二叉搜索树
二叉搜索树结合了无序链表插入便捷和有序数组二分查找快速的特点,较为高效地实现了有序符号表。下图显示了二叉搜索树的结构特点(图片来自《算法第四版》):

可以看到每个父节点下都可以连着两个子节点,键写在节点上,其中左边的子节点的键值小于父节点的键值,右节点的键值大于父节点的键值。每个父节点及其后代节点组成了一颗子树,根节点及其后代节点则组成了完整的二叉搜索树。
在代码层面看来,就是每个节点对象中包含另外两个子节点的指针,同时包含一些要用到的数据,比如键值对和方便后续操作的整课子树的节点数量。
private class Node {
int N = 1;
K key;
V value;
Node left;
Node right;
public node (K key, V value) {
this.key = key;
this.value = value;
}
} 上述代码实现了一个节点类,这个类是二叉搜索树类 BinarySearchTree 的内部类,使用者无需知道这个节点类的存在,所以访问权限声明为 private。
有序符号表的 API
先来看下无序符号表的 API,这些方法声明了无序符号表的基本操作,包括插入、查询和删除,为了方便符号表的迭代,接口中还有 Iterable<K> keys() 方法用于 foreach 循环:
package com.zhiyiyo.collection.symboltable;
public interface SymbolTable<K, V>{
void put(K key, V value);
V get(K key);
void delete(K key);
boolean contains(K key);
boolean isEmpty();
int size();
Iterable<K> keys();
} 接下来是有序符号表的 API,其中每个节点的键必须实现了 Comparable 接口:
package com.zhiyiyo.collection.symboltable;
public interface OrderedSymbolTable<K extends Comparable<K>, V> extends SymbolTable<K, V>{
/**
* 获取符号表中最小的键
* @return 最小的键
*/ K min();
/**
* 获取符号表中最大的键
* @return 最大的键
*/ K max();
/**
* 获取小于或等于 key 的最大键
* @param key 键
* @return 小于或等于 key 的最大键
*/ K floor(K key);
/**
* 获取大于或等于 key 的最小键
* @param key 键
* @return 大于或等于 key 的最小键
*/ K ceiling (K key);
/**
* 获取小于或等于 key 的键数量
* @param key 键
* @return 小于或等于 key 的键数量
*/ int rank(K key);
/**
* 获取排名为 k 的键,k 的取值范围为 [0, N-1]
* @param k 排名
* @return 排名为 k 的键
*/ K select(int k);
/**
* 删除最小的键
*/ void deleteMin();
/**
* 删除最大的键
*/ void deleteMax();
/**
* [low, high] 区间内的键数量
* @param low 最小的键
* @param high 最大的键
* @return 键数量
*/ int size(K low, K high);
/**
* [low, high] 区间内的所有键,升序排列
* @param low 最小的键
* @param high 最大的键
* @return 区间内的键
*/ Iterable<K> keys(K low, K high);
} 实现二叉搜索树
二叉搜索树类
类的基本结构如下述代码所示,可以看到只需用一个根节点 root 即可代表一整棵二叉搜索树:
public class BinarySearchTree<K extends Comparable<K>, V> implements OrderedSymbolTable<K, V> {
private Node root;
private class Node{
...
}
...
} 查找
从根节点出发,拿着给定的键 key 和根节点的键进行比较,会出现以下三种情况:
key
key
key
当我们去左子树或者右子树查找时,只需将子树的根节点视为新的根节点,然后重复上述步骤即可。如果找到最后都没找到拥有和 key 相等的键的节点,返回 null 即可。在《算法第四版》中使用递归实现了上述步骤,这里换为 迭代法 :
@Override
public V get(K key) {
Node node = root;
while (node != null) {
int cmp = node.key.compareTo(key);
// 到左子树搜索
if (cmp > 0) {
node = node.left;
}
// 到右子树搜索
else if (cmp < 0) {
node = node.right;
} else {
return node.value;
}
}
return null;
} 插入
将键值对放入二叉搜索树时会发生两种情况:
- 二叉搜索树中已经包含了拥有该键的节点,这时需要更新节点的值
- 二叉搜索树中没有包含拥有该键的节点,这时需要创建一个新的节点
所以在插入的时候要从根节点出发,比较根节点的键和给定的 key 之间的大小关系,和查找相似,比较会有三种情况发生:
key
key
key
如果找到最后都没能找到那个拥有相同 key 的节点,就需要创建一个新的节点,把这个节点,接到子树的根节点上,用迭代法实现上述过程的代码如下所示:
@Override
public put(K key, V value){
if (root == null) {
root = new Node(key, value);
return;
}
Node node = root;
Node parent = root;
int cmp = 0;
while (node != null){
parent = node;
cmp = node.key.compareTo(key);
// 到左子树搜索
if (cmp > 0){
node = node.left;
}
// 到右子树搜索
else if (cmp < 0){
node = node.right;
} else {
node.value = value;
return;
}
}
// 新建节点并接到父节点上
if (cmp > 0) {
parent.left = new Node(key, value);
} else{
parent.right = new Node(key, value);
}
} 可以看到上述过程用了两个指针,一个指针 node 用于探路,一个指针 parent 用于记录子树的根节点,不然当 node 为空时我们是找不到他的父节点的,也就没法把新的节点接到父节点上。
上述代码有个小问题,就是我们新建节点之后没办法更新这一路上所经过的父节点的 N ,也就是每一颗子树的节点数。怎么办呢,要么用一个容器保存一下经过的父节点,要么老老实实用递归,这里选择用递归。递归的想法很直接:
key
key
key
别忘了,使用递归的原因是我们要更新父节点的 N ,所以递归的返回值应该是更新后的子树根节点,所以就有了下述代码:
@Override
public void put(K key, V value) {
root = put(root, key, value);
}
private Node put(Node node, K key, V value) {
if (node == null) return new Node(key, value);
int cmp = node.key.compareTo(key);
if (cmp > 0) {
node.left = put(node.left, key, value);
} else if (cmp < 0) {
node.right = put(node.right, key, value);
} else {
node.value = value;
}
node.N = size(node.left) + size(node.right) + 1;
return node;
}
private int size(Node node) {
return node == null ? 0 : node.N;
} 最小/大的键
从根节点出发,一路向左,键会是一个递减的序列,当我们走到整棵树的最左边,也就是 left 为 null 的那个节点时,我们就已经找到了键最小的节点。上述过程的迭代法代码如下:
@Override
public K min() {
if (root == null) {
return null;
}
Node node = root;
while (node.left != null) {
node = node.left;
}
return node.key;
} 查找最大键的节点过程和上述过程类似,只是我们这次得向右走,直到找到 right 为 null 的那个节点:
@Override
public K max() {
if (root == null) {
return null;
}
Node node = root;
while (node.right != null) {
node = node.right;
}
return node.key;
} 算法书中给出的 min() 实现代码是用递归实现的,因为在删除节点时会用到。递归的过程就是一直朝左子树走的的过程,直到遇到一个节点没有左子树为止,然后返回该节点即可。
@Override
public K min() {
if (root == null) {
return null;
}
return min(root).key;
}
private Node min(Node node) {
if (node.left == null) return node;
return min(node.left);
} 小于等于key的最大键/大于等于key的最小键
从根节点出发,拿着根节点的的键和 key 进行比较,会出现三种情况:
- 如果根节点的键大于 key ,说明拥有小于或等于 key 的键的节点可能在左子树上(也可能找不到);
- 如果根节点的键小于 key ,这时候先记住根节点,由于根节点的右子树上可能存在键更接近但不大于 key 的节点,所以还得去右子树看看,如果右子树没没找到满足条件的节点,这时候的根节点的键就是小于等于 key 的最大键了;
- 如果根节点的键等于 key ,直接返回根节点的键
@Override
public K floor(K key) {
if (root == null) {
return null;
}
Node node = root;
Node candidate = root;
while (node != null) {
int cmp = node.key.compareTo(key);
if (cmp > 0) {
node = node.left;
} else if (cmp < 0) {
candidate = node;
node = node.right;
} else {
return node.key;
}
}
return candidate.key.compareTo(key) <= 0 ? candidate.key : null;
} 《算法第四版》中给出了一个示例图,可以更直观地看到上述查找过程:
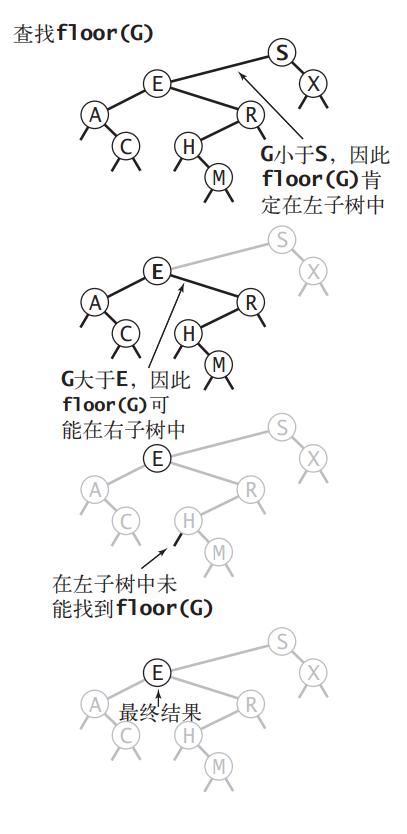
查找大于等于 key 的最小键的方法和上述过程很像,拿着根节点的的键和 key 进行比较,会出现三种情况:
- 如果根节点的键小于 key ,说明拥有大于或等于 key 的键的节点可能在右子树上(也可能找不到);
- 如果根节点的键大于 key ,这时候先记住根节点,由于根节点的左子树上可能存在键更接近但不小于 key 的节点,所以还得去左子树看看,如果左子树没没找到满足条件的节点,这时候的根节点的键就是大于等于 key 的最小键了;
- 如果根节点的键等于 key ,直接返回根节点的键
@Override
public K ceiling(K key) {
if (root == null) {
return null;
}
Node node = root;
Node candidate = root;
while (node != null) {
int cmp = node.key.compareTo(key);
if (cmp < 0) {
node = node.right;
} else if (cmp > 0) {
candidate = node;
node = node.left;
} else {
return node.key;
}
}
return candidate.key.compareTo(key) >= 0 ? candidate.key : null;
} 根据排名获得键
假设一棵二叉搜索树中有 N 个节点,那么节点的键排名区间就是 [0, N-1],也就是说, key 的排名可以看做小于 key 的键的个数。所以我们应该如何根据排名获得其对应的键呢?这时候每个节点中的维护的 N 属性就可以派上用场了。
从根节点向左看,左子树的节点数就是小于根节点键的键个数,也就是根节点的键排名。所以拿着根节点的左子树节点数 N 和排名 k 进行比较,会出现三种情况:
k = k - N - 1
@Override
public K select(int k) {
Node node = root;
while (node != null) {
// 父节点左子树的大小就是父节点的键排名
int N = size(node.left);
if (N > k) {
node = node.left;
} else if (N < k) {
node = node.right;
k = k - N - 1;
} else {
return node.key;
}
}
return null;
} 根据键获取排名
把根据排名获取键的过程写作 (text{key = select(k)}) ,那么根据键获取排名的过程就是 (text{k = select}^{-1}text{(key) = rank(key)}) 。说明这两个函数互为反函数。
从根节点出发,拿着根节点的键和 key 进行比较会出现三种情况:
key
key
key
@Override
public int rank(K key) {
Node node = root;
int N = 0;
while (node != null) {
int cmp = node.key.compareTo(key);
if (cmp > 0) {
node = node.left;
} else if (cmp < 0) {
N += size(node.left) + 1;
node = node.right;
} else {
return size(node.left) + N;
}
}
return N;
} 删除
删除操作较为复杂,先来看下较为简单的删除键最小的节点的过程。从根节点出发,一路向左,知道遇到左子树为 null 的节点,由于这个节点可能还有右子树,所以需要把右子树接到父节点上。接完之后还得把这一路上遇到的父节点上的 N – 1。由于没有其他节点引用了被删除的节点,所以这个节点会被 java 的垃圾回收机制自动回收。算法书中给出了一个删除的示例图:
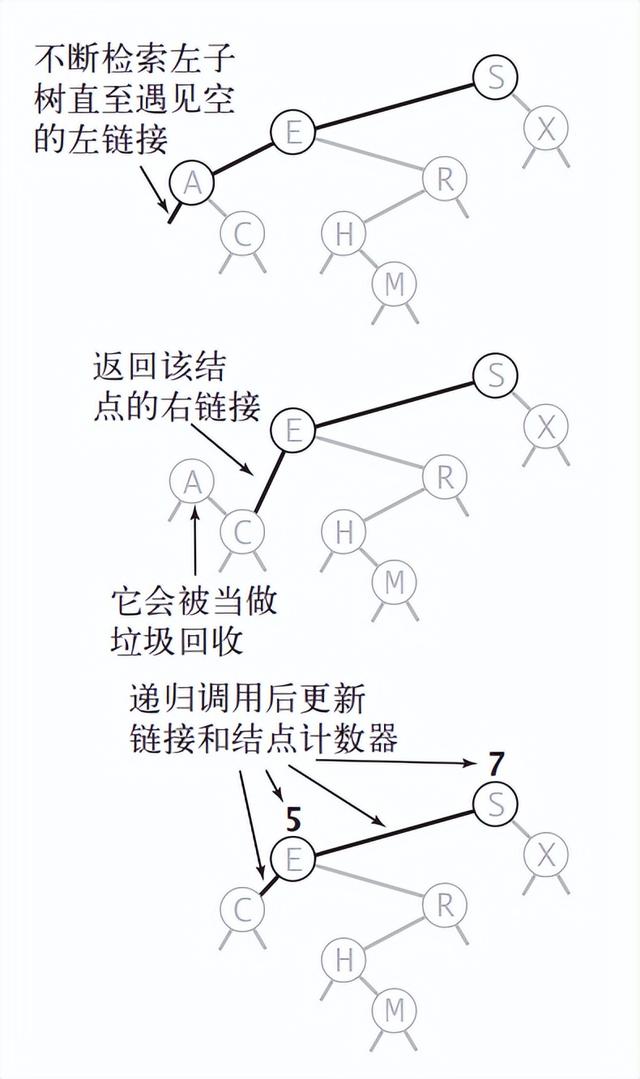
使用迭代法可以实现寻找最小节点和将右子树连接到父节点的操作,但是不好处理每一颗子树的 N 的更新操作,所以还是得靠 递归法 。由于我们需要将最小节点的右子树接到父节点上,所以满足终止条件时 deleteMin(Node node) 函数应该把右子树的根节点返回,否则就应该返回更新之后的节点。
@Override
public void deleteMin() {
if (root == null) return;
root = deleteMin(root);
}
private Node deleteMin(Node node) {
if (node.left == null) return node.right;
node.left = deleteMin(node.left);
node.N = size(node.left) + size(node.right) + 1;
return node;
} 删除最大的节点的过程和上面相似,只不过我们应该将最大节点的左子树接到父节点上。
@Override
public void deleteMax() {
if (root == null) return;
root = deleteMax(root);
}
private Node deleteMax(Node node) {
if (node.right == null) return node.left;
node.right = deleteMax(node.right);
node.N = size(node.left) + size(node.right) + 1;
return node;
} 讨论完上面两个较为简单的删除操作,我们来看下如何删除任意节点。从根节点出发,通过比较根节点的键和给定的 key ,会发生三种情况:
- 根节点的键大于 key ,接着去左子树删除 key
- 根节点的键小于 key ,接着去右子树删除 key
- 根节点的键等于 key ,说明我们找到了要被删除的那个节点,这时候我们又会遇到三种情况:
- 节点的右子树为空,直接将左子树的根节点接到父节点上
- 节点的左子树为空,直接将右子树的根节点接到父节点上
- 节点的右子树和左子树都不为空,这时候需要找到并删去右子树的最小键节点,然后把这个最小键节点顶替即将被删除节点,把它作为新的子树根节点
算法书中给出了第三种情况(右子树和左子树都不为空)的示例图:
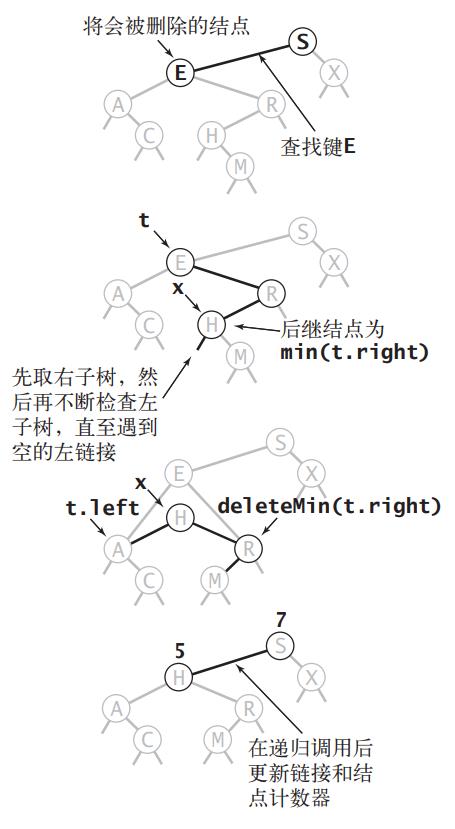
使用递归实现的代码如下所示:
@Override
public void delete(K key) {
root = delete(root, key);
}
private Node delete(Node node, K key) {
if (node == null) return null;
// 先找到 key 对应的节点
int cmp = node.key.compareTo(key);
if (cmp > 0) {
node.left = delete(node.left, key);
} else if (cmp < 0) {
node.right = delete(node.right, key);
} else {
if (node.right == null) return node.left;
if (node.left == null) return node.right;
Node x = node;
node = min(x.right);
// 移除右子树的最小节点 node,并将该节点作为右子树的根节点
node.right = deleteMin(x.right);
// 设置左子树的根节点为 node
node.left = x.left;
}
node.N = size(node.left) + size(node.right) + 1;
return node;
} 总结
如果在插入键值对的时候运气较好,二叉搜索树的左右子树高度相近,那么插入和查找的比较次数为 (sim2ln N) ;如果运气非常差,差到所有的节点连成了一条单向链表,那么插入和查找的比较次数就是 (sim N) 。所以就有了自平衡二叉树的出现,不过这已经超出本文的探讨范围了( 绝对不是因为写不动了 ,以上~~


