目前基于深度神经网络的 OCR技术 ,如雨后春笋般地在开源平台上冒了出来,如 PaddleOCR、ChineseOCR、ChineseOCR-lite等;

通过实际搭建比对,存在如下不足:
- 识别速度方面(普通服务器:8核、16G内存的场景下),一张A4的图片,内容丰富情况下,通常一张图片识别速度≥30S
- 图片的角度对识别内容有较大的影响;正常的拍摄角度,识别出来的内容不会乱序,而旋转90度后,识别效果较差;
- 跨平台能力、多语言支持较差,通常只支持 python 、C++,其他语言需要通过相关协议衔接,如Http Restful接口协议等;
- 模型优化更新慢;通常部分开源产品,可能是大厂KPI的产品,存在长时间不更新的情况,而小白本身又不具备优化能力,因此,也是让产品无法进入实用化场景;
今天说的的 OCR 开源平台 RapidOCR ,支持使用 python/c++/ JAVA / swift /c# 各类语言,并提供对应的SDK,支持离线部署或编译;并支持X86/ARM架构的跨平台移植;
平台基本每个月都会针对模型识别准确度、识别效率与速度进行相关优化,并发布相关的模型包;
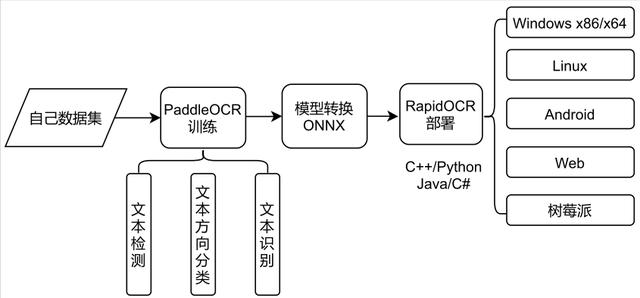
系统整体架构过程
官方提供的工程示例(C++、Java、.Net、Android、Python等):
RapidOCR
├── android # 安卓工程目录
├── api4cpp # c语言跨平台接口库源码目录,直接用根下的 CMake lists.txt 编译
├── assets # 一些演示用的图片,不是测试集
├── commonlib # 通用库
├── cpp # 基于c++的工程项目文件夹
├── datasets # 常用OCR相关数据集汇总
├── dotnet # .Net程序目录
├── FAQ.md # 一些问答整理
├── images # 测试用图片,两张典型的测试图,一张是自然场景,另一个为长文本
├── include # 编译c语言接口库时的头文件目录
├── ios # 苹果手机平台工程目录
├── jvm # 基于java的工程目录
├── lib # 编译用库文件目录,用于编译 c语言 接口库用,默认并不上传二进制文件
├── ocrweb # 基于python和Flask web
├── python # python推理代码目录
├── release # 发布的sdk
└── tools # 一些转换脚本之类 安装部署方式( Docker 方式,这里贡献Dockerfile):
FROM python:3.7-slim
MAINTAINER "frank"
# 替换源
RUN apt-get update
&& apt-get install -y g++ gcc python3-opencv
&& apt-get clean
# && rm -rf /var/lib/apt/lists/*
ENV PIPURL "#34;
WORKDIR /opt/ocr
COPY . .
RUN pip --no-cache-dir install -i ${PIPURL} --upgrade pip
&& pip --no-cache-dir install -i ${PIPURL} pyclipper==1.2.0 Shapely==1.7.1 onnxruntime==1.7.0 opencv_python==4.5.1.48 six==1.15.0 numpy==1.19.2 Pillow==8.3.0 flask
EXPOSE 9003
WORKDIR /opt/ocr/ocrweb
CMD python main.py 脚本 示例:
- Python版本(其他版本暂不列举)
# 支持 对图片 文本检测+方向分类+文本识别
from ch_ppocr_mobile_v2_cls import TextClassifier
from ch_ppocr_mobile_v2_det import TextDetector
from ch_ppocr_mobile_v2_rec import TextRecognizer
det_model_path = 'models/ch_ppocr_mobile_v2.0_det_infer.onnx'
cls_model_path = 'models/ch_ppocr_mobile_v2.0_cls_infer.onnx'
rec_model_path = 'models/ch_ppocr_mobile_v2.0_rec_infer.onnx'
image_path = r'test_images/det_images/1.jpg'
text_sys = TextSystem(det_model_path,
rec_model_path,
use_angle_cls=True,
cls_model_path=cls_model_path)
dt_boxes, rec_res = text_sys(image_path)
visualize(image_path, dt_boxes, rec_res) 通过实践,相同内容的图片,采用 RapidOCR 的模型识别,速度上,基本≤5s返回识别结果;
识别示例:
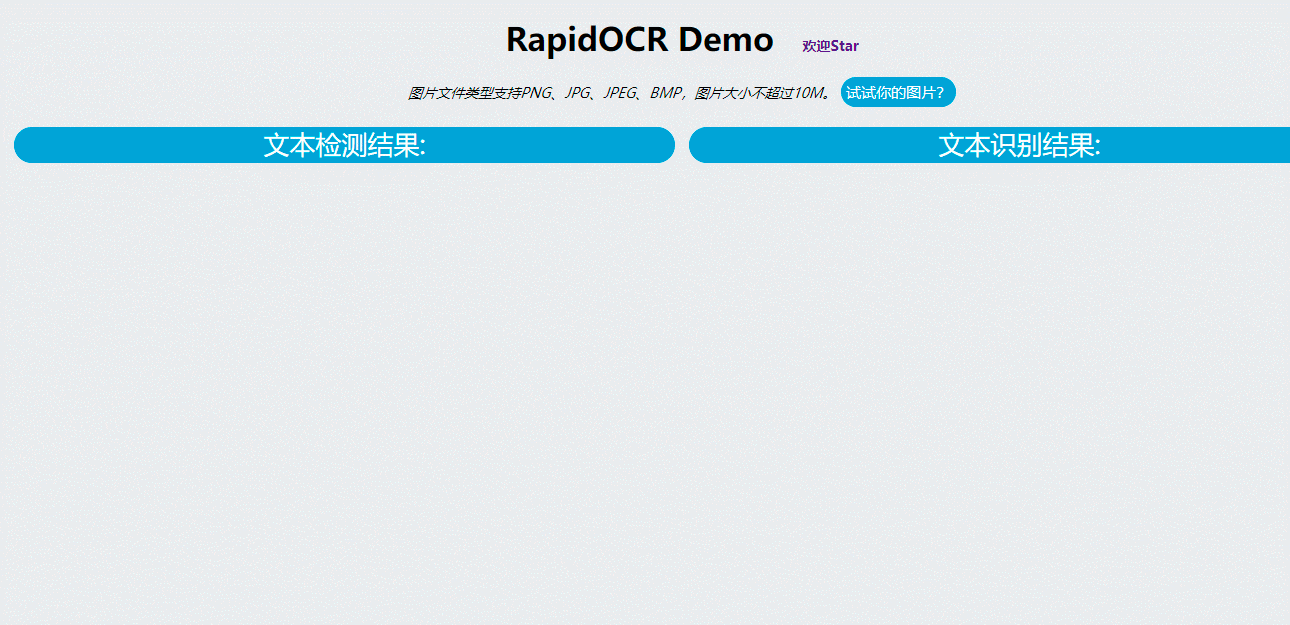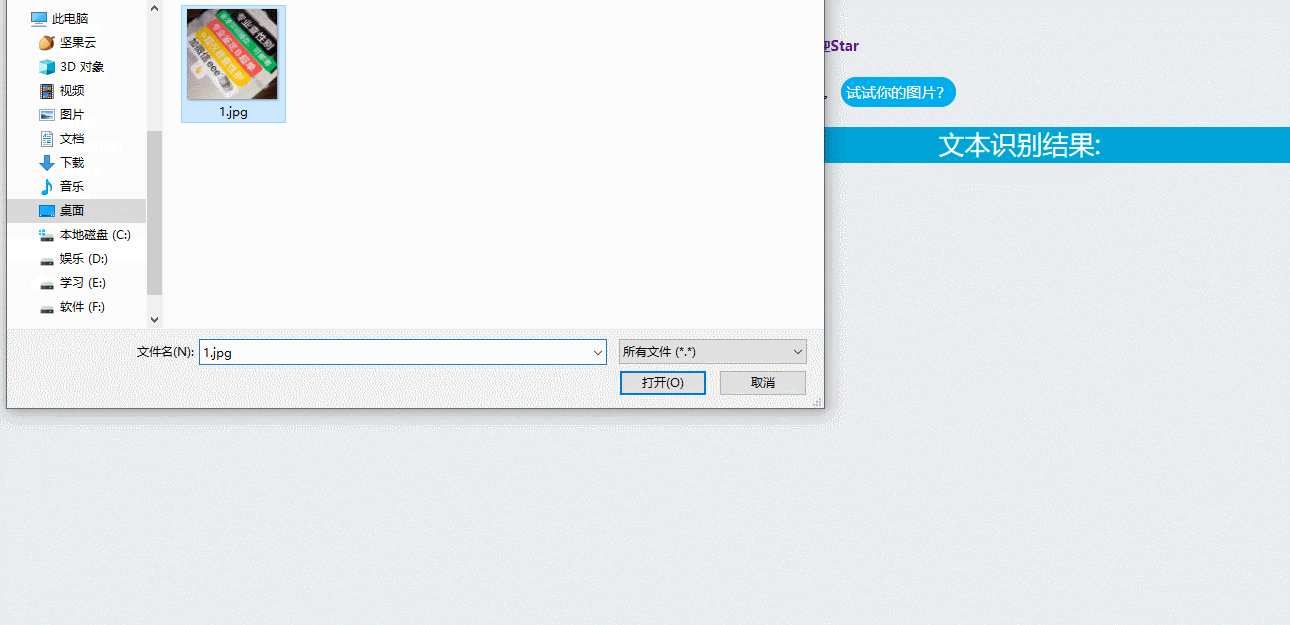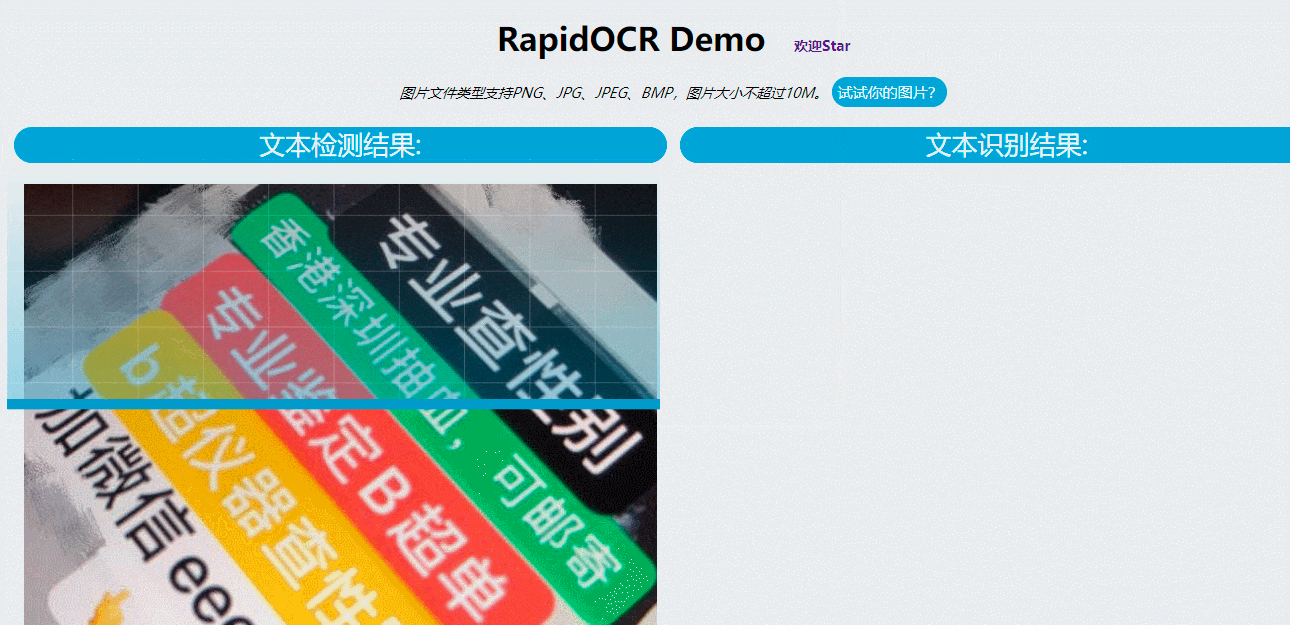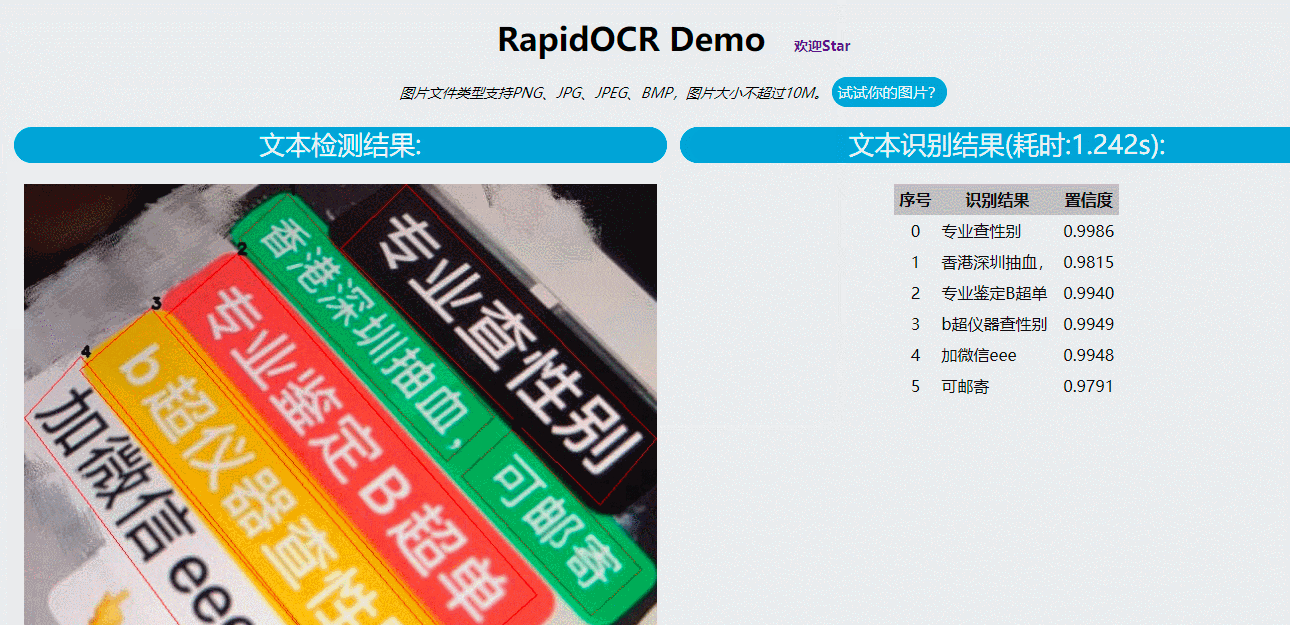
动态识别图片

C++、JAVA 识别展示

.net 识别展示
相关问题,欢迎留言提问;欢迎大家点赞、关注、收藏~


