连更中,多谢大佬们的关注!小架会努力更新哒~
cpu cache的优化:解决伪共享问题
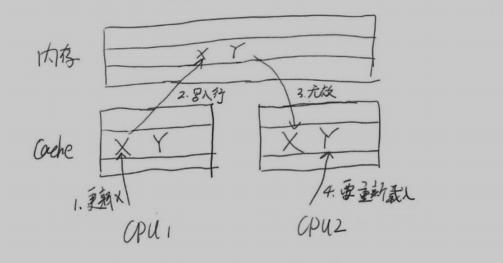
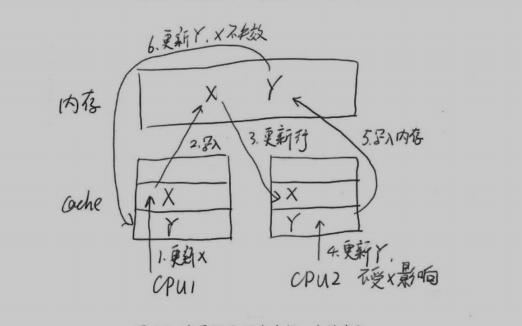
cpu的高速 缓存 : 读写数据最小单位为缓存行,它从主存赋值到缓存的最小单位,一般为32字节到128字节
伪共享问题: 当两个变量放在一个缓存行时,在多线程访问中,可能会影响彼此的性能.假如变量X和Y在同一个缓存行,运行在CPU1上的新城更新了X,那么cpu2上的缓存行就会失效,,同一行的Y即使没有修改也会变成无效,导致cache无法命中.
解决方案:为避免此类问题,需要把X的前后空间都占据一定的饿位置(padding,作填充用)
代码:
public final class FalseSharing implements Runnable {
public final static int NUM_ Thread S = 8; // 此处填入逻辑处理器数量,本机为4核8 线程
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
static {
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
}
public FalseSharing(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
final long start = System.currentTimeMillis();
runTest();
System.out.println("duration = " + (System.currentTimeMillis() - start));
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
//JDK 7 某些版本 和 JDK 8中 会把不用的数据优化 导致 这种优化手段失效
// Unlock: -XX:-RestrictContended (JDK 8 option)
//@sun.misc.Contended
public final static class VolatileLong {
public volatile long value = 0L; //8个字节
public long p1, p2, p3, p4, p5, p6 , p7 = 8L; // 56个字节,此处是作为padding而存在
}
}
//输出结果: 3801
//当注释掉p1, p2, p3, p4, p5, p6, p7时 结果为23038,明显时间长很多
Dispruptor框架充分考虑到了这个问题,核心组件 Sequence 会被频繁访问(每次入队,Sequence+1),其结构如下:
class LhsPadding {
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding {
protected volatile long value;
}
class RhsPadding extends Value {
protected long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding {
} //Sequence主要使用的value,LhsPadding和RhsPadding在这个value前后安置了一些占位空间,使得value可以无冲突地存在于缓存中.
注意: RingBuffer中实际产生的数组打下是缓冲区实际大小再加上两倍的BUFFER_PAD.
Future 模式
Future模式是多线程开发中非常常见的一种设计模式,核心思想是异步调用
Future模式的简单实现
核心接口Data: 客户端希望获得的数据. RealData : 真实数据,最终希望获得的数据 FutureData : 提取RealData的凭证,可立刻返回
public interface Data {
public String getResult();
}
public class FutureData implements Data {
protected RealData realdata = null;
protected boolean isReady = false;
public synchronized void setRealData(RealData realdata) {
if (isReady) {
return;
}
this.realdata = realdata;
isReady = true;
notifyAll(); //等realdata注入完后,通知getresult()方法
}
public synchronized String getResult() { //等待realdata构造完成
while (!isReady) {
try {
wait(); //当调用result时,为准备好数据时阻塞住线程
} catch (InterruptedException e) {
}
}
return realdata.result;
}
}
public class RealData implements Data {
protected final String result;
public RealData(String para) {
//RealData的构造可能很慢,需要用户等待很久
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 10; i++) {
sb.append(para);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
}
result = sb.toString();
}
public String getResult() {
return result;
}
}
public class Client {
public Data request(final String queryStr) {
final FutureData future = new FutureData();
// RealData的构建很慢
new Thread() {
public void run() {
RealData realdata = new RealData(queryStr);
future.setRealData(realdata);
}
}.start();
return future;
}
}
public class Main {
public static void main(String[] args) {
Client client = new Client();
Data data = client.request("a");
System.out.println("请求完毕");
try {
//这里可以用一个sleep代替了对其它业务逻辑的处理
Thread.sleep(2000);
} catch (InterruptedException e) {
}
//使用真实的数据
System.out.println("数据 = " + data.getResult());
}
}
JDK中的Future
ExecutorService executorService = Executors.newFixedThreadPool(10);
Future<?> future = executorService.submit(() -> {
try {
Thread.currentThread().sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
});
future.get(); //需要等待任务完成,get()会阻塞住
System.out.println("处理完毕");
Guava对Future的支持
public class FutrueDemo2 {
public static void main(String args[]) throws InterruptedException {
ListeningExecutorService service = MoreExecutors.listeningDecorator(Executors.newFixedThreadPool(10));
ListenableFuture<String> task = service.submit(new RealData("x"));
Futures.addCallback(task, new FutureCallback<String>() {
public void onSuccess(String o) {
System.out.println("异步处理成功,result=" + o);
}
public void onFailure(Throwable throwable) { //对异常的处理
System.out.println("异步处理失败,e=" + throwable);
}
}, MoreExecutors.newDirectExecutorService());
System.out.println("main task done.....");
Thread.sleep(3000);
}
}
并行流水线
现在要生产一批小玩偶.小玩偶的制作分为四个步骤:第一,组装身体;第二,在身体上安装四肢和头部;第三,给组装完成的玩偶穿上一件漂亮的衣服;第四,包装出 货。为了加快制作进度,我们不可能叫四个人同时加工一个玩具,因为这四个步骤有着严 重的依赖关系。如果没有身体,就没有地方安装四肢;如果没有组装完成,就不能穿衣服; 如果没有穿上衣服,就不能包装发货。因此,找四个人来做一个玩偶是毫无意义的。
但是,如果你现在要制作的不是1个玩偶,而是1万个玩偶,那情况就不同了。你可以找四个人,第一个人只负责组装身体,完成后交给第二个人;第二个人只负责安装头部 和四肢,完成后交付第三人;第三人只负责穿衣服,完成后交付第四人:第四人只负责包 装发货。这样所有人都可以一起工作,共同完成任务,而整个时间周期也能缩短到原来的 14左右,这就是流水线的思想。一旦流水线满载,每次只需要一步(假设一个玩偶需要四 步)就可以产生一个玩偶

在多核或者分布式场景中,这种设计思路可以有效地将有依赖关系的操作分配在不同的线程中进行计算,尽可能利用多核优势.
并行搜索
static int[] arr = { 5, 52, 6, 3, 4, 10, 8, 100, 35, 78, 64, 31, 77, 90,
45, 53, 89, 78, 1,2 };
static ExecutorService pool = Executors.newCachedThreadPool();
static final int Thread_Num=2;
static AtomicInteger result=new AtomicInteger(-1);
public static int search(int searchValue,int beginPos,int endPos){
int i=0;
for(i=beginPos;i<endPos;i++){
if(result.get()>=0){
return result.get();
}
if(arr[i] == searchValue){
//如果设置失败,表示其它线程已经先找到了
if(!result.compareAndSet(-1, i)){
return result.get();
}
return i;
}
}
return -1;
}
并行排序
..
并行算法:矩阵乘法
网络NIO
异步AIO


