本章介绍一些常用的流和 Lambda 表达式 的高级使用案例。
一、流收集器
初始化设定代码
enum Mark { // 分数等级
A, B, C // A优秀,B一般,C不及格
}
public class Student { // 学生类
String name; // 姓名
boolean sex; // 性别
int score; // 分数
}
List<Student> list = new ArrayList<>();// 存放学生列表
1、partitioningBy收集器,它接受一个流, 并将其分成两部分,它使用 Predicate 对象判断一个元素应该属于哪个部分, 并根据 布尔值 返回一个 Map 到列表。 因此, 对于 true List 中的元素, Predicate 返回 true; 对其他 List 中的元素, Predicate 返回 false。 如下图所示
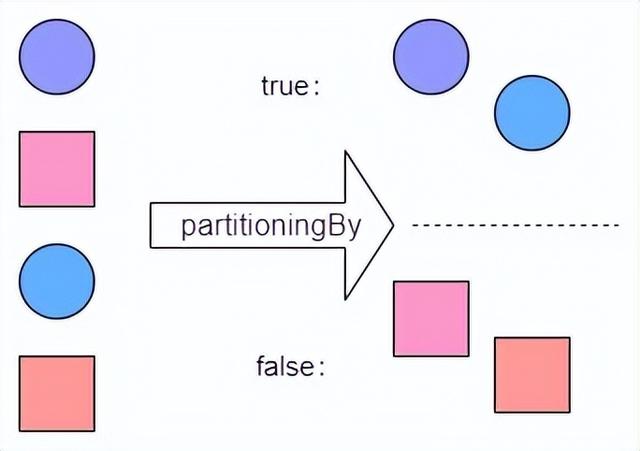
partitioningBy收集器
下面的例子使用partitioningBy将学生按性别分成两类,代码如下
Map<Boolean, List<Student>> collect = list. Stream ()
.collect(Collectors.partitioningBy(Student::isSex));
2、groupingBy收集器,是一种更自然的分割数据操作, 与将数据分成 ture 和 false 两部分不同, 可以使 用任意值对数据分组。groupingBy 收集器接受一个分类函数, 用来对数据分组, 就像 partitioningBy 一样, 接受一个Predicate 对象将数据分成 ture 和 false 两部分。 这里groupingBy使用的分类器是一个 Function 对象, 和 stream map 操作用到的一样。如下图所示
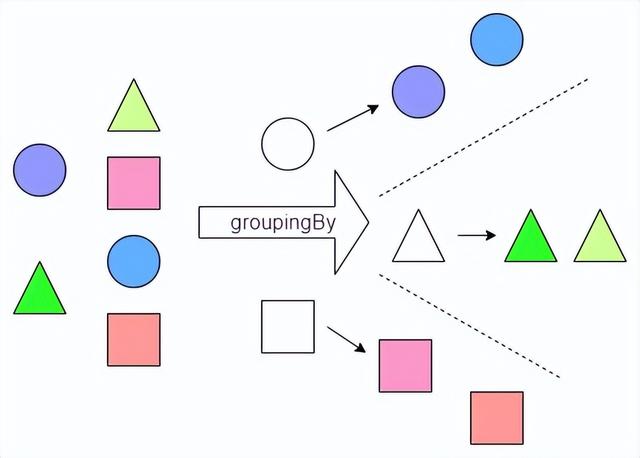
groupingBy收集器
下面的例子使用groupingBy将学生按成绩分成3个等级,代码如下
Map<Mark, List<Student>> collect = list.stream()
.collect(Collectors.groupingBy(student -> {
if (student.getScore() >= 90) return Mark.A;
else if (student.getScore() >= 60 && student.getScore() < 90) return Mark.B;
else return Mark.C;
}));
3、其他一些收集器,代码如下
// 计算所有学生总成绩
Integer totalScore = list.stream()
.collect(Collectors.summingInt(Student::getScore));
// 计算所有学生平均分
Double averagingScore = list.stream()
.collect(Collectors.averagingInt(Student::getScore));
// 将学生姓名拼成一个 字符串
String names = list.stream(). map (Student::getName)
.collect(Collectors.joining(", ", "[", "]"));
4、组合使用收集器。虽然各种收集器已经很强大了,但如果将它们组合起来,会变得更强大。 代码如下
// 先按性别分类,再各分类计算成绩和
Map<Boolean, Integer> result = list.stream()
.collect(Collectors.partitioningBy(Student::isSex, Collectors.summingInt(Student::getScore)));
// 先按成绩等级分类,再计算每个等级的人数
Map<Mark, Long> result = list.stream()
.collect(Collectors.groupingBy(student -> {
if (student.getScore() >= 90) return Mark.A;
else if (student.getScore() >= 60 && student.getScore() < 90) return Mark.B;
else return Mark.C;
}, Collectors.counting()));
二、流并行处理
并行流就是一个把内容分成多个数据块,并用不同的 线程 分别处理每个数据块的流。这样一来,你就可以自动把给定操作的工作负荷分配给 多核处理器 的所有内核,提高性能。并行化操作流只需改变一个方法调用,如果已经有一 个Stream对象,调用它的parallel 方法就能让其拥有并行操作的能力。 如果想从一个集合类创建一个流,调用 parallelStream 就能立即获得一个拥有并行能力的流。代码如下
List<String> list = new ArrayList<>();
list.parallelStream();
list.stream().parallel();
Stream.of(list).parallel();
// 以上3种写法本质是一样的,没有区别
在第二章中,举例使用Stream的reduce方法画出计算过程,现在使用并行处理,代码如下
int sum = Stream.of(1, 2, 3, 4, 5, 6, 7, 8).parallel().reduce(0, Integer::sum);
// sum = 36
Stream在内部分成了几块,因此可以对不同的块独立并行进行reduce操作,同一个reduce操作会将各个子流的部分reduce结果合并起来,得到整个原始流的归纳结果,如下图
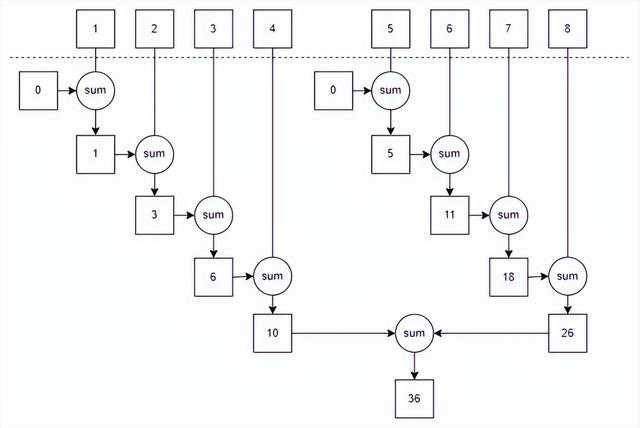
并行reduce计算示例图
并行流用处很多,不需要自行写线程处理,所以可以简单高效地写出高性能代码。常见的并行多次网络请求合并结果,简单的模拟代码如下
static Random random = new Random(System.currentTimeMillis());
public static void main(String[] args) {
Map<String, String> map = Stream.of(" nodejs ", " java ", "python")
.parallel()
.collect(Collectors.toMap(s -> s, s -> {
System.out.println(s + " worker " + Thread.currentThread().getName() + " start");
String result = httpGetInfo(s);
System.out.println(s + " worker " + Thread.currentThread().getName() + " end");
return result;
}));
System.out.println(map);
}
// 模拟http请求,http结果返回时间随机
public static String httpGetInfo(String s) {
int ms = random.nextInt(50000);
try {
System.out.println(s + " sleep " + ms);
Thread.sleep(ms);
} catch (Interrupted Exception e) {}
return s.toUpperCase();
}
三、 Lambda表达式 在Reactor中的应用
Reactor实现了响应式编程Reactive Streams规范,是异步非阻塞框架,Spring WebFlux是基于Reactor实现的异步非阻塞式的 Web框架,它能够充分利用多核 CPU的硬件资源去处理大量的并发请求。
Flux和Mono是Reactor中的两个基本概念,充当响应式编程中发布者的角色,在 Spring WebFlux中直接返回Flux和Mono对象,由客户端充当订阅者。
- Mono:返回0或1个元素,是单个对象
- Flux:返回0到N个元素,是列表对象
// Flux初始化
Flux<String> seq1 = Flux.just("nodejs", "java", " python ");
Flux<String> seq2 = Flux.fromIterable(Arrays.asList("nodejs", "java", "python"));
Flux<Integer> ints = Flux.range(1, 4);
// Mono初始化
Mono<String> noData = Mono.empty();
Mono<String> data = Mono.just("foo");
使用方法举例
// Flux发布对象
Flux<String> ints = Flux.just("nodejs", "java", "python")
.map(String::toUpperCase); // map方法和stream的map方法一样
// subscribe方法开始订阅
ints.subscribe(System.out::println, // 消费对象
error -> System.err.println("Error: " + error), // 从发布者接收到的异常
() -> System.out.println("done")); // 订阅完成操作
详细内容参考以下文档
- #spring-webflux
四、Lambda表达式在 log4j 中的应用
相对于其他日志组件,log4j2提供了Lambda表达式写法,它有什么作用呢,对比一下下面的代码
// 这条日志是很常见的http请求输出,其中read Request Heads是读取http请求所有head字段,需要执行拼接字符串操作
// 第一种日志写法
logger.debug("method:{} requestURI:{} heads:{}", req.getMethod(), req.getRequestURI(), readRequestHeads(req));
// 第二种日志写法
if (logger.isDebugEnabled()) {
logger.debug("method:{} requestURI:{} heads:{}", req.getMethod(), req.getRequestURI(), readRequestHeads(req));
}
// 第三种日志写法
logger.debug("method:{} requestURI:{} heads:{}", req::getMethod, req::getRequestURI, () -> readRequestHeads(req));
第一种写法:不管日志是什么级别readRequestHeads方法都会执行
第二种写法:加了逻辑判断,在debug级别以上readRequestHeads方法不会执行
第三种写法:参数传入了Lambda表达式,在内部实现是上先判断日志级别,再决定Lambda表达式是否执行,所以在debug级别以上readRequestHeads方法不会执行
这里就可以看出日志中使用Lambda表达式可以有条件的延迟执行日志拼装,而无需增加判断是否启用了请求的日志级别。
详细内容参看以下文档
#LambdaSupport


