导读
本文适合 Java 入门,不太适合Java中高级软件工程师。本文以《Java核心技术》第10版为蓝本,采用不断提出问题,然后解答问题的方式来讲述。本篇文章只是这个系列中的一篇,如果你喜欢这种讲解方式,或者觉得从中能学到知识,可以关注我,以便查阅本系列其他文章。

让我们开始愉快地学习Java语言吧!
1认识 JDBC
什么是JDBC?
JDBC是一个术语,而不是Java DataBase Connectivity的首字母缩写。它提供了访问数据库的API,并且可以使用结构化查询语言(SQL)完成对数据库的查找和更新。
JDBC的成功与其设计思想是分不开的,那么其设计思想是什么呢?
JDBC与 ODBC 基于同一思想:根据API编写的程序可与驱动管理器通信,驱动管理器通过驱动程序与数据库通信。
那么ODBC是什么呢?
ODBC是微软制定的访问数据库的接口标准。ODBC为异构数据库访问提供统一接口,并可以使用结构化查询语言存取数据。
驱动管理器是什么?
驱动程序管理器为应用程序加载和调用驱动程序,它可以同时管理多个应用程序和多个驱动程序。
JDBC为多种不同的数据库提供了统一访问的接口,而每种数据库对应的驱动程序不尽相同,那么驱动程序分几类呢?
1) 驱动程序将JDBC翻译成ODBC,然后通过ODBC驱动程序与数据库通信
2) 驱动程序由Java代码与本地代码构成,它调用数据库客户端API实现与数据库的通信。客户端要安装JDK和JRE,甚至是本地代码
3) 驱动程序只由Java语言编写,它使用与具体数据库无关的协议与数据库组件通信,然后该组件将此消息翻译为数据库相关的协议。
4) 驱动程序只由Java语言编写,它将JDBC发送给数据库的消息直接翻译为数据库相关的协议。
第3)和4)类驱动程序是目前最常见的。
JDBC 驱动程序部署在哪里呢?是在客户端还是在服务端呢?
注意,这里的服务端指的是数据库服务器所在的位置。
JDBC一般不位于服务端,即我们要操纵某个数据库,需要下载特定的驱动程序,然后在我们的应用程序中使用该驱动。
2 JDBC配置
JDBC URL
JDBC采用与URL相似的结构来描述数据源。
JDBC URL的一般形式为:
jdbc:subprotocal:other stuff
jdbc这部分是固定不变的,subprotocal代表具体的驱动程序,other stuff
依据subprotocal不同而不同。
例如:
连接 Derby :jdbc:derby:// localhost :1527/dbname;create=true
连接 MySQL :jdbc:mysql://localhost:3306/dbname
连接 PostgreSQL :jdbc:postgresql://localhost:5432/dbname
这里对other stuff部分仅举简单示例,还有很多参数供我们选用,详细的配置可以在官网文档中找到。
驱动Jar包与Shell
我们还要到数据库的官网下载驱动文件(当然如果使用 Maven 管理Jar包的话就不用这么麻烦),然后添加到我们的项目中。例如,你使用Eclipse作为开发工具,那么可以将Jar包引进来,但是强烈建议使用Maven管理Jar包。
如下面,开源框架JFoenix的示例代码就使用了Maven
此外,差不多每种数据库都会提供一些shell命令,不过如果觉得不方便的话可以安装图形界面的客户端。
驱动要向驱动管理器注册它自己,有些驱动类可以自动注册,那么都有哪些呢?
我们可以将下载的Jar包解压,若有META-INF/services/java.sql.Driver这个文件,那么这个驱动就可以自动注册。
对于不能自动注册的驱动类如何处理呢?
我们要在程序中加入如下代码:
Class.forName(驱动器类名);
或者
System.setProperty(“jdbc.drivers”,驱动器类名)
不同的数据库供应商提供了不同的类名,例如:
Derby驱动器类名: org . apache .derby.jdbc.ClientDriver
MySQL驱动器类名:com.mysql.jdbc.Driver
PostgreSQL驱动器类名:org.postgresql.Driver
不过我们一般不必这么麻烦,大多数驱动程序都是自动注册的Derby,MySQL,PostgreSQL都是这样。他们早期提供的驱动版本不是自动注册,目前的版本都是自动注册的。
3编程
下面以访问derby为例。
准备工作
正式开始编程前,让我们做些准备工作,我打算使用Maven来管理Jar包,所以先配置Maven。
如下图,我们打开,查找derby的依赖配置。
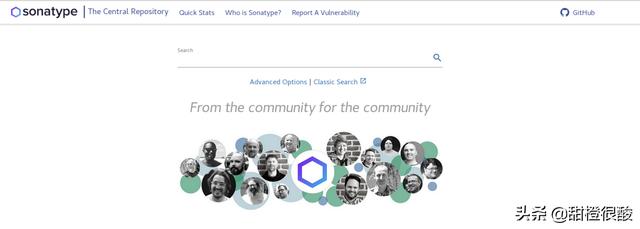
发现有好多选项,那么该选择哪一个呢?
应该选GroupId为org.apache.derby的那一个项目,然后选择一个10.15.1.3这个版本,但是如果你使用的是JDK 1.8那么没法用这个版本,因为这个版本要求JDK 1.9或更高版本,所以我使用10.14.2.0。将下面这段配置添加到pom.xml中;
<dependency>
<groupId>org.apache.derby</groupId>
<artifactId>derby</artifactId>
<version>10.14.2.0</version>
</dependency>
连接到数据库
我们使用DriverManager.getConnection这个方法创建数据库连接,注意这个方法会抛出必检异常。这个方法的参数是JDBC URL
我们还可以使用DriverManager.setLogWriter方法启用JDBC的跟踪特性。还可以在JDBC URL中添加参数来配置这一特性,例如:
jdbc:derby://localhost:1527/dbname;create=true;traceFile=trace.out
执行SQL语句
我们会调用Connection的实例方法create Statement ()创建一个Statement。
调用Statement对象的execute方法来执行给定的SQL语句,该语句可能返回多个结果。在某些(不常见)情况下,单个SQL语句可能返回多个结果集或更新计数。通常,可以忽略这一点,除非执行的存储过程可能返回多个结果,或者动态执行未知的SQL字符串。
调用Statement对象的executeQuery获得一个ResultSet对象。遍历ResultSet对象获得所有行。
要想获得数据库的综合信息可以使用DatabaseMetaData对象。

管理连接、语句和结果集
一个Connection对象可以创建多个Statement实例,默认情况下,一个Statement对象可以用于多个不相关的命令或查询,但只能同时打开一个ResultSet对象。因此,如果同时执行多个查询操作,那么必须创建多个Statement对象,一个Statement打开一个ResultSet对象。
调用DatabaseMetaData实例的getMaxStatements方法可以查看同时活动的Statement对象最大数量,如果返回0代表没有限制或者未知。
Connection、Statement、ResultSet都实现了接口AutoCloseable接口,当使用完以后务必关闭资源,可以使用try语句关闭资源。
PreparedStatement
如果多次执行同一个SQL语句,也就是说,语句大体相同,只是某些参数不同,那么最好使用PreparedStatement。
我们使用?作为变量的占位符。
例如:select * from books where BookName =?

读写LOB
上面介绍的方法都不适合读写大对象,要存储一个大对象怎么办?
使用 Blob 对象代表大文件,然后操作Blob对象将大对象存入数据库。看下面的例子:
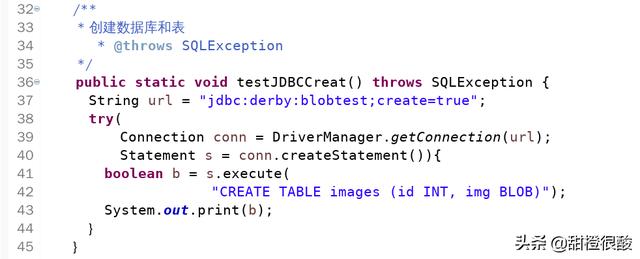
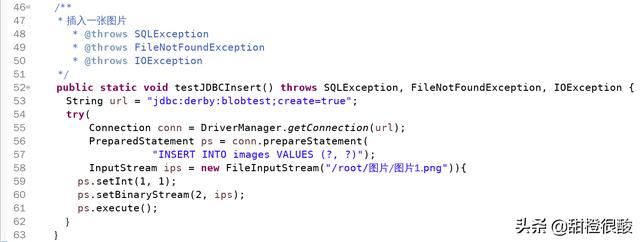
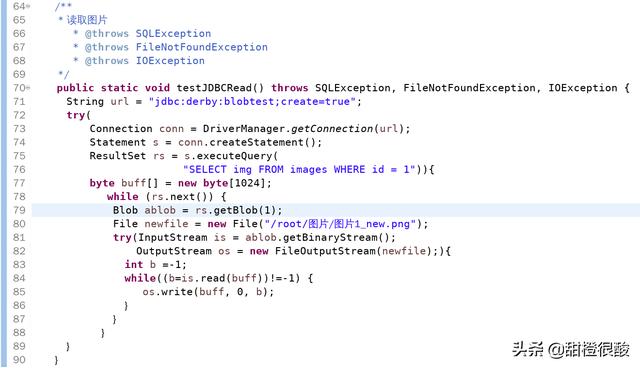
多结果集
有些数据库允许单个查询提交多个select语句,这样一个查询会返回多个结果集,如何获得多个结果集呢?
下面给出一个示例,注意:
1)调用execute执行SQL语句,返回结果为true表明第一个结果是结果集,如果是false表明对第一个是更新计数或无结果。
2)调用getMoreResults移动到下一个结果集,返回结果为true表明下一个结果是结果集,如果是false表明对下一个是更新计数或无结果。
3)这里有一个while循环,什么时候循环结束呢?遍历完所有结果的时候循环就该结束,如果SQL执行结果不是结果集且getUpdateCount返回值为-1,那么就意味着所有结果均遍历完。

获取自动生成键
可以使用ResultSet keys = s.getGeneratedKeys();来获得自动生成的键。
可滚动与可更新结果集
为什么需要可滚动结果集?
因为要展示结果,总不能将查询到的结果一次全部展示出来,正确的做法是分页展示,这样就需要可滚动结果集。
为了获得可滚动结果集要使用
createStatement(int resultSetType, int resultSetConcurrency)
和
prepareStatement(String sql, int resultSetType,
int resultSetConcurrency)
ResultSet中定义了多个常量值可为resultSetType和resultSetConcurrency赋值。
适合于resultSetType的常量
TYPE_FORWARD_ONLY,结果集不能滚动
TYPE_SCROLL_INSENSITIVE,可滚动,但对数据库变化不敏感
TYPE_SCROLL_SENSITIVE,可滚动,但对数据库变化敏感
适合于resultSetConcurrency的常量
CONCUR_READ_ONLY,结果集不能用于更新数据库
CONCUR_UPDATABLE,结果集可用于更新数据库
ResultSet提供了下面的方法滚动结果集:
previous():向后滚动,当 游标 位于有效的行上,返回true,如果游标位于第一行之前,则返回false。
relative(rows):如果rows大于0,向前移动rows行;小于0,向后移动rows行;等于0,则游标位于当前行不变。如果rows超出了结果集的范围,那么游标位于当前行不变且方法返回值为false。
使用SQL语句就可以完成更新操作,为什么需要可更新结果集?
使用可更新结果集的好处在于没有提交变更之前还可以撤销更改。
ResultSet提供了多种更新方法,都是以update开头的,例如updateDouble(int columnIndex, double x),用于更新当前行double型字段值。调用完这类方法后,调用updateRow()将变更提交给数据库,这样才会修改数据库中字段的值;在没调用updateRow()之前可以调用cancelRowUpdates()撤销变更。
还可以插入数据,例如
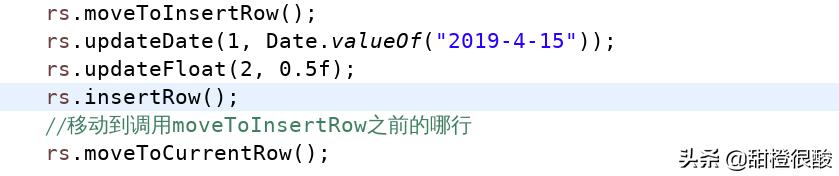
行集
可以使用结果集操作数据,那么为啥要使用行集?
使用结果集的时候,必须始终与数据库保持连接,而使用行集,可以在断开与数据库连接的情况下操作数据。
行集RowSet有多个扩展接口:CachedRowSet,WebRowSet,FilteredRowSet等。
以CachedRowSet为例的创建方法为:
RowSetFactory rsf = RowSetProvider.newFactory();
CachedRowSet cr = rsf.createCachedRowSet();
元数据
元数据是指描述数据库或其组成的数据。DatabaseMetaData代表了数据库元数据,它提供了很多获取数据库相关信息的方法。

还有一种和结果集相关的元数据ResultSetMetaData

事物
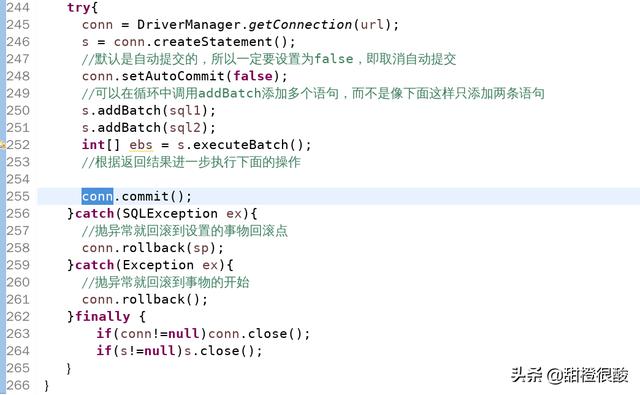
下面的代码展示事物操作的一般流程。
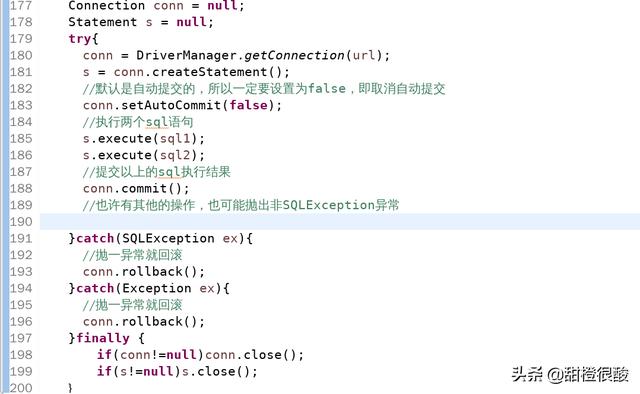
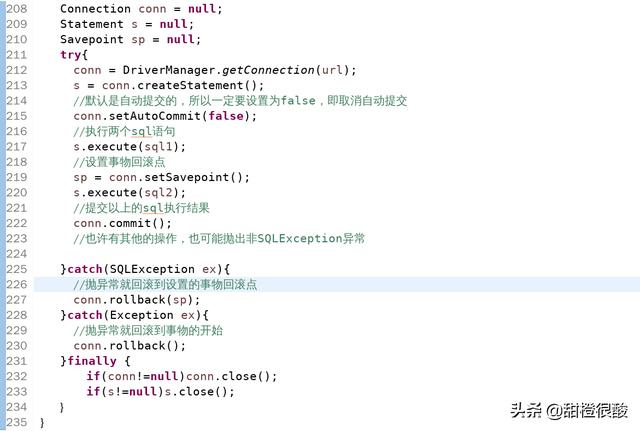
我们可以设置事物的回滚点,根据业务需要回滚到特定位置,而不是回滚到事物的开始处。
如果一次要插入多条记录到数据库,一条一条执行SQL语句效率比较低,所以使用批量提交,我们应该将批量提交视为事物。另外还要注意批量提交不支持select语句。