今日目标
我们今天的目标是: 在第 1 部分的基础上,升级为 N 位数的加法

今天的代码已经上传到了 gitee, 感兴趣的同学可以拉下来调试哦
正文
同样的,为了尽可能地保持简单, 我们设置如下限定:
- 支持 N 个整数数字
- 仅支持加法
- 支持在文本中出现任意数量的空格符号
我们还是先来捋顺一下思路, 如何实现呢?
01 – 思路
首先,既然我们这次支持了空格符号, 那么必然的, 我们拿到空格之后,需要跳过这个空格字符,然后继续处理下一个, 因为在当前我们的需求背景下, 空格符号是没有任何意义的, 我们把它叫做”烦人的空格符号”, 如图所示:
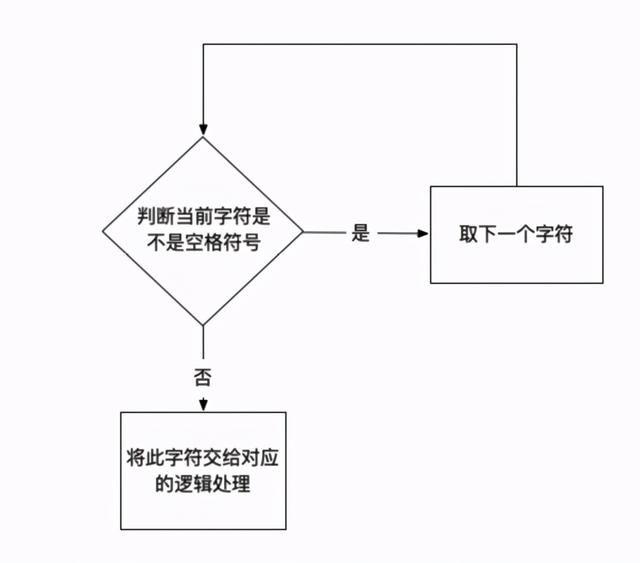
空格符号的处理
同理, 我们在处理数字类型的时候, 不能直接拿当前的字符直接返回了, 而是需要”向前看一看”, 看一看下一个字符是不是数字, 这里就分成了两种情况:
- 如果依然是数字, 则需要累加一位数
- 如果下一位不是数字, 那么直接返回当前组装的数字
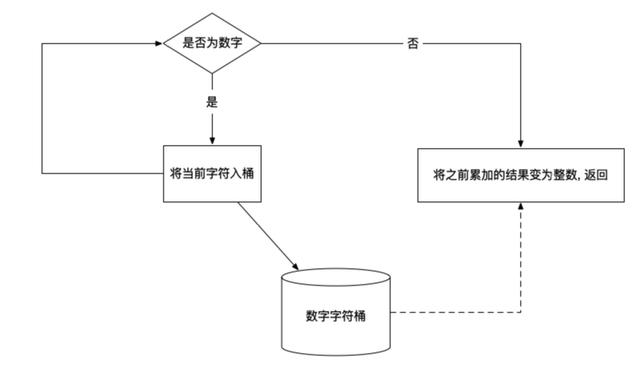
数字的处理逻辑
02 – 概念扩充 – 词位
我们回顾一下上一个章节, 对于 Token 的概念, 我们知道, Token 是由一个字符或者多个字符组成的, Token 是语法中最小的单位, 经过今天的扩充升级, 对于 INTEGER 这个类型的 Token, 示例如下;
- “1234”
- “9”
- “87”
以上三个示例, 都是合法的 INTEGER Token, 他们组成的字符分别是
- “1234” -> 1, 2, 3, 4, 共计 4 个字符
- “9” -> 9, 共计 1 个字符
- “87” -> 8, 7, 共计 2 个字符
以上, 对于组成 Token 的每个”字符”, 我们更专业的叫法叫做 ” 词位 “, 当前阶段, 字符 = 词位, 也就是说, Token 是由 1 ~ N 个 词位组成.
那么对于等式 “78 + 129” 来说, Token 的对应关系如下:
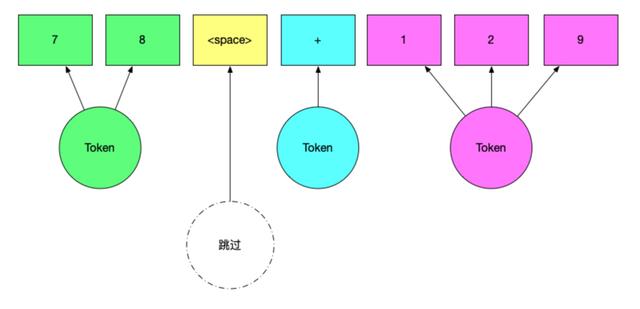
token 的词位
03 – 概念扩充 – “句式”
我们把 N 位数的加法的语法描述上升一个高度, 怎么讲? 就如同上一个章节那样
可以归纳为 ” [时间] + [要描述的事情] + [自身主观的评价] ” 这样的句式, 符合这样句式的话有很多, 例如:
- “明天天气很槽糕”
- “昨天你身上的味道很难闻”
等等等等, 要强调一点的是, “句式”是我自己创造的概念, 方便大家理解
同样的, 我们的计算表达式, 在本质上也可以理解为 “一句话”, 既然都是”话”, 那么我们就来分析一下计算表达式的”句式”:
对于 “1+3” , 我们可以推导为 [1 个整数] + [1 个字符<加号>] + [1 个整数]
扩展到 N 位数的时候, N 位数字同样也符合 [1 个整数] 的概念, 这样看起来还不错, 那我们推导出的”句式”是正确的么? 如何验证呢, 最简单的一个验证方式, 就是看能不能找出一个例子, 符合这个语义, 但是不符合这个”句式”的
很显然: 76.354 + 45.9 , 这样的 浮点数 加法就不符合, 并且这个式子表达的也是 <加法> 这个概念
我们找到了一个反例, 推翻了我们推导出的 [1 个整数] + [1 个字符<加号>] + [1 个整数] 这个句式, 我们注意到, 反例出现了 “浮点数” 这个概念, 超过了我们限定的边界概念<整数>, 这种情况下我们是不认为这是一个有效的反例, 因为我们在最开始已经限定了需求边界, 边界就是<整数>, 就好比软件开发中, 每个阶段都要确定需求边界一样, 有些需求可以做, 有些需求是不被允许的, 很显然, “浮点数加法” 就不符合我们之前的需求边界 “整数加法”, 所以我们可以认为上面那个反例是无效的.
综上, 我们推导出了正确的句式: [1 个整数] + [1 个字符<加号>] + [1 个整数]
我们解析处理的时候大致就是这样:
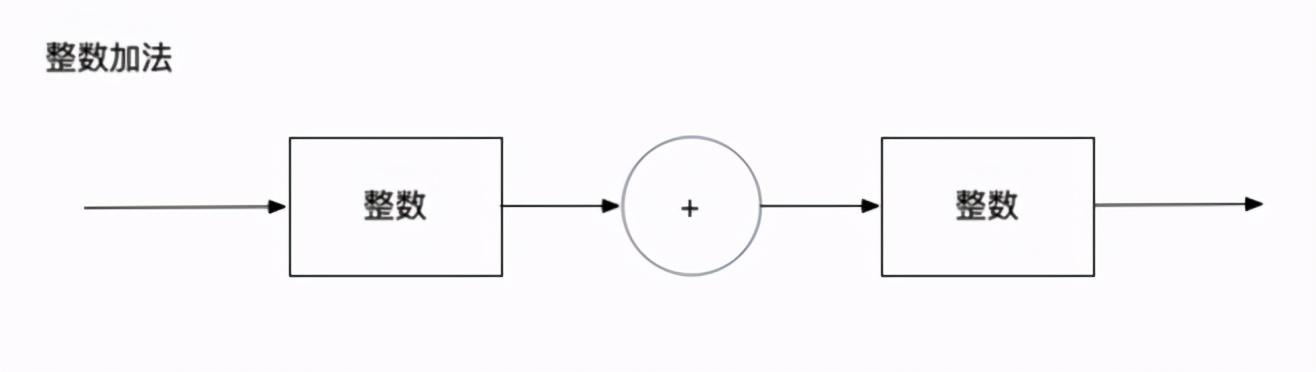
句式的图形表示
04 – 概念扩充 – “状态转移图”
上边的图大家应该都能看得懂, 但是随着人多起来之后, 每个人的画图习惯都不一样, 有人喜欢矩形, 有人喜欢三角形, 还有人喜欢加上漂亮的颜色点缀一下, 这时候就有人说了:

“这图的含义我们都能明白, 可是这一个那一个的, 而且里边的形状, 颜色什么的啥都有, 乱糟糟的, 不如我们就把图的标准给统一一下, 把 Token 分类, 各个类别有不同的形状, 大伙都按这个标准来, 交流上也没有任何困难了, 岂不美哉?”
于是, 就有一帮前辈们,着手制定规范, 按这个规范画出来的图, 我们称之为 “状态转移图”, 至于 “状态转移”这个词现在听起来怪怪的, 感觉两种没啥关系, 不要纠结名字, 并且具体的规范内容, 里边各种图案的含义, 现在统统不是重点,现在也不需要深入地了解它, 我们只需要知道, 当前阶段下上面那个”句式”图的含义即可
04 – 概念扩充 – “文法和范式”
这时候又有人跳出来说话了:

“这图片好理解倒是好理解, 但是我们如果在非常严谨的论文或者学术记录上的时候, 总不能把图片咔咔粘贴上去吧, 有图片的情况下, 格式不好调整不说, 显得多不专业啊,是不是, 要是我们能搞个文字版本的描述, 整的跟数学公式一样优美简洁, 那这让人一看,指定会说, 嘿, 这东西可真牛, 可太专业了, 文化人搞出来的东西就是不一样”.

哈哈哈, 开个玩笑.
那么我们把上面的状态转移图的文字表示, 称作”上下文无关文法(CFG)”
其中 “BNF范式(巴克斯-诺尔范式)” 是上下文无关文法的一种表现形式, 这里的概念有些多了, 我们用大白话说一下,CFG(上下文无关文法)更像是一个规范类似的东西, 可以理解为是个虚无缥缈的概念, 而 BNF范式 是一个相对具体的规范, 规定了一些符号等等. 举个例子来说,
- 吃苹果
- 吃西瓜
- 吃葡萄
上边这三个短句, 都可以看做是 “吃水果”, 也就是说, “水果” 和 “苹果”/”西瓜”/”葡萄” 这种抽象和具体的关系, 类似于 CFG 和 BNF 的关系(并不严谨, 能理解到这个意思就好)
例子 | 名称 |
水果 | CFG |
苹果/西瓜/葡萄 | BNF |
好了好了, 就此打住!! 我们今天接触到的概念够多了, 需要时间消化一下
05 – 代码实现
那我们就来看看今天升级的代码:
首先, CommonUtil.java, 增加了一个通用方法 isSpace, 非常简单
public class CommonUtil {
public static boolean isInteger(char c) {
return c >= '0' && c <= '9';
}
public static boolean isSpace(char c) {
return c == ' ';
}
} 然后对于解释器, 我们今天增加了一个 currentChar 属性, 主要是用来方便定位当前字符的, 因为我们引入了空格, 这样做会方便一些, 完整的代码就不贴出来了, 感兴趣的同学可以从 gitee 上拉取代码哦, 有详细的注释说明
/** 获取当前游标指向的那个字符,并返回, 同时将游标向前移动一位 */ public void assignCurrentCharAndMovePos() {
if (this.pos > this.text.length() - 1) { this.currentChar = null; return; }
this.currentChar = this.text.charAt(this.pos);
this.pos++;
}
/** 不断的检查 "当前字符" 是不是空格, 如果是, 则不断的向后移动游标 */ public void skipAnnoyingSpace() {
while (this.currentChar != null && CommonUtil.isSpace(this.currentChar)) {
this.assignCurrentCharAndMovePos();
}
}
/**
* 查看当前字符, 如果字符是数字, 则存储到 "数字字符桶" 中, 直到遇见非数字的字符
* 最后将字符串形式的数字转换为 BigDecimal 返回,
* 为什么是 BigDecimal? 因为我们无法预料用户输入的整数到底多大, 很有可能溢出(int/log)
* 当前阶段不需要考虑太多, 直接采用 BigDecimal 比较方便
*/ public BigDecimal fetchIntegerNumber() {
// StringBuilder 就是我们图上画出的 "数字字符桶"
StringBuilder sb = new StringBuilder();
while (this.currentChar != null && CommonUtil.isInteger(this.currentChar)) {
sb.append(this.currentChar);
this.assignCurrentCharAndMovePos();
}
return new BigDecimal(sb.toString());
}
/** 遍历字符数组, 然后对每个字符进行判断, 将其包装为 Token 之后进行返回 */ public Token getNextToken() {
while (this.currentChar != null) {
this.skipAnnoyingSpace();
// 如果 char 为数字, 则包装为 INTEGER token, 此 token 可能会包含 1~N 个字符
if (CommonUtil.isInteger(this.currentChar)) {
return new Token(Constant.TOKEN_INTEGER, this.fetchIntegerNumber());
}
// 如果 char 为 + 符号, 则包装为 PLUS token
if (this.currentChar == '+') {
this.assignCurrentCharAndMovePos();
return new Token(Constant.TOKEN_PLUS, '+');
}
// 以上两者都不是, 则证明给定的文本中包含了非法字符, 我们抛出错误, 拒绝执行
this.error();
}
// 循环退出, this.currentChar 为 null, 没有下一个字符了, 返回 eof
return Token.EofToken();
} 06 – 结语
今天接触到的概念有点儿多了, 需要好好捋顺
- 词位的概念
- 推导句式的过程以及简单验证
- 状态转移图
- 上下文无关文法(CFG), BNF 范式, 以及这二者的关系
注: 文中的一些具体概念, 目前阶段知道它是个什么东西就好, 不要太深究,另外有一些术语的类比, 仅仅是为了方便理解,可能并不准确, 如有错误之处, 欢迎提出讨论
在下一个章节, 我们在次升级解释器, 让它支持连续加法/减法(例如: “2+34+1+5-8-7” 这种)


