1.volatile
讲到 java 并发, 多线程 编程,一定避免不了对关键字volatile的了解,那么如何来认识volatile,从哪些方面来了解它会比较合适呢?
个人认为,既然是多线程编程,那我们在平常的学习中,工作中,大部分都接触到的就是线程安全的概念。
而线程安全就会涉及到共享变量的概念,所以首先,我们得弄清楚共享变量是什么,且处理器和内存间的数据交互机制是如何导致共享变量变得不安全。
共享变量
能够在多个 线程 间被多个线程都访问到的变量,我们称之为共享变量。共享变量包括所有的实例变量,静态变量和数组元素。他们都被存放在堆内存中。
处理器与内存的通信机制
大家都知道处理器是用来做计算的,且速度是非常快的,而内存是用来存储数据的,且其访问速度相比处理器来说,是慢了好几个级别的。那么当处理器需要处理数据时,如果每次都直接从内存拿数据的话,就会导致效率非常低,因此在现代计算机系统中,处理器是不直接跟内存通信的,而是在处理器和内存之间设置了多个缓存,也就是我们常常听到的L1, L2, L3等高速缓存。
具体架构如下所示:
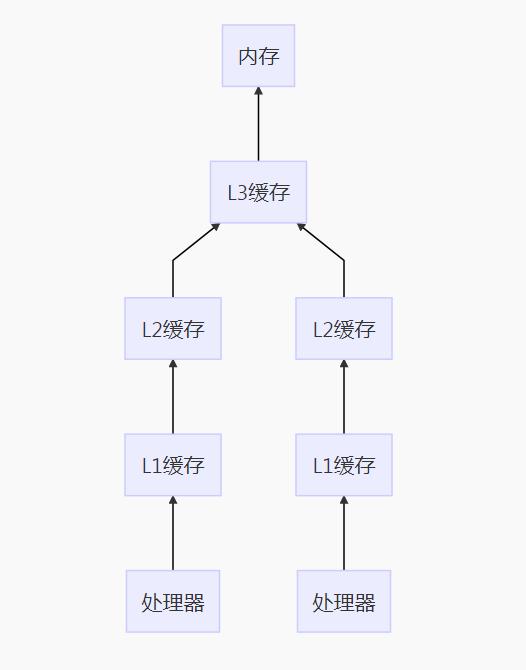
memory_processor_communication.png
处理器都是将数据从内存读到自己内部的缓存中,然后在缓存中对数据进行修改等操作,结束后再由缓存写到回主存中去。 如果一个共享变量 X,在多线程的情况下,同时被多个处理器读到各自的缓存中去,当其中一个处理器修改了X的值,改成Y了,先写回了内存,而此时另外一个处理器,又将X改成Z,再写回内存,那么之前的Y就会被覆盖掉了。
这种情况下,数据就已经有问题了,这种因为多线程操作而导致的异常问题,通常我们就叫做 线程不安全 。
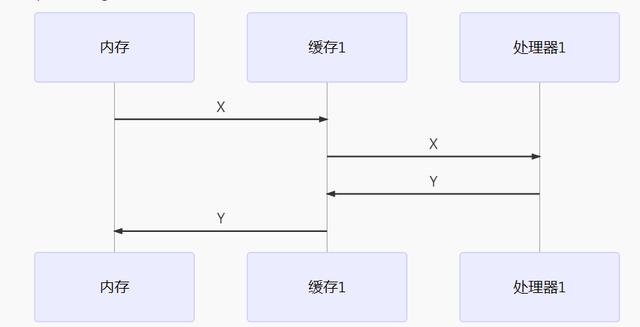
memory_processor_communication_core1.png
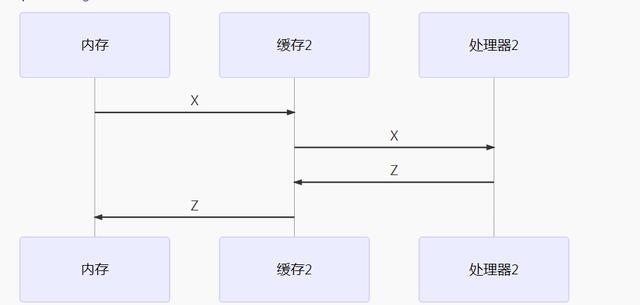
memory_processor_communication_core2.png
如上述两图所示,X的变量同时被不同的处理器修改成各自的Y和Z,那么如何避免这种情况呢? 这就涉及到了Java内存模型中的可见性的概念。
Java内存模型之可见性
可见性,意思就是说,在多线程编程中,某个共享变量在其中一个线程被修改了,其修改结果要马上能够被其他线程看到,拿上面的例子来说,也就是当X在其中一个处理器的缓存中被修改成Y了, 另一个处理器必须能够马上知道自己缓存中的X已经被修改成Y了,当此处理器要拿此变量去参与计算的时候,必须重新去内存中将此变量的值Y读到缓存中。
而一个变量,如果被声明成violate,那么其就能保证这种可见性,这就是 volatile变量 的作用了。
volatile
那么 volatile 变量能够保证可见性的实现原理是什么? 声明成volatile的变量,在编译成汇编指令的时候,会多出以下一行:
0x0bca13ae: Lock addl $0x0,(%esp) ;
这一句指令的意思是在寄存器上做一个+0的空操作,但这条指令有个Lock前缀。 而处理器在处理Lock前缀指令时,其实是声言了处理器的Lock#信号。 在之前的处理器中,Lock#信号会导致传输数据的总线被锁定,其他处理器都不能访问总线,从而保证处理Lock指令的处理器能够独享操作数据所在的内存区域。
但由于总线被锁住,其他的处理器都被堵住了,影响多处理器执行的效率。在后来的处理器中,声言Lock#信号的处理器,不会再锁住总线,而是检查到数据所在的内存区域,如果是在处理器的内部缓存中,则会锁定此缓存区域,将缓存写回到内存当中,并利用 缓存一致性 的原则来保证其他处理器中的缓存区域数据的一致性。
缓存一致性
缓存一致性原则会保证一个在缓存中的数据被修改了,会保证其他缓存了此数据的处理器中的缓存失效,从而让处理器重新去内存中读取最新修改后的数据。
在实际的处理器操作中,各个处理器会一直在总线上嗅探其内部缓存区域中的内存地址在其它处理器的操作情况,一旦嗅探到某处理器打算修改某内存地址,而此内存地址刚好也在自己内部的缓存中,则会强制让自己的缓存无效。当下次访问此内存地址的时候,则重新从内存当中读取新数据。
volatile不仅保证了共享变量在多线程间的可见性,其还保证了一定的有序性。
有序性
何谓有序性呢? 事实上,java程序代码在编译器阶段和处理器执行阶段,为了优化执行的效率,有可能会对指令进行重排序。 如果一些指令彼此之间互相不影响,那么就有可能不按照代码顺序执行,比如后面的代码先执行,而之前的代码则慢执行,但处理器会保证结束时的输出结果是一致的。 以上的这种情况就说明指令有可能不是有序的。
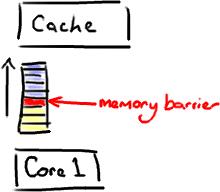
volatile变量,上面我们看过其汇编指令,会多出一条Lock前缀的指令,这条指令能够 保证,在这条指令之前的所有指令全部执行完毕,而在这条指令之后的所有指令全部未执行,也相于在这里立起了一道栅栏,称之为内存栅栏,而更通俗的说法,则是 内存屏障 。
那么有了这道屏障,volatile变量就禁止了指令的重排序,从而保证了指令执行的有序性。
所有对volatile变量的读操作一定发生在对volatile变量的写操作之后。这同时也说明了volatile变量在多个线程之间能够实现可见性的原理。所以各种规定和操作,其实之间互有关联,彼此依赖,才能更好地保证指令执行的准确和效率。
内存屏障
在上面我们也引出了 内存屏障 的概念,也知道了,其实它就是一组处理器的操作指令。
插入一个内存屏障,则相当于告诉处理器和编译器先于这个指令的必须先执行,后于这个指令的必须后执行。
image
内存屏障另一个作用是强制更新一次不同CPU的缓存。
例如,一个写屏障会把这个屏障前写入的数据刷新到缓存,这样任何试图读取该数据的线程将得到最新值,而不用考虑到底是被哪个cpu核心或者哪颗CPU执行的。
这再仔细一想,不就是上面所说的volatile的作用吗?
所以,内存屏障,可见性,有序性,缓存一致性原则,在java并发中各种各样的名词,本质上可能就只是同一种现象或者同一种设计,从不同的角度观察和探讨所得出的不同的解释。
2. synchronized
public synchronized void doSomething() {
//do something here
}
或者
synchronized(LockObject) {
//do something here
}
那么实际上,synchronized关键字到底是怎么加锁的?锁又长什么样子的呢?关于锁,还有一些什么样的概念需要我们去认识,去学习,去理解的呢?
以前在学习synchronized的时候,就有文章说, synchronized是一个很重的操作,开销很大,不要轻易使用,我们接受了这样的观点,但是为什么说是重的操作呢,为什么开销就大呢?
到java 1.6之后,java的开发人员又针对锁机制实现了一些优化,又有文章告诉我们现在经过优化后,使用synchronized并没有什么太大的问题了,那这又是因为什么原因呢?到底是做了什么优化?
那今天我们就尝试着从锁机制实现的角度,来讲述一下synchronized在java 虚拟机 上面的适应场景是怎么样的。
由于java在1.6之后,引入了一些优化的方案,所以我们讲述synchronized,也会基于java1.6之后的版本。
锁对象
首先,我们要知道锁其实就是一个对象,java中每一个对象都能够作为锁。
所以我们在使用synchronized的时候,
- 对于同步代码块,就得指定锁对象。
- 对于修饰方法的synchronized,默认的锁对象就是当前方法的对象。
- 对于修饰静态方法的synchronized,其锁对象就是此方法所对应的类Class对象。
我们知道,所谓的对象,无非也就是内存上的一段地址,上面存放着对应的数据,那么我们就要想,作为锁,它跟其它的对象有什么不一样呢?怎么知道这个对象就是锁呢?怎么知道它跟哪个线程关联呢?它又怎么能够控制线程对于同步代码块的访问呢?
Markword
可以了解到在虚拟机中,对象在内存中的存储分为三部分:
- 对象头
- 实例数据
3 对齐填充
其中,对象头填充的是该对象的一些运行时数据,虚拟机一般用2到3个字宽来存储对象头。
- 数组对象,会用3个字宽来存储。
- 非数据对象,则用2个字宽来存储。
其结构简单如下:
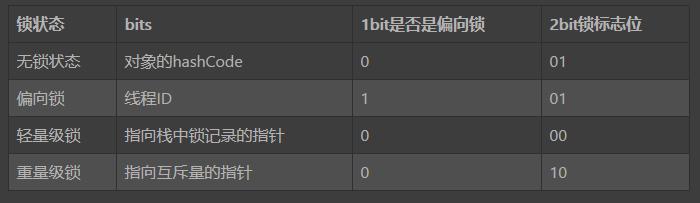
长度 内容 说明 32/64bit Markword hashCode,GC分代年龄,锁信息 32/64bit Class Metadata Address 指向对象类型数据的指针 32/64bit Array Length 数组的长度(当对象为数组时)
从上表中,我们可以看到,锁相关的信息,是存在称之为Markword中的内存域中。
拿以下的代码作为例子,
public class JsonViewRequestBodyAdvice extends RequestBodyAdviceAdapter {
/**
* 这里是一个前置拦截匹配操作,其实就是告诉你满足为true的才会执行下面的beforeBodyRead方法,这里可以定义自己业务相关的拦截匹配
* @param methodParameter
* @param targetType
* @param converterType
* @return
*/
@Override
public boolean supports(MethodParameter methodParameter, Type targetType,
Class<? extends HttpMessageConverter<?>> converterType) {
return (AbstractJackson2HttpMessageConverter.class.isAssignableFrom(converterType) &&
methodParameter.getParameterAnnotation(JsonView.class) != null);
}
// 这里就是具体的前置操作了... 下面的例子就是查找这个入参方法是否有@JsonView修饰
@Override
public HttpInputMessage beforeBodyRead(HttpInputMessage inputMessage, MethodParameter methodParameter,
Type targetType, Class<? extends HttpMessageConverter<?>> selectedConverterType) throws IOException {
JsonView annotation = methodParameter.getParameterAnnotation(JsonView.class);
Class<?>[] classes = annotation.value();
if (classes.length != 1) {
throw new IllegalArgumentException(
"@JsonView only supported for request body advice with exactly 1 class argument: " + methodParameter);
}
return new MappingJacksonInputMessage(inputMessage.getBody(), inputMessage.getHeaders(), classes[0]);
}
}
在对象LockObject的对象头中,当其被创建的时候,其Markword的结构如下:
bit fields 是否偏向锁 锁标志位 hash age 0 01
从上面Markword的结构中,可以看出
所有新创建的对象,都是可偏向的(锁标志位为01),但都是未偏向的(是否偏向锁标志位为0)。
偏向锁
当线程执行到临界区(critical section)时,此时会利用CAS(Compare and Swap)操作,将线程ID插入到Markword中,同时修改偏向锁的标志位。
这说明此对象就要被当做一个锁来使用,那么其Markword的内容就要发生变化了。 其结构其会变成如下:
bit fields 是否偏向锁 锁标志位 threadId epoch age 1 01
可以看到,
- 锁的标志位还是01
- “是否偏向锁”这个字段变成了 1
- hash值变成了线程ID和epoch值
也就是说,这个锁将自己偏向了当前线程,心里默默地藏着线程id, 在这里,我们就引入了“偏向锁”的概念。
在此线程之后的执行过程中,如果再次进入或者退出同一段同步块代码,并不再需要去进行加锁或者解锁操作,而是会做以下的步骤:
- Load-and-test,也就是简单判断一下当前线程id是否与Markword当中的线程id是否一致.
- 如果一致,则说明此线程已经成功获得了锁,继续执行下面的代码
- 如果不一致,则要检查一下对象是否还是可偏向,即“是否偏向锁”标志位的值。
- 如果还未偏向,则利用CAS操作来竞争锁,也即是第一次获取锁时的操作。
- 如果此对象已经偏向了,并且不是偏向自己,则说明存在了竞争。此时可能就要根据另外线程的情况,可能是重新偏向,也有可能是做偏向撤销,但大部分情况下就是升级成轻量级锁了。
以下是Java开发人员提供的一张图:
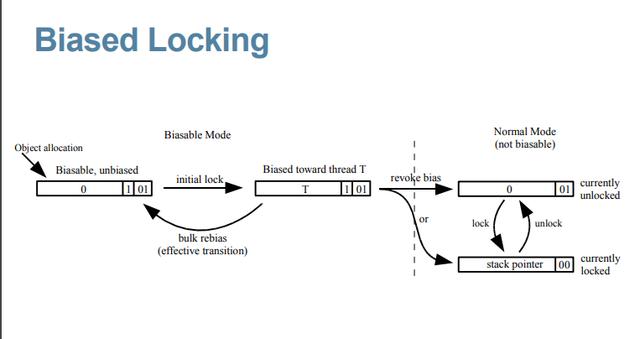
“偏向锁”是Java在1.6引入的一种优化机制,其核心思想在于,可以让同一个线程一直拥有同一个锁,直到出现竞争,才去释放锁。
因为经过虚拟机开发人员的调查研究,在大多数情况下,总是同一个线程去访问同步块代码,基于这样一个假设,引入了偏向锁,只需要用一个CAS操作和简单地判断比较,就可以让一个线程持续地拥有一个锁。
也正因为此假设,在Jdk1.6中,偏向锁的开关是默认开启的,适用于只有一个线程访问同步块的场景。
锁膨胀
在上面,我们讲到,一旦出现竞争,也即有另外一个线程也要来访问这一段代码,偏向锁就不适用于这种场景了。
如果两个线程都是活跃的,会发生竞争,此时偏向锁就会发生升级,也就是我们常常听到的锁膨胀。
偏向锁会膨胀成轻量级锁(lightweight locking)。
锁撤销
偏向锁有一个不好的点就是,一旦出现多线程竞争,需要升级成轻量级锁,是有可能需要先做出销撤销的操作。
而销撤销的操作,相对来说,开销就会比较大,其步骤如下:
- 在一个安全点停止拥有锁的线程,就跟开始做GC操作一样。
- 遍历线程栈,如果存在锁记录的话,需要修复锁记录和Markword,使其变成无锁状态。
- 唤醒当前线程,将当前锁升级成轻量级锁。
轻量级锁
而本质上呢,其实就是锁对象头中的Markword内容又要发生变化了。
下面先简单地描述 其膨胀的步骤:
- 线程在自己的栈桢中创建锁记录 LockRecord
- 将锁对象的对象头中的MarkWord复制到线程的刚刚创建的锁记录中
- 将锁记录中的Owner指针指向锁对象
- 将锁对象的对象头的MarkWord替换为指向锁记录的指针。
同样,我们还是利用Java开发人员提供的一张图来描述此步骤:
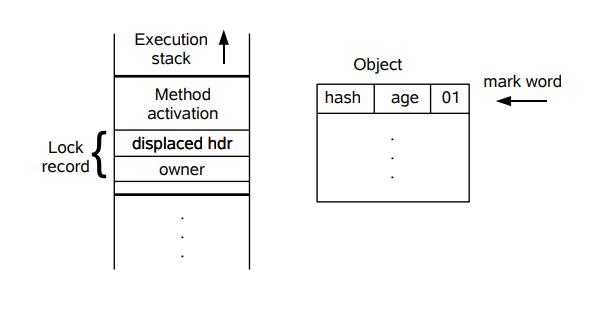
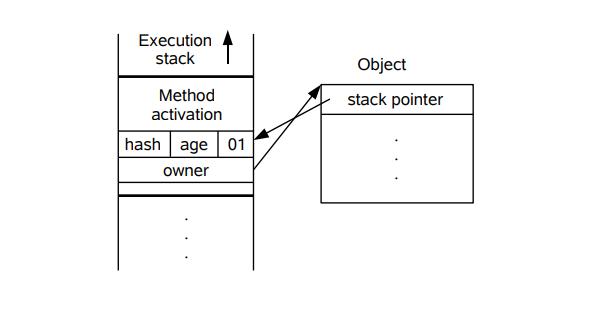
可以根据上面两图来印证上面几个步骤,但在这里,其实对象的Markword其实也是发生了变化的,其现在的内容结构如下:
bit fields 锁标志位 指向LockRecord的指针 00
说到这里,我们又通过偏向锁引入了轻量级锁的概念,那么轻量级锁是怎么个轻量级法,它具体的实现又是怎么样的呢?
就像偏向锁的前提,是同步代码块在大多数情况下只有同一个线程访问的时候。 而轻量级锁的前提则是,线程在同步代码块里面的操作非常快,获取锁之后,很快就结束操作,然后将锁释放出来。
但是不管再怎么快,一旦一个线程获得锁了,那么另一个线程同时也来访问这段代码时,怎么办呢?这就涉及到我们下面所说的锁自旋的概念了。
自旋锁/自适应自旋锁
来到轻量级锁,其实轻量级的叙述就来自于自旋的概念。 因为前提是线程在临界区的操作非常快,所以它会非常快速地释放锁,所以只要让另外一个线程在那里地循环等待,然后当锁被释放时,它马上就能够获得锁,然后进入临界区执行,然后马上又释放锁,让给另外一个线程。 所谓自旋,就是线程在原地空循环地等待,不阻塞,但它是消耗CPU的。 所以对于轻量级锁,它也有其限制所在:
- 因为消耗CPU,所以自旋的次数是有限的,如果自旋到达一定的次数之后,还获取不到锁,那这种自旋也就无意义。但在上述的前提下,这种自旋的次数还是比较少的(经验数据)。 当然,一开始的自旋次数都是固定的,但是在经验代码中,获得锁的线程通常能够马上再获得锁,所以又引入了自适应的自旋,即根据上次获得锁的情况和当前的线程状态,动态地修改当前线程自旋的次数。
- 当另一个线程释放锁之后,当前线程要能够马上获得锁,所以如果有超过两个的线程同时访问这段代码,就算另外一个线程释放锁之后,当前线程也可能获取不到锁,还是要继续等待,空耗CPU。
从以上两点可以看出,当线程通过自旋获取不到锁了,比如临界区的操作太花时间了,或者有超过2个以上的线程在竞争锁了,轻量级锁的前提又不成立了。当虚拟机检查到这种情况时,又开始了膨胀的脚步。
互斥锁(重量级锁)
相比起轻量级锁,再膨胀的锁,一般称之为重量级锁,因为是依赖于每个对象内部都有的monitor锁来实现的,而monitor又依赖于操作系统的MutexLock(互斥锁)来实现,所以一般重量级锁也叫互斥锁。
由于需要在操作系统的内核态和用户态之间切换的,需要将线程阻塞挂起,切换线程的上下文,再恢复等操作,所以当synchronized升级成互斥锁,依赖monitor的时候,开销就比较大了,而这也是之前为什么说synchronized是一个很重的操作的原因了。
当然,升级成互斥锁之后,锁对象头的Markword内容也是会变化的,其内容如下:
bit fields 锁标志位 指向Mutex的指针 10
每次检查当前线程是否获得锁,其实就是检查Mutex的值是否为0,不为0,说明其为其线程所占有,此时操作系统就会介入,将线程阻塞,挂起,释放CPU时间,等待下一次的线程调度。
好了,到这里,对于synchronized所修改的同步方法或者同步代码块,虚拟机是如何操作的,大家应该也有一个简单的印象了。
当使用synchronized关键字的时候,在java1.6之后,根据不同的条件和场景,虚拟机是一步一步地将偏向锁升级成轻量级锁,再最终升级成重量级锁的,而这个过程是不可逆的,因为一旦升级成重量级锁,则说明偏向锁和轻量级锁是不适用于当前的应用场景的,那再降级回去也没什么意义。
从这一点,也可以看出,如果我们的应用场景本身就不适用于偏向锁和轻量级锁,那么我们在程序一开始,就应该禁用掉偏向锁和轻量级锁,直接使用重量级锁,省去无谓的开销。
总结
在这里总结一下,在使用synchronized关键字的时候,本质上是否获得锁,是通过修改锁对象头中的markword的内容来标记是否获得锁,并由虚拟机来根据具体的应用场景来锁进行升级。
简单地将上述几个零散的markword变化合在一起,展示在下面:
今天的分享就到这了,我这里准备了一套java进阶方法笔记,学习资料面试题,电子书等免费笔记供大家学习.需要的小伙伴私信我回复”Java”即可领取免费资料.

java核心知识点



