点关注,不迷路;持续更新Java相关技术及资讯!!!
个人技术公众号:Java耕耘者

Mysql 事务一致性理解
一致性是指数据处于一种语义上的有意义且正确的状态。一致性是对数据可见性的约束,保证在一个事务中的多次操作的数据中间状态对其他事务不可见的。因为这些中间状态,是一个过渡状态,与事务的开始状态和事务的结束状态是不一致的。
提到事务,你肯定会想到ACID(Atomicity、Consistency、Isolation、Durability,即原子性、一致性、隔离性、持久性),我们就来说说其中I,也就是“隔离性”。
当数据库上有多个事务同时执行的时候,就可能出现脏读(dirty read)、不可重复读(non-repeatable read)、幻读(phantom read)的问题,所以下面我们来说说 隔离级别 。
SQL 标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)、串行化(serializable)。
- 读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
- 读提交指,一个事务提交之后,它做的变更才会被其他事务看到。
- 可重复读指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据时一致的。当然可重复读隔离级别下,未提交变更对其他事务也是不可见的。
- 串行化,顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
MySQL中支持的四种隔离级别
MySQL虽然支持4种隔离级别,但与SQL标准中所规定的各级隔离级别允许发生的问题却有些出入,MySQL在REPEATABLE READ隔离级别下,是可以禁止幻读问题的发生的。
我们可以通过: SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL level; 来设置隔离级别。
其中的level可选值有4个:
level: {
REPEATABLE READ
| READ commit TED
| READ UNCOMMITTED
| SERIALIZABLE
}
MVCC原理
对于使用InnoDB存储引擎的表来说,它的聚簇索引记录中都包含必要的隐藏列:
- trx_id:每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的事务id赋值给trx_id隐藏列。
ReadView
ReadView所解决的问题是使用READ COMMITTED和REPEATABLE READ隔离级别的事务中,不能读到未提交的记录,这需要判断一下版本链中的哪个版本是当前事务可见的。
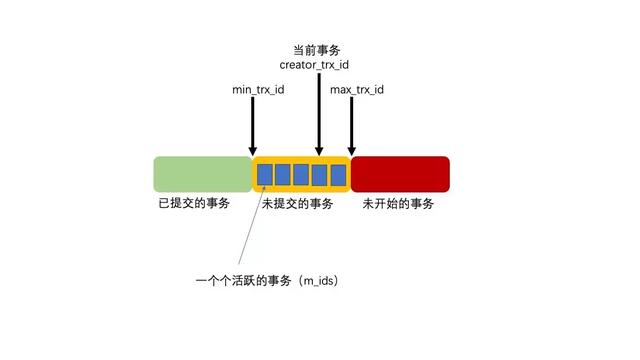
ReadView中主要包含4个比较重要的内容:
- m_ids:表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。
- min_trx_id:表示在生成ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。
- max_trx_id:表示生成ReadView时系统中应该分配给下一个事务的id值。
- creator_trx_id:表示生成该ReadView的事务的事务id。
ReadView是如何工作的?
有了这些信息,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
- 如果被访问版本的trx_id属性值与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
- 如果被访问版本的trx_id属性值小于ReadView中的min_trx_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。
- 如果被访问版本的trx_id属性值大于ReadView中的max_trx_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。
- 如果被访问版本的trx_id属性值在ReadView的min_trx_id和max_trx_id之间,那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。
如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本。如果最后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
在MySQL中,READ COMMITTED和REPEATABLE READ隔离级别的的一个非常大的区别就是它们 生成ReadView的时机 不同。
我们这里使用一个示例来解释:
mysql> CREATE TABLE `t` ( `id` int(11) NOT NULL, `k` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; insert into t(id, k) values(1,1) ;
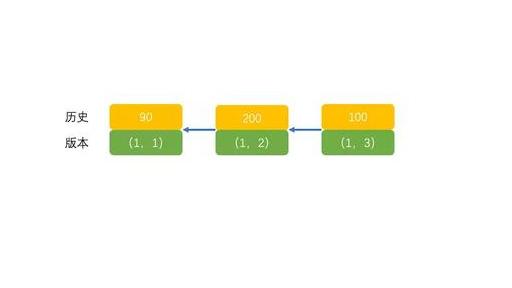
事务A 事务B begin begin update t set k= k+1 where id=1; commit; update t set k = k+1 where id=1; select k from t where id =1; commit; 在这个例子中,我们做如下假设:
- 事务A、B的版本号分别是100、200,且当前系统里只有这3个事务;
- 三个事务开始前,(1,1)这一行数据的row trx_id是90。
READ COMMITTED —— 每次读取数据前都生成一个ReadView
继续上面的例子,假设现在有一个使用READ COMMITTED隔离级别的事务开始执行:
# 使用READ COMMITTED隔离级别的事务 BEGIN; # SELECT1:Transaction 100、200未提交 select k from t where id=1 ; # 得到值为1
这个SELECT1的执行过程如下:
- 在执行SELECT语句时会先生成一个ReadView,ReadView的m_ids列表的内容就是[100, 200],min_trx_id为100,max_trx_id为201,creator_trx_id为0。
- 然后从版本链中挑选可见的记录,最新的版本trx_id值为200,在m_ids列表内,所以不符合可见性要求
- 下一个版本的trx_id值也为100,也在m_ids列表内,所以也不符合要求,继续跳到下一个版本。
- 下一个版本的trx_id值为90,小于ReadView中的min_trx_id值100,所以这个版本是符合要求的。
之后,我们把事务B的事务提交一下,然后再到刚才使用READ COMMITTED隔离级别的事务中继续查找,如下:
# 使用READ COMMITTED隔离级别的事务 BEGIN; # SELECT1:Transaction 100、200均未提交 SELECT * FROM hero WHERE number = 1; # 得到值为1 # SELECT2:Transaction 200提交,Transaction 100未提交 SELECT * FROM hero WHERE number = 1; # 得到值为2
这个SELECT2的执行过程如下:
- 在执行SELECT语句时会又会单独生成一个ReadView,该ReadView的m_ids列表的内容就是[100](事务id为200的那个事务已经提交了,所以再次生成快照时就没有它了),min_trx_id为100,max_trx_id为201,creator_trx_id为0。
- 然后从版本链中挑选可见的记录,从图中可以看出,最新版本trx_id值为100,在m_ids列表内,所以不符合可见性要求
- 下一个版本的trx_id值为200,小于max_trx_id,并且不在m_ids列表中,所以可见,返回的值为2
REPEATABLE READ —— 在第一次读取数据时生成一个ReadView 假设现在有一个使用REPEATABLE READ隔离级别的事务开始执行:
# 使用REPEATABLE READ隔离级别的事务 BEGIN; # SELECT1:Transaction 100、200未提交 SELECT * FROM hero WHERE number = 1; # 得到值为1
这个SELECT1的执行过程如下:
- 在执行SELECT语句时会先生成一个ReadView,ReadView的m_ids列表的内容就是[100, 200],min_trx_id为100,max_trx_id为201,creator_trx_id为0。
- 然后从版本链中挑选可见的记录,该版本的trx_id值为100,在m_ids列表内,所以不符合可见性要求
- 下一个版本该版本的trx_id值为200,也在m_ids列表内,所以也不符合要求,继续跳到下一个版本。
- 下一个版本的trx_id值为90,小于ReadView中的min_trx_id值100,所以这个版本是符合要求的。
之后,我们把事务B的事务提交一下 然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找:
# 使用REPEATABLE READ隔离级别的事务 BEGIN; # SELECT1:Transaction 100、200均未提交 SELECT * FROM hero WHERE number = 1; # 得到值为1 # SELECT2:Transaction 200提交,Transaction 100未提交 SELECT * FROM hero WHERE number = 1; # 得到值为1
这个SELECT2的执行过程如下:
- 因为当前事务的隔离级别为REPEATABLE READ,而之前在执行SELECT1时已经生成过ReadView了,所以此时直接复用之前的ReadView,之前的ReadView的m_ids列表的内容就是[100, 200],min_trx_id为100,max_trx_id为201,creator_trx_id为0。
- 然后从版本链中挑选可见的记录,该版本的trx_id值为100,在m_ids列表内,所以不符合可见性要求
- 下一个版本该版本的trx_id值为200,也在m_ids列表内,所以也不符合要求,继续跳到下一个版本。
- 下一个版本的trx_id值为90,小于ReadView中的min_trx_id值100,所以这个版本是符合要求的。
二,一致性和原子性的区别
原子性和一致性的的侧重点不同:原子性关注状态,要么全部成功,要么全部失败,不存在部分成功的状态。
而一致性关注数据的可见性,中间状态的数据对外部不可见,只有最初状态和最终状态的数据对外可见
三,扩展
隔离性是多个事务的时候, 相互不能干扰,一致性是要保证操作前和操作后数据或者数据结构的一致性,而我提到的事务的一致性是关注数据的中间状态,也就是一致性需要监视中间状态的数据,如果有变化,即刻回滚
四、更多应用
Mysql处理高并发,防止库存超卖
今天王总又给我们上了一课,其实mysql处理高并发,防止库存超卖的问题,在去年的时候,王总已经提过;但是很可惜,即使当时大家都听懂了,但是在现实开发中,还是没这方面的意识。今天就我的一些理解,整理一下这个问题,并希望以后这样的课程能多点。
先来就库存超卖的问题作描述:一般电子商务网站都会遇到如团购、秒杀、特价之类的活动,而这样的活动有一个共同的特点就是访问量激增、上千甚至上万人抢购一个商品。然而,作为活动商品,库存肯定是很有限的,如何控制库存不让出现超买,以防止造成不必要的损失是众多电子商务网站程序员头疼的问题,这同时也是最基本的问题。
从技术方面剖析,很多人肯定会想到事务,但是事务是控制库存超卖的必要条件,但不是充分必要条件。
举例:
总库存:4个商品
请求人:a、1个商品 b、2个商品 c、3个商品
程序如下:
beginTranse(开启事务)
try{
$result = $dbca->query('select amount from s_store where postID = 12345');
if(result->amount > 0){
//quantity为请求减掉的库存数量
$dbca->query('update s_store set amount = amount - quantity where postID = 12345');
}
}catch($e Exception){
rollBack(回滚)
}
commit(提交事务)
以上代码就是我们平时控制库存写的代码了,大多数人都会这么写,看似问题不大,其实隐藏着巨大的漏洞。数据库的访问其实就是对磁盘文件的访问,数据库中的表其实就是保存在磁盘上的一个个文件,甚至一个文件包含了多张表。例如由于高并发,当前有三个用户a、b、c三个用户进入到了这个事务中,这个时候会产生一个共享锁,所以在select的时候,这三个用户查到的库存数量都是4个,同时还要注意,mysql innodb查到的结果是有版本控制的,再其他用户更新没有commit之前(也就是没有产生新版本之前),当前用户查到的结果依然是就版本;
然后是update,假如这三个用户同时到达update这里,这个时候update更新语句会把并发串行化,也就是给同时到达这里的是三个用户排个序,一个一个执行,并生成排他锁,在当前这个update语句commit之前,其他用户等待执行,commit后,生成新的版本;这样执行完后,库存肯定为负数了。但是根据以上描述,我们修改一下代码就不会出现超买现象了,代码如下:
beginTranse(开启事务)
try{
//quantity为请求减掉的库存数量
$dbca->query('update s_store set amount = amount - quantity where postID = 12345');
$result = $dbca->query('select amount from s_store where postID = 12345');
if(result->amount < 0){
throw new Exception('库存不足');
}
}catch($e Exception){
rollBack(回滚)
}
commit(提交事务)
另外,更简洁的方法:
beginTranse(开启事务)
try{
//quantity为请求减掉的库存数量
$dbca->query('update s_store set amount = amount - quantity where amount>=quantity and postID = 12345');
}catch($e Exception){
rollBack(回滚)
}
commit(提交事务)
=======================================================
1、在秒杀的情况下,肯定不能如此高频率的去读写数据库,会严重造成性能问题的
必须使用 缓存 ,将需要秒杀的商品放入缓存中,并使用锁来处理其并发情况。当接到用户秒杀提交订单的情况下,先将商品数量递减(加锁/解锁)后再进行其他方面的处理,处理失败在将数据递增1(加锁/解锁),否则表示交易成功。
当商品数量递减到0时,表示商品秒杀完毕,拒绝其他用户的请求。
2、这个肯定不能直接操作数据库的,会挂的。直接读库写库对数据库压力太大,要用缓存。
把你要卖出的商品比如10个商品放到缓存中;然后在memcache里设置一个计数器来记录请求数,这个请求书你可以以你要秒杀卖出的商品数为基数,比如你想卖出10个商品,只允许100个请求进来。那当计数器达到100的时候,后面进来的就显示秒杀结束,这样可以减轻你的服务器的压力。然后根据这100个请求,先付款的先得后付款的提示商品以秒杀完。
3、首先,多用户并发修改同一条记录时,肯定是后提交的用户将覆盖掉前者提交的结果了。
这个直接可以使用加锁机制去解决, 乐观锁 或者悲观锁。
乐观锁:,就是在数据库设计一个版本号的字段,每次修改都使其+1,这样在提交时比对提交前的版本号就知道是不是并发提交了,但是有个缺点就是只能是应用中控制,如果有跨应用修改同一条数据乐观锁就没办法了,这个时候可以考虑悲观锁。
悲观锁:,就是直接在数据库层面将数据锁死,类似于oralce中使用select xxxxx from xxxx where xx=xx for update,这样其他线程将无法提交数据。
除了加锁的方式也可以使用接收锁定的方式,思路是在数据库中设计一个状态标识位,用户在对数据进行修改前,将状态标识位标识为正在编辑的状态,这样其他用户要编辑此条记录时系统将发现有其他用户正在编辑,则拒绝其编辑的请求,类似于你在操作系统中某文件正在执行,然后你要修改该文件时,系统会提醒你该文件不可编辑或删除。
4、不建议在数据库层面加锁,建议通过服务端的内存锁(锁主键)。当某个用户要修改某个id的数据时,把要修改的id存入memcache,若其他用户触发修改此id的数据时,读到memcache有这个id的值时,就阻止那个用户修改。
5、实际应用中,并不是让mysql去直面大并发读写,会借助“外力”,比如缓存、利用主从库实现读写分离、分表、使用队列写入等方法来降低并发读写。
悲观锁和乐观锁
首先,多用户并发修改同一条记录时,肯定是后提交的用户将覆盖掉前者提交的结果了。这个直接可以使用加锁机制去解决,乐观锁或者悲观锁。
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
两种锁各有优缺点,不能单纯的定义哪个好于哪个。乐观锁比较适合数据修改比较少,读取比较频繁的场景,即使出现了少量的冲突,这样也省去了大量的锁的开销,故而提高了系统的吞吐量。但是如果经常发生冲突(写数据比较多的情况下),上层应用不不断的retry,这样反而降低了性能,对于这种情况使用悲观锁就更合适。
实战
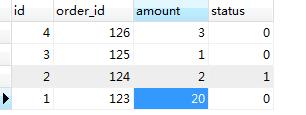
对这个表的 amount 进行修改,开两个命令行窗口
第一个窗口A;
SET AUTOCOMMIT=0; BEGIN WORK; SELECT * FROM order_tbl WHERE order_id='124' FOR UPDATE;
第二个窗口B:
# 更新订单ID 124 的库存数量 UPDATE `order_tbl` SET amount = 1 WHERE order_id = 124;
我们可以看到窗口A加了事物,锁住了这条数据,窗口B执行时会出现这样的问题:
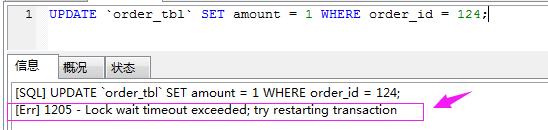
第一个窗口完整的提交事物:
SET AUTOCOMMIT=0; BEGIN WORK; SELECT * FROM order_tbl WHERE order_id='124' FOR UPDATE; UPDATE `order_tbl` SET amount = 10 WHERE order_id = 124; COMMIT WORK;
本文到这里就结束了,喜欢的朋友可以帮忙转发和关注一下,感谢支持!
为了感谢支持我的朋友!整理了一份Java高级架构资料、Spring源码分析、Dubbo、Redis、Netty、zookeeper、Spring cloud、分布式等资料关注私信:555领取
个人技术公众号:Java耕耘者