本文目录:

1 Fork/Join概述
Fork/Join是JDK中提供的类似Map/Reduce的并行计算的实现;它主要处理那些可以递归的分解成更小作业的作业。 与Map/Reduce类似,它也分成两个过程:
Fork:大的作业被分成很多小的作业分别提交到 线程池 中执行;
Join:小作业完成后通过Join操作合并每个作业的执行结果;
其执行过程如下:

Fork/Join采用工作窃取算法业充分利用每个线程;每个线程可能被分配多个任务;当分配给某个线程的任务全部执行完成时,它将会窃取原本分配给其它线程的任务并执行,这样能尽量提高计算效率。
说明 关于工作窃取,按上面所述的10000个数的计算操作,也可以这样理解:A线程被分配了100个数据的计算任务,这100个数的任务又可能被细分成更小粒度的10个数的计算任务;这些子任务都是分配给A来执行的;假设分配给另外的B线程的任务已经执行完成,而A中还剩下有子任务未执行完成,那B会从A的队列中取得未执行的子任务来执行。
Fork/Join计算框架的核心是ForkJoinPool这个类,它继承自AbstractExecutorService类,实现了工作窃取算法。而ForkJoinTask的任务可以被提交到ForkJoinPool中执行。
2 示例
先以一简单的例子来说明Fork/Join如何使用。 以第一节中所述的例子来演示,计算10000个数的和。



Fork/Join过程实际就是一个递归的过程。上述代码中,最核心的部分就在exec方法中,当需要计算的数据量大于一个阈值时,Fork/Join过程就会生效:
Fork:将需要计算的数据分成两部分,每一部分生成一个子任务(在这里是新的MyForkJoinTask任务),分别计算队列中的一半数据,然后使用invokeAll将新生成的子任务提交运行; 子任务运行起来后又会调用子任务的exec过程,此时会再次检测是否要生成新的子任务。
Join: 使用get方法等待每个子任务完成后获取其计算结果,然后将两部分计算结果合并起来。
这样原本的计算被一层层的分成了很多的子任务,直到最后每个子任务队列中计算的数据量小于某个阈值时才不会继续细分。这就是Fork/Join的过程。
说明 在本例中,进行Fork时,将需要计算的数据分成了两部分,然后新起两个子任务分别进行计算;实际上也可以在此处生成多个子任务,这样能够减少递归的层次,提高运算效率;相应的代码复杂度上会有所上升。
3 详解
先来看下Fork/Join中所涉及的类:
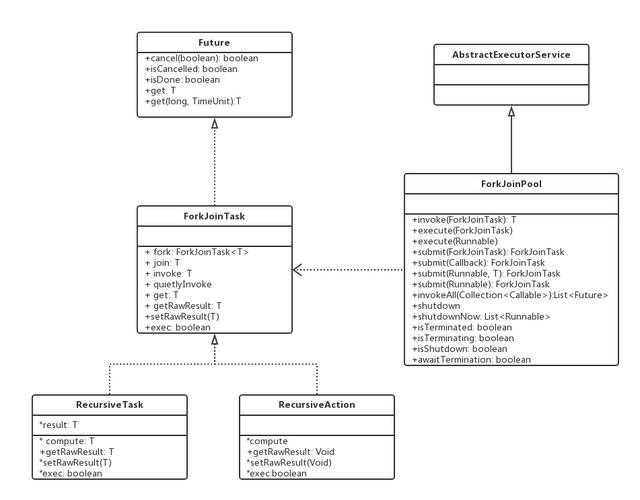
3.1 ForkJoinPool
从类图中可以看出,ForkJoinPool是AbstractExecutorService的一个子类;它与其它的ExecutorService不一样的地方在于它的工作窃取机制:每一个池中的线程,都会尝试从池中获取提交到池中执行的任务或者是获取其它任务产生的子任务来执行。
ForkJoinPool中提供了一个默认的实现commonPool,可以满足多数场景下的使用。可以通过commonPool() 静态方法 直接获取到。
除此之外,ForkJoinPool还可以通过构造函数直接创建。
它包含有一些关键的参数,在优化其执行性能的时候可能会使用到:
parallelism:可同时执行的线程个数,默认情况下数目与可以使用的CPU核心数是一样的;
corePoolSize:池中保持的线程数;一般情况下与parallelism一样,但在某些场景下如运行线程可能被阻塞时可以将其设置成比parallelism大;如果设置成比parallelism小时,将使用默认值也就是parallelism的值。
maximumPoolSize:池中最多保持的线程数;
minimumRunnable:正在运行而不被阻塞的最小线程数目,如果达到这个数目时,将会针对池中的任务创建新的线程来执行。
ForkJoinPool包含的一些有可能会使用到的方法:
| 方法 | 说明 |
|---|---|
| invoke(ForkJoinTask): T | 执行提交的任务,等待其计算完成并返回计算结果,执行失败时,将会抛出运行时异常。 |
| execute(ForkJoinTask) | 提交任务到池中,提交成功后不等待其执行结果直接返回,一般提交无返回结果的任务 |
| submit(ForkJoinTask): ForkJoinTask | 提交一个任务执行,返回的是该提交的任务本身 |
| shutdown | 等待池子中的任务完全执行完成后再退出;在此过程中不再接收新的任务 |
| shutdownNow | 立即停止池子,尝试停止或取消所有池子中的任务,并且不再接收新的任务 |
一般情况下,如果任务有返回结果使用invoke提交任务并等待其处理完成返回结果;如果无返回结果就可以直接使用execute方法提交待运行的任务。
3.2 ForkJoinTask
当一个ForkJoinTask被提交到ForkJoinPool中后,它即开始运行。此时它会启动其它的子任务。具体示例见第二节。 ForkJoinTask是一个 抽象类 ,有以下抽象方法:
setRawResult: 设置计算结果;
getRawResult: 获取计算结果,即使计算过程中出现某些异常,也可以返回一个由setRawResult指定的结果;当计算结果未完成时,将返回null;
exec: 执行实际的计算过程;主要的计算逻辑需要实现在这个函数中;一般情况下直接指定返回True就可以了;
在继承ForkJoinTask类时,需要实现这三个方法;注意这三个方法是提供给继承的时候使用的,实际上会在ForkJoinTask抽象类中的某些函数中使用到这三个方法,它们并不是直接提供给外部调用的。
在继承时,如第二节中的示例,一般过程是这样的:
在子类中新建一个变量存储计算结果
实现setRawResult与getRawResult,来设置结果变量的值与获取结果变量的值
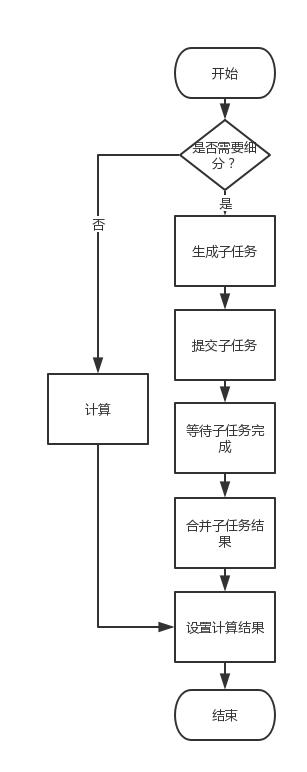
实现exec方法,即实际的计算过程:一般是看当前任务是否足够小不需要再创建子任务了,如果不需要就直接计算,需要的话就根据一定的规则创建子任务,然后再等待所有子任务执行完成后再收集所有子任务的计算结果,最终调用setRawResult来设置计算结果到结果变量中。这样后续就可以通过ForkJoinTask提供的方法获取计算结果了。 其流程大致如下图:
ForkJoinTask还有一些经常会使用到的静态方法,清单如下表:
| 方法 | 说明 |
|---|---|
| invokeAll(ForkJoinTask, ForkJoinTask) | 执行提交的两个任务,并等待两个任务都执行完成;如果某个任务执行出现异常,那么会将异常信息包含在一个运行时异常里面并抛出该异常; |
| invokeAll(ForkJoinTask… | 与上一方法类似,用于执行多个任务 |
| invokeAll( Collection <ForkJoinTask>): Collection<T> | 执行多个任务,并返回每个结果组成的集合 |
这个类的实现令人较为费解,主要是setRawResult与getRawResult两个方法的实现上,如果不去了解ForkJoinTask内部是如何调用这两个方法的,理解上就会有些困难。可以不用太关注这个类,因为JDK中提供了它的使用起来更加简单的子类:RecursiveAction与RecursiveTask。
3.3 RecursiveAction与RecursiveTask
RecursiveAction与RecursiveTask在ForkJoinTask的基础上进行了进一步的封装,它们有一个名称一样的抽象方法:compute,不同的是RecursiveAction中该方法的返回值是void类型的,而RecursiveTask的返回类型是T类型。 也就是说,RecursiveAction主要使用在无返回结果的计算中;而RecursiveTask用于有返回结果的计算。
第二节中计算使用RecursiveTask实现如下:

这样的实现就比直接使用ForkJoinTask要方便并且容易理解的多。因此一般情况下都可以直接使用这两个类。
本文为 Java 并发方面的系列文章之一,感兴趣的可以移步本人头条空间查看Java并发其它文章,后续新的文章也将会陆续发布,欢迎关注及拍砖。 往期:
《Java并发基础-线程状态及转换》
《Java并发基础-Condition使用必知必会》
《Java并发基础-你不一定知道的线程(Thread)特性》
《Java并发基础-锁详细分析(可重入锁、读写锁、信号量等)》


