 matrix.numCols(); //计算各列的余弦相似性 matrix.columSimilarities(); //计算每列的统计信息,然后通过调用min,max,mean,count,normaL1,variance分别计算最大值,最小值,行数,L1范数(曼哈顿距离) MultivariateStatisticalSummary si = matrix.computeColumnSummaryStatistics(); si.min(); si.max(); si.mean(); si.count(); si.normaL1(); si.variance(); //计算每列之间的协方差,生成协方差矩阵 matrix.computeCovariance(); //计算QR分解 QRDecomposition<Matrix,Matrix> result = matrix.tallSkinnyQR(false); result.Q(); result.R(); //与另一个矩阵相乘 matrix.multiply(m2);
3.4.2 带有索引行的行矩阵(IndexedRowMatrix)
SparkConf conf = new SparkConf().setMaster(“local”).setAppName(“DistributedMatrixIndexedRowMatrix”); JavaSparkContext jsc = new JavaSparkContext(conf); //创建一个带有行索引的行矩阵 //在行矩阵的基础上,对每一行向量新增了一个Long类型的索引 JavaRDD<IndexedRow> rows = jsc.parallelize(Arrays.asList(new IndexedRow(1,Vectors.dense(1.0,2.3,2.6)))); IndexedRowMatrix mat = new IndexedRowMatrix(rows.rdd()); //获取矩阵的行数和列数 mat.numRows(); mat.numCols(); //计算每行之间的余弦相似度 mat.columSimilarities(); //转化为普通的行矩阵 mat.toRowMatrix(); //转化为块矩阵 mat.toBlockMatrix(); //转化为坐标矩阵 mat.toCoordinateMatrix();
3.4.3 坐标矩阵(CoordinateMatrix)
SparkConf conf = new SparkConf().setMaster(“local”).setAppName("DistributedCoordinateMatrix");
JavaSparkContext jsc = new JavaSparkContext(conf);
//创建一个坐标矩阵,如果两个value的坐标点相同,则后者的数据会覆盖前者数据
JavaRDD<MatrixEntry> entries = jsc.parallelize(Arrays.asList(new MatrixEntry(0,0,1.0),new MatrixEntry(1,0,2.0)));
CoordinateMatrix mat = new CoordinatMatrix(entries.rdd());
//获取矩阵的行数和列数
mat.numRows();
mat.numCols();
//转化为带有行索引的行矩阵,会将坐标矩阵中的列值作为索引
//但是要保证列值的大小要小于Integer.MAX_VALUE
mat.toIndexedRowMatrix();
//转化为行矩阵,是先将其转化为带有行索引的行矩阵再将其转化为行矩阵
mat.toRowMatrix();
//将矩阵转置
mat.transpose();
3.4.4 分块矩阵(BlockMatrix)
SparkConf conf = new SparkConf().setMaster(“local”).setAppName("DistributedBlockMatrix");
JavaSparkContext jsc = new JavaSparkContext(conf);
//创建块矩阵一般是通过坐标矩阵来创建的
JavaRDD<MatrixEntry> entries = jsc.parallelize(Arrays.asList(new MatrixEntry(0,0,1.0),new MatrixEntry(1,0,2.0)));
CoordinateMatrix coormat = new CoordinatMatrix(entries.rdd());
//通过坐标矩阵来转化为块矩阵
BlockMatrix mat = coormat.toBlockMatrix().cache();
//检查创建块矩阵是否成功,成功则无反应,失败则抛出异常
mat.validate();
//在原有矩阵的基础上,拼接一个新的块矩阵
mat.add(matA);
//获取块矩阵的行数和列数
mat.numRows();
mat.numCols();
//获取块矩阵的块的列数(将一个分块视为一个单位列)
mat.numColBlocks();
//获取分块矩阵的块的行数
mat.numRowBlocks();
3.4.4 分块矩阵(BlockMatrix)
SparkConf conf = new SparkConf().setMaster(“local”).setAppName("DistributedBlockMatrix");
JavaSparkContext jsc = new JavaSparkContext(conf);
//创建块矩阵一般是通过坐标矩阵来创建的
JavaRDD<MatrixEntry> entries = jsc.parallelize(Arrays.asList(new MatrixEntry(0,0,1.0),new MatrixEntry(1,0,2.0)));
CoordinateMatrix coormat = new CoordinatMatrix(entries.rdd());
//通过坐标矩阵来转化为块矩阵
BlockMatrix mat = coormat.toBlockMatrix().cache();
//检查创建块矩阵是否成功,成功则无反应,失败则抛出异常
mat.validate();
//在原有矩阵的基础上,拼接一个新的块矩阵
mat.add(matA);
//获取块矩阵的行数和列数
mat.numRows();
mat.numCols();
//获取块矩阵的块的列数(将一个分块视为一个单位列)
mat.numColBlocks();
//获取分块矩阵的块的行数
mat.numRowBlocks();



