序
计算机专业的 “三座大山” — “操作系统”, “编译原理” 和 “计算机图形学”, 相信是很多计算机专业同学迈不过去的坎. 其中, “编译原理” 作为上面三个科目中的 “催眠神器”, 更是让无数人栽了跟头.
其中, 编译原理中的两本”圣经”, 龙书和虎书, 不知道其他人读这两本书时候的感受, 反正我自己在读龙书的时候, 翻不了几页就能睡着, 简直是分分钟劝退. 龙书实在是太理论了, 感觉并不是很适合初学者, 而相对”亲民”一些的虎书, 虽然有不少的代码片段, 但是也并没有完整地将它们串起来, 结果上其实和龙书一样看不明白, 云里雾里的.

龙书

虎书
其他国内各种教材上来就是满天飞的正则表达式, 各种自动机理论先咔咔摆出来, 看得我真是满脑子黑人问号.

各种语法错误到底是怎么在编译期间检查出来的?递归下降到底递归了个啥东西,怎么就下降了?
基于此, 为了能够明白这些问题, 翻阅了许多国内外资料, 并将自己的理解进行总结和归纳, 为了兼顾实践, 同时我们需要自己手写一个极简的 解释器 来达到巩固的目的.我暂时选用 Java 语言来实现我们简易的解释器.
整体规划为两大部分
- 第一部分,比较简单,是关于如何做一个四则运算的解释器,在此期间会引入一些基础的相关概念,尽量用最通俗的语言进行解释
- 第二部分,我们来编写一个简易的 DSL,并且编写解释器执行它
可能有同学注意到上面出现了两个名词: “编译器”和”解释器”,现阶段, 可以不要太在意这些东西, 我们可以 不严谨地,甚至有些不正确地 进行如下定义,只要能 get 到这个意思就好
- 编译器是将 源代码 翻译称为目标机器代码
- 解释器则是将源代码执行,解释器并不将其翻译为目标机器代码
那话不多说,我们开搞,不过前期我们慢慢来, 步子不要太大.
同时我也将代码同步到 gitee, 感兴趣的同学可以把代码拉到本地调试哦
今日目标
我们今天的目标是: 能正确运行 “8+9”
正文
为了尽可能地减少干扰,让程序最简单, 我们设置如下限定
- 仅支持单个整数数字
- 仅支持加法
- 禁止在文本中出现空格符
首先我们需要明确思路, 如何实现? 那么仅仅对于”8+9″这个需求, 还是比较简单的:
- 8+9 这个模式可以归纳为: <“整数”,”加号”,”整数”>
- 按单个字符,把 8+9 这个 字符串 拆成一个 字符数组
- 按顺序遍历字符数组, 逐一检查
- 检查通过, 将第一个整数和第二个整数相加, 即可得出结果
为了方便, 我们将字符串中拆出来的字符给”包装”一下, 也就是说除了这个字符本身, 还有一些额外的附加属性, 例如类型,名称,状态等等等等, 我们把包装了每个字符的类型叫做 Token , 针对当前而言, 一个 Token 对应了字符数组的 1 个字符, 后续我们会接触到多个字符代表 1 个 Token 的情况.如下图:
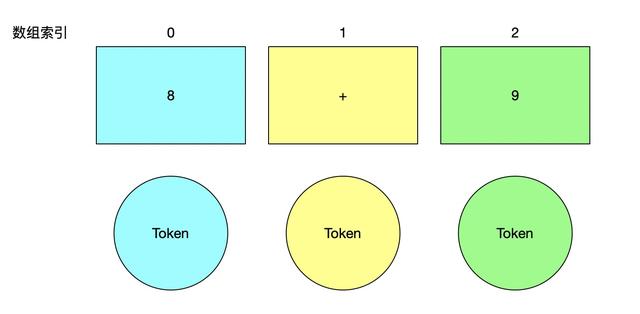
token 对应关系
其实从本质上来说, Token 代表了语法中最小的不可分割的单位, 例如,我们需要的语法是: [时间] + [要描述的事情] + [自身主观的评价] , 那么有这样一句话:
上面这 6 个单字, 概括起来,
我们把它拆分为 3 个 Token, 分别是:
<今天>, <天气>, <不错>
这样拆分的话, 整个句子连起来的语义来才没有问题.
然而假如我们按其他方式拆分的话;
<今>, <天天>, <气不>, <错>
讲道理, 正常会说中文的人都不会这么拆词的, 而且上述拆出来的词并不符合我们上述描述的 “语法”
所以,将一个字符串文本, 拆分为正确的 Token 流的这个过程, 我们称之为 分词 , 那么干这个活儿的程序, 我们就称之为 分词器(lexer)
当前阶段,我们只需要在 Token 中记录类型和实际的值即可, 不需要太多的额外属性, 定义如下
Token.java
package com.interpreter.common;
public class Token {
public String tokenType;
public Object value;
public Token(String tokenType, Object value) {
this.tokenType = tokenType;
this.value = value;
}
public static Token EofToken() {
return new Token( Constant .TOKEN_EOF, null);
}
@Override
public String toString() {
if (this.value == null) {
return "Token<" + tokenType + ", null>";
} else {
return "Token<" + tokenType + "," + value + ">";
}
}
}
所以针对 “8+9” 这个表达式, 我们当前的首要任务是将字符数组转换成一个一个的 Token
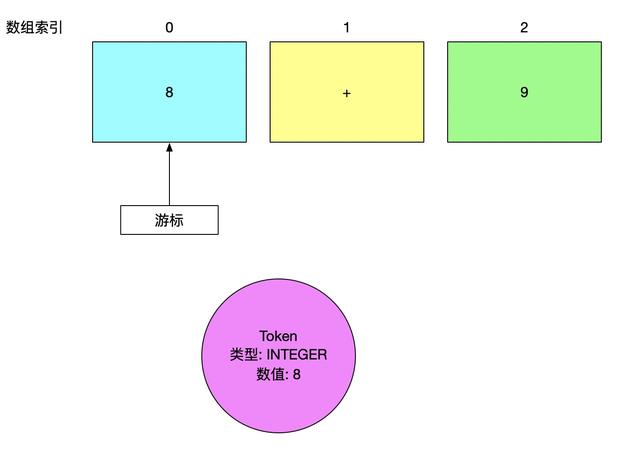
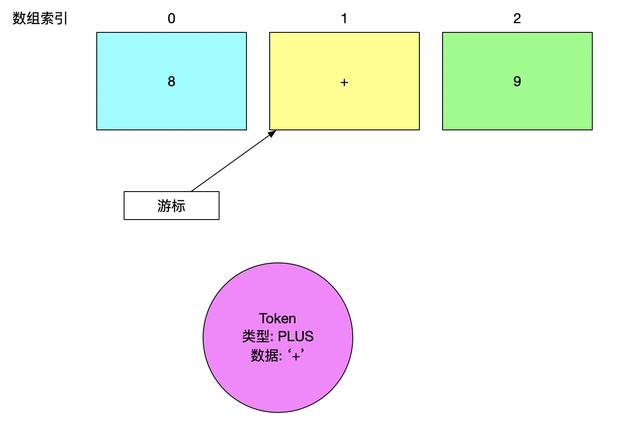

而当我们处理到最后一个字符之后, 下一个字符是不存在的, 这时候我们用特殊的 Token 来标识 这个Token之后就没有数据了, 可以结束解析了,这个特殊的 Token 的名字叫做 EOF (end of file)
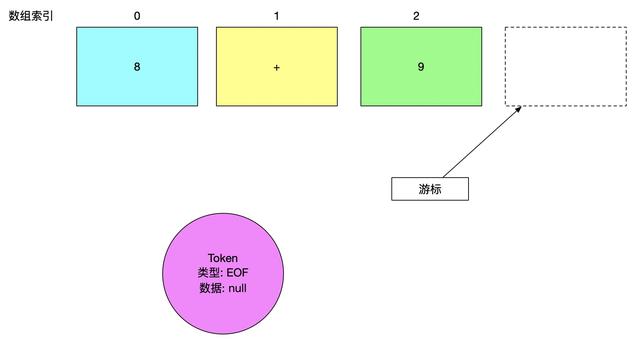
整体逻辑捋顺之后, 下面编写我们的解析器 Interpreter.java
package com.interpreter.part1;
import com.interpreter.common.CommonUtil;
import com.interpreter.common.Constant;
import com.interpreter.common.Token;
import java.math. BigDecimal ;
public class Interpreter {
public String text;
public int pos;
public Token currentToken;
public Interpreter(String text) {
this.text = text;
this.pos = 0;
this.currentToken = null;
}
public void error() {
throw new RuntimeException("解析给定文本出现错误,请检查");
}
// 遍历字符数组, 然后对每个字符进行判断, 将其包装为 Token 之后进行返回
public Token getNextToken() {
if (this.pos > this.text.length() - 1) {
return Token.EofToken();
}
char currentProcessChar = this.text.charAt(this.pos);
// 如果 char 为数字, 则包装为 INTEGER token
if (CommonUtil.isInteger(currentProcessChar)) {
Token token = new Token(Constant.TOKEN_INTEGER, new BigDecimal(String.valueOf(currentProcessChar)));
this.pos++;
return token;
}
// 如果 char 为 + 符号, 则包装为 PLUS token
if (currentProcessChar == '+') {
Token token = new Token(Constant.TOKEN_PLUS, '+');
this.pos++;
return token;
}
// 以上两者都不是, 则证明给定的文本中包含了非法字符, 我们抛出错误, 拒绝执行
this.error();
return null;
}
// 检查当前 token 的类型是不是我们想要的, 如果是我们想要的, 则返回下一个 token
// 如果不是我们预计的 token 类型, 则报错
// 此处可以看做最简单的语法检查
public void checkAndMoveToNext(String tokenType) {
if (this.currentToken.tokenType.equals(tokenType)) {
this.currentToken = this.getNextToken();
} else {
this.error();
}
}
public Object expression() {
this.currentToken = this.getNextToken();
Token left = this.currentToken;
this.checkAndMoveToNext(Constant.TOKEN_INTEGER);
Token op = this.currentToken;
this.checkAndMoveToNext(Constant.TOKEN_PLUS);
Token right = this.currentToken;
this.checkAndMoveToNext(Constant.TOKEN_INTEGER);
return ((BigDecimal)left.value).add((BigDecimal)right.value);
}
public static void main(String[] args) {
String text = "8+9";
Interpreter interpreter = new Interpreter(text);
Object result = interpreter.expression();
System.out.println(result);
}
}
在 IDE 中运行, 应该能看到我们预期的结果 “17”

OK, 今天我们了解到了什么是 Token, 并且对分词有了一个初步的印象, 在下一个章节, 我们来对这个解释器进行升级, 让它支持 N 位数字的加法


