之前的文章讲到了 商业智能 BI对数据的同步处理机制主要是采用T+1的方式,这部分数据我们一般把它们叫做离线数据,这些数据来自于各个业务系统。从业务系统批量抽取过来的数据要经过一系列的清洗、转换计算,才能进入商业智能 BI 数仓,并在最后达到分析展现,这个过程是有时间周期的,存在一个时间窗口,所以是非实时的。
商业智能BI的实时要求
通常在商业智能BI项目里面,大部分的分析指标、数据是不要求做到实时的,特别是像企业的经营管理分析、财务分析等等。这些数据在商业智能BI项目中的准确性要求远远大于时效性,所以此类数据隔天看基本上是足以满足企业大部分的业务分析场景的。
数据可视化大屏 – 派可数据商业智能BI可视化分析平台
但在商业智能BI项目里面也有一些例外,比如像实时预警类的、监控类的一些数据指标,对这种数据的实时性要求就会比较高一些,数据延迟时间不能太长,要求达到秒级、分钟级以内,这类数据就需要进行商业智能BI实时处理。这两种不同形态的数据处理方式是不一样的。
商业智能BI离线数据处理
在以往的商业智能BI项目中,离线数据量不大的时候,比如 TB 级别以下,传统的数据仓库 ETL 架构大部分场景都可以满足。数据量大的时候比如TB、 PB 级别或以上的数据处理,底层就可以采用 Hadoop 分布式系统框架,通过集群的方式进行高速运算和存储。最底层的 HDFS 分布式文件系统存储数据, Mapreduce 分布式计算框架对数据进行计算处理。
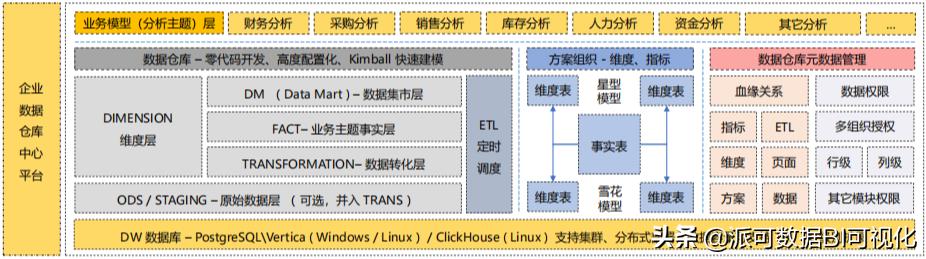
数据仓库 – 派可数据商业智能BI可视化分析平台
Hadoop的数据仓库Hive通过 Hive SQL就是HSQL转换成MapReduce作业任务执行数据查询。Hive清洗处理后的结果如果是面向海量数据随机查询的场景还可以存入 HBase Hadoop Database中。
HBase 是真正的数据库,NoSQL数据库,目的主要是为了支持和弥补Hadoop对实时数据操作的瓶颈。Hive就是一个壳,但它简化了Hadoop的复杂性,不需要学 JAVA 就可以通过 SQL 操作MapReduce去访问HDFS,即通过 SQL语句 像操作关系数据库一样操作HDFS系统中的目录和文件。
上面讲到的就是传统的数据仓库模式下的离线数据处理和大数据架构下的离线数据处理,那么我们再来说下大数据技术下的实时数据仓库的数据处理架构。
商业智能BI实时数据处理
我们之前也研究过很多不同的框架,比如早期的Lambda架构,通过Kafaka、 Flume 组件对底层数据源数据进行收集,然后分两条线进行处理,一条处理实时数据指标,一条处理T+1数据。
数据可视化大屏 – 派可数据商业智能BI可视化分析平台
实时数据指标的计算主要是进入到流式计算平台,像Storm、Flink或者SparkStreaming;非实时的、大批量的数据就进入到批数据离线计算平台,就是前面提到的Hadoop、Mapreduce、Hive 数据仓库去处理非实时性的T+1的指标。这样的一种架构兼顾了小批量的实时性数据和大批量的非实时性数据处理,但运维成本很高,因为是两套分布式系统,维护的工作量很大。
把Lambda架构做简化,去掉了离线批处理部分,就是Kappa架构,数据以流的方式被采集,就只关心流式计算。因为现在的Kafaka是可以支持数据持久化的,可以保存更长时间的历史数据,代替了Lambda架构中离线批处理的部分。但对于历史数据吞吐能力就会有所限制,只能通过增加计算资源来解决。包括数据的容错性,对有些场景也并不非常适合Kappa架构。
我们目前在一些项目上采用的数据实时处理架构,比如使用数据库binlog日志,或者其它 非关系型数据库 产生的流式数据发送到Kafaka或者Flink-CDC,再通过Flink流处理引擎创建表映射、注册表,然后通过Flink引擎提供的FlinkSQL相关接口实现数据流式处理,最终将变化的数据实时写入到BI数据仓库供前端可视化做实时展现和分析。
商业智能BI业务场景需求
除了我上面提到的一些技术解决方案之外,大家在网上也可以看到各种各样的大数据实时处理框架或者解决方案的介绍。就会发现虽然大家都是在讲同一件事,但是实现方式和路径、采用的技术框架各不相同,为什么?因为具体要解决的业务场景不一样。
数据可视化大屏 – 派可数据商业智能BI可视化分析平台
比如有些商业智能BI项目可能就不是一个商业智能BI分析需求,就是一个大屏的实时数据展现,但用户一看大屏可视化,就会认为这个不就是商业智能BI嘛,拿商业智能BI来做。
但实际上 ,这样理解是有问题的,可视化就一定是商业智能BI吗?WEB前端直接开发行不行,是完全可以的。底层使用Flume+Kafaka+Flink+ Redis 架构,再找个 前端开发 就可以设计大屏的实时数据刷新了,跟商业智能BI有什么关系,并没有关系。
商业智能BI的强项不是去做可视化实时数据展现的,商业智能BI的强项是多系统打通、数据仓库建模以及对历史数据的多维分析、钻透、关联等分析路径的实现。
所以,不同的行业、不同的分析型项目数据源各不相同。业务分析场景、数据场景众多,很难用某一种技术框架解决所有的问题。要考虑兼顾数据的时效性,又要考虑兼顾数据的准确性,还有考虑数据量吞吐和处理能力,以及兼顾随时变化的业务计算规则。这么多的场景和要求,很难通过标准化的技术方案去平衡,只能看具体的业务场景再针对性的提供相应的解决办法。
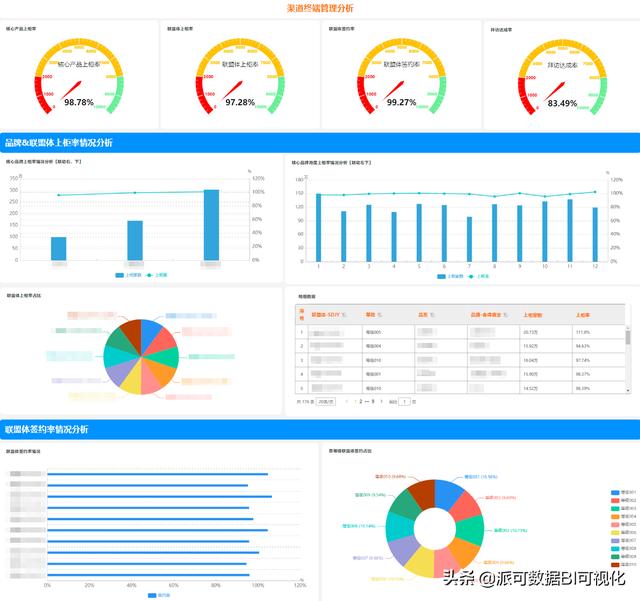
数据可视化 – 派可数据商业智能BI可视化分析平台
所以,大家就比较容易理解为什么商业智能BI分析工具不去提供这种实时数据的处理能力,因为这种实时数据处理的场景是非标的,很难标准化去适应各种复杂的业务场景。
即使商业智能BI有这个能力,也是基于某些特定场景之下的,一定不会适配所有的场景。所以一般商业智能BI都是和这种大数据平台、实时数据处理平台去搭配使用的,针对不同的业务场景设计不同的大数据实时数据处理方案,把数据规范化、标准化、模型化,商业智能BI负责只对接到这一层就可以了。
并且像上面提到的这些过程,投入不会小,特别是后期的运维投入,数据出一点问题就是大问题,到底是哪个环节出的问题?网络延迟的问题,吞吐量处理能力的问题还是资源计算窗口不足的问题,有得折腾了。
商业智能BI实时数据处理总结
不管是离线数据还是实时数据采用什么样的架构都是为了解决特定业务场景下的问题,什么时候采用离线处理、什么时候采用实时处理。除了这些需求的重要性、紧迫度需要评估外,还需要考虑资源的投入。
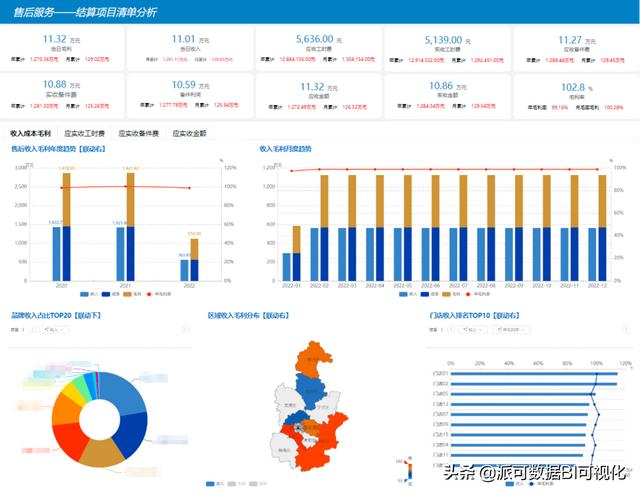
数据可视化 – 派可数据商业智能BI可视化分析平台
企业是用最小的、最经济的资源达成既定的业务目标,而不是为了追求所谓的数据实时而追求实时。做不到实时分析,只做离线就是技术不行、产品不行、能力不行。造子弹跟造 原子弹 都是造弹,但毕竟还不一样。
那也有同学问了,有没有什么比较经济的成本,就想用造子弹的成本来感受一下原子弹的威力。就几个核心的指标,做成准实时的,比如10秒钟、半分钟刷新、刷新行不行?点赞关注收藏,之后会通过系列文章继续解析。


