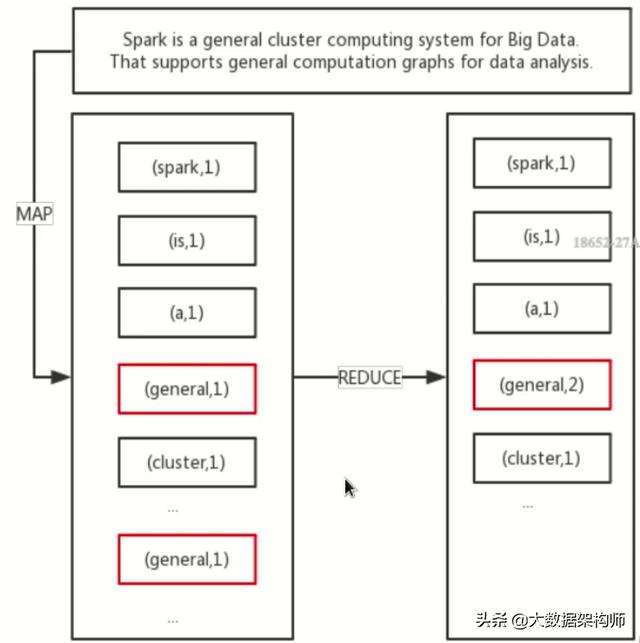
实战:基于Spark词频统计
下面,我们将演示基于 spark 框架来实现词频统计功能。
项目概述
我们将创建一个名为“ Spark -word-count”的应用。在该应用中,我们将使用Spark来实现对文章中单词的出现频率进行统计。
为了能够正常运行该应用,需要在应用中添加以下Spark依赖。
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>2.3.0</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies> 项目配置
我们事先在D盘下准备了一个TXT文本文件——rfc7230.txt。该文件是HTTP规范RFC 7230的全文内容。
当我们的应用启动之后,会读取该文件的内容,作为词频统计的基础。
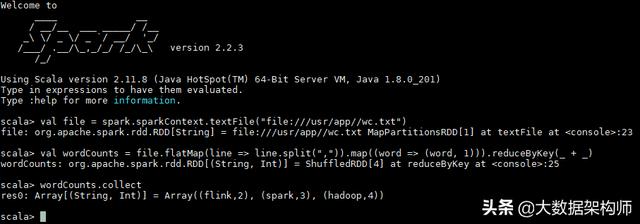
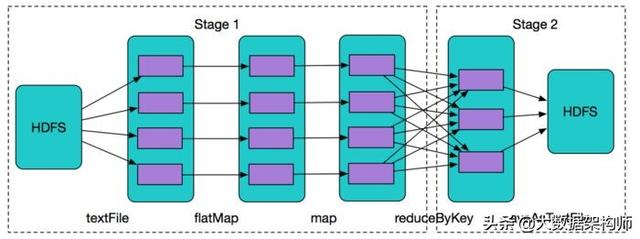
编码实现
基于Spark的词频统计程序将会变得非常简单。以下是应用
JavaWordCount的所有内容。
package com.waylau.spark;
import scala.Tuple2;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.SparkSession;
import java.util.Arrays;
import java.util.List;
import java.util. regex .Pattern;
public final class JavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
if (args.length < 1) {
System.err.println("Usage: JavaWordCount <file>");
System.exit(1);
}
SparkSession spark = SparkSession.builder().appName("JavaWordCount").
getOrCreate();
JavaRDD<String> lines = spark.read().textFile(args[0]).javaRDD();
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(SPACE.split(s)).
iterator());
JavaPairRDD<String, Integer> ones = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);
List<Tuple2<String, Integer >> output = counts.collect();
for (Tuple2<?, ?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
spark.stop();
}
} 运行
为了能够正常运行该程序,我们要在应用启动参数中指定待统计的文件rfc7230.txt所在的路径。同时,设置程序为local模式。启动参数设置如图13-2所示。

图13-2 启动参数设置
应用正常启动之后,应能在控制台看到以下词频统计信息。
Unfortunately,: 2
.................................................56: 1
constraints: 1
retry.: 2
Saurabh: 1
"accelerator": 1
desirable: 1
listening: 5
components.: 1
GmbH : 1
order: 29
7234,: 1
Compression: 2
Supported: 1
behind: 2
merge: 1
end: 6
been: 64evaluating: 1
Failures: 2
accomplished: 2
"?": 8
A.2.: 2
clients: 18
9.: 2
knows: 2
selective: 1
less: 2
Reed,: 1
supporting: 2
64]: 1
expanded.: 1
Nathan: 1
RWS: 12
ignore: 13
entry: 2
(DQUOTE: 1
are: 145
"path-abempty",: 1
2.: 5
Nilsson,: 1
Isomaki,: 1
Content-Type:: 1
consists: 4
undesirable: 1
Miles: 1
qvalues: 1
records: 1
different: 11
Smuggling: 2
trailer-part: 5
necessitated: 1
... 当然,词频统计列表较长,这里只展示了列表中的部分单词。
本节示例,可以在spark-word-count项目下找到。
本文给大家讲解的内容是分布式系统开发实战: 分布式计算, 实战:基于Spark词频统计
- 下篇文章给大家讲解的是分布式系统开发实战: 分布式存储, 分布式存储 常用技术;
- 觉得文章不错的朋友可以转发此文关注小编;
- 感谢大家的支持!


