为什么需要 Stream
Stream 作为 Java 8 的一大亮点,它与 java. io 包里的 InputStream 和 OutputStream 是完全不同的概念。它也不同于 StAX 对 XML 解析的 Stream,也不是 Amazon Kinesis 对大数据实时处理的 Stream。Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行 多线程 的代码,就可以很方便地写出高性能的并发程序。所以说,Java 8 中首次出现的 java.util.stream 是一个函数式语言+多核时代综合影响的产物。
流的构成
当我们使用一个流的时候,通常包括三个基本步骤:
获取一个数据源(source)→ 数据转换→执行操作获取想要的结果,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道,如下图所示。
图 1. 流管道 (Stream Pipeline) 的构成
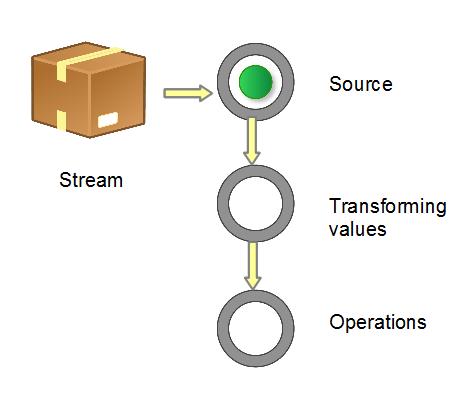
流的操作类型分为两种:
- Intermediate :一个流可以后面跟随零个或多个 intermediate 操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。
- Terminal :一个流只能有一个 terminal 操作,当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。Terminal 操作的执行,才会真正开始流的遍历,并且会生成一个结果,或者一个 side effect。
流的操作
接下来,当把一个数据结构包装成 Stream 后,就要开始对里面的元素进行各类操作了。常见的操作可以归类如下。
- Intermediate:
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
- Terminal:
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
- Short-circuiting:
anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
map/flatMap
我们先来看 map。如果你熟悉 scala 这类函数式语言,对这个方法应该很了解,它的作用就是把 input Stream 的每一个元素,映射成 output Stream 的另外一个元素。
清单 7. 转换大写
List<String> output = wordList.stream().
map(String::toUpperCase).
collect(Collectors.toList());
这段代码把所有的单词转换为大写。
清单 8. 平方数
List<Integer> nums = Arrays.asList(1, 2, 3, 4);
List<Integer> squareNums = nums.stream().
map(n -> n * n).
collect(Collectors.toList());
这段代码生成一个整数 list 的平方数 {1, 4, 9, 16}。
reduce
这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说, 字符串 拼接、数值的 sum、min、max、average 都是特殊的 reduce。例如 Stream 的 sum 就相当于
Integer sum = integers.reduce(0, (a, b) -> a+b); 或
Integer sum = integers.reduce(0, Integer::sum);
也有没有起始值的情况,这时会把 Stream 的前面两个元素组合起来,返回的是 Optional。
清单 . reduce 的用例
// 字符串连接,concat = "ABCD"
String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
// 求最小值,minValue = -3.0
Double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);
// 求和,sumValue = 10, 有起始值
int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
// 求和,sumValue = 10, 无起始值
sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
// 过滤,字符串连接,concat = "ace"
concat = Stream.of("a", "B", "c", "D", "e", "F").
filter(x -> x.compareTo("Z") > 0).
reduce("", String::concat); 进阶:用 Collectors 来进行 reduction 操作
java.util.stream.Collectors 类的主要作用就是辅助进行各类有用的 reduction 操作,例如转变输出为 Collection,把 Stream 元素进行归组。
groupingBy/partitioningBy
清单 . 按照年龄归组
Map<Integer, List<Person>> personGroups = Stream.generate(new PersonSupplier()).
limit(100).
collect(Collectors.groupingBy(Person::getAge));
Iterator it = personGroups.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, List<Person>> persons = (Map.Entry) it.next();
System.out.println("Age " + persons.getKey() + " = " + persons.getValue().size());
}
上面的 code,首先生成 100 人的信息,然后按照年龄归组,相同年龄的人放到同一个 list 中,可以看到如下的输出:
Age 0 = 2
Age 1 = 2
Age 5 = 2
Age 8 = 1
Age 9 = 1
Age 11 = 2
……
Stream 的特性可以归纳为:
- 不是数据结构
- 它没有内部存储,它只是用操作管道从 source(数据结构、数组、generator function、IO channel)抓取数据。
- 它也绝不修改自己所封装的底层数据结构的数据。例如 Stream 的 filter 操作会产生一个不包含被过滤元素的新 Stream,而不是从 source 删除那些元素。
- 所有 Stream 的操作必须以 lambda 表达式为参数
- 不支持索引访问
- 你可以请求第一个元素,但无法请求第二个,第三个,或最后一个。不过请参阅下一项。
- 很容易生成数组或者 List
- 惰性化
- 很多 Stream 操作是向后延迟的,一直到它弄清楚了最后需要多少数据才会开始。
- Intermediate 操作永远是惰性化的。
- 并行能力
- 当一个 Stream 是并行化的,就不需要再写多线程代码,所有对它的操作会自动并行进行的。
- 可以是无限的集合有固定大小,Stream 则不必。limit(n) 和 findFirst() 这类的 short-circuiting 操作可以对无限的 Stream 进行运算并很快完成。


