一、概述
- 在使用层面, Redis 提供了用于存放 字符串 数据的列表这种数据类型,在数据存储容量方面,列表最多可以存放2的32次方减一个字符串元素,即大概40亿左右,不过一般不要存放这么多,否则由于数据是存放在内存中的,可能会撑爆内存。
- 在内部数据结构实现层面,列表主要是基于链表实现的,字符串数据按照插入顺序在链表中排序,其中插入方式可以在链表前面和后面插入。除此之外,Redis还提供了列表的阻塞读取BLPOP和BRPOP。
- 除了以上所述列表这种数据类型的特点之外,Redis服务器又是以单线程的方式处理客户端的请求的,所以Redis的列表非常适合用于实现一个轻量级的消息队列,即生产者往队列填充数据,消费者从队列等待读取数据,从而在分布式系统之间实现一个类似于 Java 的阻塞队列LinkedBlockingQueue的数据类型,其中LinkedBlockingQueue是Java编程中常用于实现同一个Java进程的多个线程之间的生产者消费者模型的一个线程安全的队列实现。
二、使用方法
- 在使用方面,在Redis中实现一个消息队列主要是基于列表可从队列头部和尾部插入字符串元素和列表支持可阻塞读的特性。除此之外,在编程方面也可以在消息队列消费者端使用while(true)死循环来轮询获取队列的数据,不过这种方式对程序性能影响较大,不推荐使用。
- 如果生产者往列表填充了数据,而没有消费者从列表读取消费数据,则数据就存放在列表中直到有消费者读取才删除该数据。
基于Redis命令行的使用
- 基于Redis命令行操作列表来实现消息队列主要用于演示这种功能,在实际应用中不会用到,而是基于语言对应的Redis代码库提供的API来进行编程实现。如下演示实现一个FIFO的消息队列:
1.消息队列的消费者调用BLPOP命令,从消息队列的头部或者说是左边,阻塞获取数据,其中命令格式为:BLPOP [key1 key2…] timeout,其中key为队列名称,可以指定多个队列,当只要有一个队列有数据返回时,则调用返回;timeout为阻塞指定的时间,值为0则是一直阻塞直到有数据可以读取则返回,大于0则是阻塞指定的秒数。如下:第一次阻塞1秒直接返回,没有读取到数据,第二次则是阻塞直到队列中有数据到来,当读取到一个数据后,则返回。
127.0.0.1:6379> BLPOP queueList 1 (nil) (1.05s) 127.0.0.1:6379> BLPOP queueList 0 1) "queueList" 2) "stringData1" (3.94s)
2.消息队列的生产者调用RPUSH命令往消息队列的尾部或者说是右边填充数据,如下:调用RPUSH从列表queueList尾部,即右边,填充了两个字符串数据,其中第一个字符串内容为stringData1,所以上面的消费者也是读取到了这个字符串。
127.0.0.1:6379> RPUSH queueList stringData1 stringData2 (integer) 2
3.一段时间之后,再次调用BLPOP命令则直接从列表中读取到了刚刚填充的第二个字符串数据stringData2,无需阻塞:
127.0.0.1:6379> BLPOP queueList 0 1) "queueList" 2) "stringData2"
基于Java客户端Jedis的使用
- 当使用Java语言基于Redis列表实现一个消息队列时,可以使用Redis的Java客户端Jedis,如果使用了spring-data-redis则可以使用该包提供的相关类和API,如RedisTemplate。如下代码演示了使用Jedis和基于Redis的列表实现一个消息队列:
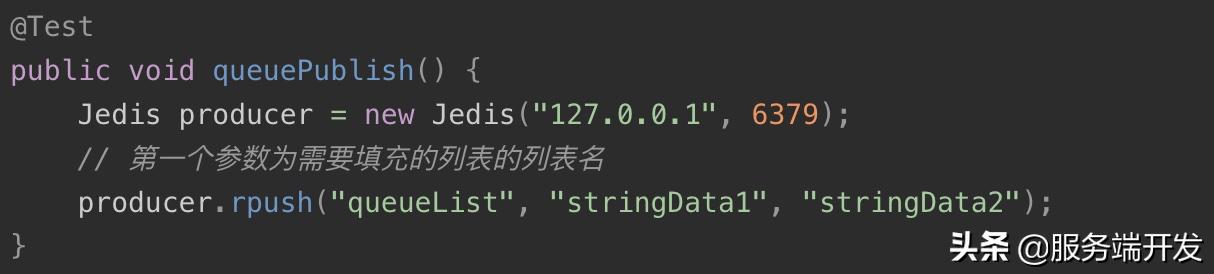
1.消息队列生产者:往列表queueList依次填充了两个数据stringData1和stringData2。
2.消息队列消费者:Jedis的列表的blpop方法是返回类型为Java列表类型,大小为2,其中第一个数据为列表名称,第二个为读取的数据。

打印结果如下:
consumer waiting data... consumer get data: [queueList, stringData1]
3.如下演示队列的消费者使用不是阻塞版本的列表方法和结合while(true)轮询列表来实现:
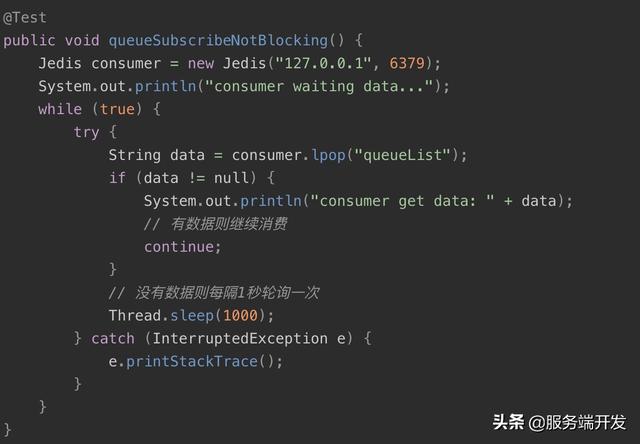
结果打印如下:
consumer waiting data... consumer get data: stringData1 consumer get data: stringData2
三、缺陷分析
虽然可以基于Redis的列表来实现一个轻量级的消息队列,但是这种方式也存在一些不足之处,如下:
1. 消息可靠性
- Redis如果崩溃,则队列消息会丢失,虽然可以通过 持久化 机制来实现崩溃不丢失,不过Redis通常用作缓存,不太适合作为数据存储,因为持久化会对性能造成一定的影响。特别是队列的消息通常具有一定的实时性,所以崩溃恢复后再同步消息意义不大。
2. 内存资源消耗
- 如果生产者填充消息到队列的速度大于消费者消费的速度,则由于Redis的数据是存放在内存的,故会导致内存暴涨。
3. 消息无法广播消费
- Redis队列由于是基于列表实现的,一个消息从队列读出之后就不再存在,所以每个消息只能存在被消费一次。这个特性与 RabbitMQ 的队列类似,RabbitMQ的某个队列可以存在多个消费者,但是队列的消息基于轮询的负载均衡方式将消息分发给这些消费者的,每个消息正常情况下只能被一个消费者成功消费。如果是 Kafka ,则队列的每个消息可以被不同消费者组进行多次消费,即可以通过消费者组的概念来实现广播,而这其中的主要实现原理是Kafka是基于追加方式顺序添加数据到这个文件进行数据存储的,在这个文件内通过维护读取索引的方式来模拟队列功能,所以每个消费者可以维护一个独立的读取索引来进行多次消费。


