
LeetCode 1010. 总时长可被60整除的一对歌曲数量(Pairs of Songs With Total Durations Divisible by 60)
问题描述:
在歌曲列表中,第 i 首歌曲的持续时间为 time[i] 秒。
现在统计任意一对歌曲的总的持续时间,返回总持续时间可以被60整除的歌曲对的数量。
在形式上,对于歌曲索引 i < j, 我们求的是满足(time[i] + time[j]) % 60 == 0 的数量。
注:
- 1 <= time.length <= 60000
- 1 <= time[i] <= 500
示例:

C语言实现:
这个问题很简单,我们只需要知道一个概念:
对于整数 i, j,如果i+j可被60整除,则存在如下的 等价关系 :
(i+j)/60 等价于 (i%60 + j%60) == 60
这样我们就可以将任意值的整数a和b限制在0~59之间,因为它们的余数不会超过59。
因此,我们可以建立一个长度是60的数组rem,下标059对应059的余数,每个元素的值记录出现该余数的歌曲的数量。
我们对数组time进行遍历,对于每一个歌曲时长i:
1. 计算出与60余运算后的余数index = i%60;
2. 这样如果rem[60-index]不为空,那么里面记录的每一个歌曲总时长都可以和i相加后得到的总持续时间都能被60整除;
注意我们要考虑一种特殊情况:
当i可以被60整除时,index是0,那么这时候我们期望找到其他的可以被60整除的歌曲时长,就依然是rem[0],所以我们将60-index要写成(60-index)%60;
3. 最后我们还要将当前歌曲记录到rem中的对应位置,以使得后续的歌曲可以与之配对。
代码如下:
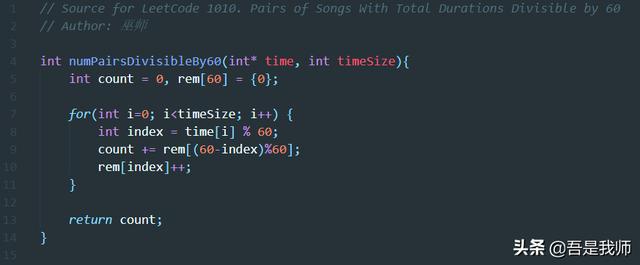
这个实现在leetCode中的表现不太好,后来查看一个标注12mm的C语言实现,测试提交,发现用时也是20mm(可能是Leetcode更新了测试程序或者案例)。
虽然在C语言的环境下,实际表现都差不多。但是我觉得他这个思路很好。
该实现的代码如下:
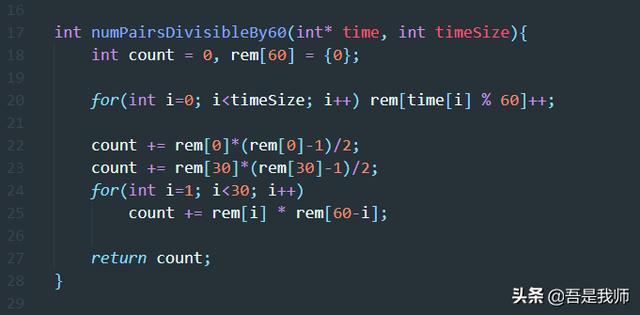
它其实是对我的上面算法的优化。两个算法的 时间复杂度 都是O(len(time))。
第一个算法在遍历过程中包含两个操作,一个是求count,一个是修改rem,它们都执行了len(time)次。
而这个算法,是将计算count的步骤单独拿出来,通过遍历rem[0]~rem[30]即可求出count。求count只进行了31次操作,所以当time长度大于31时,理论上,这个算法的效率会高一些。计算count的过程也非常简单。分为两种情况:
- 对于余数是0或30歌曲,任意两个数都可以被60整除,所以“歌曲对”的数量其实就是: 从n个歌曲中任意取2个歌曲的组合问题即 n*(n-1)/2 ;
- 其他情况,即,对于rem[a]和rem[b], a+b==60,且a,b都不等于0和30。“歌曲对”的数量其实就是: 从rem[a]中取一个歌曲再从rem[b]中取一个歌曲的不同取法的数量。即rem[a]*rem[b]。
那么为什么计算count只要遍历31次,而不是60次?
由于a+b=60,且为自然数,必然有其中一个大于30,另一个小于30。所以综上所述,只需遍历rem[0]~rem[30]即可求出count。
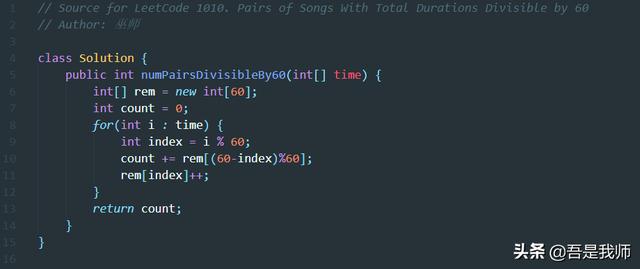
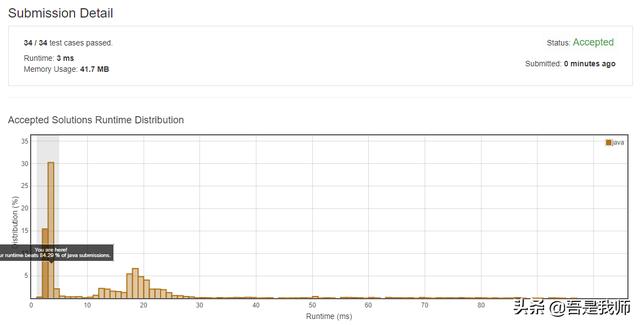
Java语言实现:
Java 的实现和C语言的第一个实现一致,另外一个读者自行完成,不再撰述。代码如下:
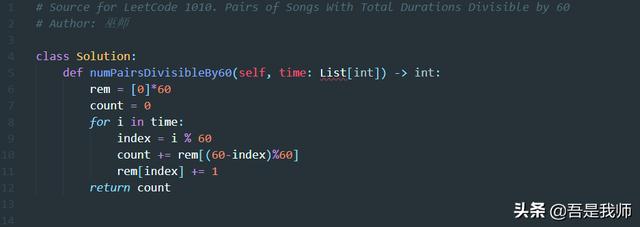
Python语言实现:
Python 的实现和C语言的第一个实现一致,另外一个读者自行完成,不再撰述。代码如下:
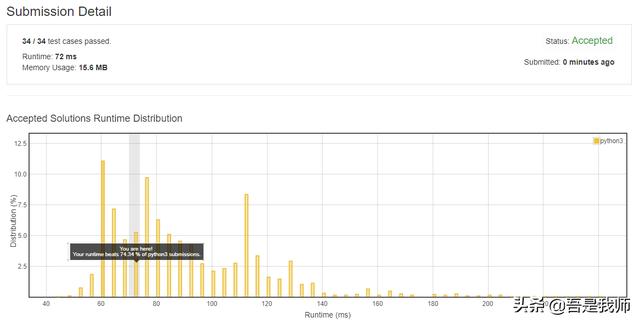
谢谢大家一直以来的关注和支持!
我一直在努力的写好每一篇文章,画好每一份插图。但是作为一个996从业人员,时间精力十分有限。所以针对评论部分,以后 只回答粉丝的问题和私信 。希望仅仅是路过的朋友能够体谅, 希望更多人关注《吾是我师》, 谢谢!


