不管你是做前端还是后端的开发,那我相信树形结构的需求一定有遇到过,特别是管理平台类型的项目,一般都会有一个树形结构的菜单栏,再比如说, 公司组织架构 , 层级关系 、 归属关系 等等需求,本质上都是树形结构的一种体现;
遇到这种需求,最常见也最容易想到的设计思路就是: 父子关系的方式 ,子项通过一个字段来保存他的父ID,然后通过递归的方式得到层级关系;
前几天,技术交流群里面有小伙伴在问,实际的业务中,树形结构的数据太多、层级还深,查询过程一顿递归之后,性能表现得比较差,问有没有什么好的设计思路,让查询、统计更加的便捷高效;
今天就给大家介绍一种新的树形结构设计方案: 改进后的先序树方式 ,在查询、统计方面的优势,要远大于父子关系的递归设计方案;
本文就来详细的讲解并对比一下两个方案的实现方式以及优缺点。
文章目录:

对于树形结构的需求,不管是采用什么方式,要处理的问题都是差不多的,下面先列举一下树形结构常见的问题点有哪些:
- 节点的增删改
- 是否存在子节点( 叶子 节点)
- 查询出所有的子节点
- 查询所有的节点
- 查询所有的子孙节点
- 父节点查询
- 祖先节点查询
- 统计所有子孙部门的数量
针对上面的这些问题,就以一个简单的公司组织架构示例,一起来看看,两种方案都是如何实现和解决的?
本文所有的示例都是采用的 MySQL + Java 实现,核心思路都类似,实际使用,可根据语言特性以及自己习惯的方式调整即可。
1父子关系方案
父子关系,顾名思义,就是当前节点只关注自己的父节点是谁,并将其保存起来即可,查询我的子节点有哪些,只需要全局找到所有父ID是和我的ID一致的项;
如下图所示:

方案特点
- 优点
- 方案简单易懂
- 数据结构简单清晰
- 层级直观、鲜明
- 易维护层级关系只需要关注自己的父ID,所以在添加、修改的时候,一旦关系发生变化,调整对应的父ID即可。
- 缺点
- 查找麻烦、统计麻烦根据当前节点的数据,只能获取到子节点的数据,一旦查询、统计超出父子范围,就只能通过递归逐层查找了;
示例
根据上面的图示示例,与其对应的表结构如下:
IDdep_name(部门名称)level(层级)parent_id(父ID) 1董事会10 2总经理21 3董事会秘书21 4产品部32 5行政总监32 6设计部44 7技术部44 8财务部45 9行政部45 10客户端57 11服务端57
SQL 脚本:
DROP TABLE IF EXISTS `department_info`;
CREATE TABLE `department_info` (
`id` int(11) NOT NULL,
`dep_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '名称',
`level` int(11) NULL DEFAULT NULL,
`parent_id` int(11) NULL DEFAULT NULL COMMENT '父ID',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `department_info` VALUES (1, '董事会', 1, 0);
INSERT INTO `department_info` VALUES (2, '总经理', 2, 1);
INSERT INTO `department_info` VALUES (3, '董事会秘书', 2, 1);
INSERT INTO `department_info` VALUES (4, '产品部', 3, 2);
INSERT INTO `department_info` VALUES (5, '行政总监', 3, 2);
INSERT INTO `department_info` VALUES (6, '设计部', 4, 4);
INSERT INTO `department_info` VALUES (7, '技术部', 4, 4);
INSERT INTO `department_info` VALUES (8, '财务部', 4, 5);
INSERT INTO `department_info` VALUES (9, '行政部', 4, 5);
INSERT INTO `department_info` VALUES (10, '客户端', 5, 7);
INSERT INTO `department_info` VALUES (11, '服务端', 5, 7);
函数的创建
由于父子节点的查询,需要依赖递归,为了查询方便,这里创建两个函数:
- 递归查询子孙节点ID的函数 DROP FUNCTION IF EXISTS queryChildrenDepInfo;
DELIMITER ;;
CREATE FUNCTION queryChildrenDepInfo(dep_id INT )
RETURNS VARCHAR ( 4000 )
BEGIN
DECLARE sTemp VARCHAR ( 4000 );
DECLARE sTempChd VARCHAR ( 4000 );
SET sTemp= ‘$’ ;
SET sTempChd = CAST (dep_id AS CHAR );
WHILE sTempChd IS NOT NULL DO
SET sTemp= CONCAT (sTemp, ‘,’ ,sTempChd);
SELECT GROUP_CONCAT ( id ) INTO sTempChd FROM department_info WHERE FIND_IN_SET(parent_id,sTempChd)> 0 ;
END WHILE ;
RETURN sTemp;
END
;;
DELIMITER ;
测试:查询技术部下的所有重要节点? SELECT queryChildrenDepInfo( 4 );
SELECT * FROM department_info WHERE FIND_IN_SET( id ,queryChildrenDepInfo( 4 )); - 递归查询祖先节点ID的函数 DROP FUNCTION IF EXISTS queryParentDepInfo;
DELIMITER;;
CREATE FUNCTION queryParentDepInfo(dep_id INT )
RETURNS VARCHAR ( 4000 )
BEGIN
DECLARE sTemp VARCHAR ( 4000 );
DECLARE sTempChd VARCHAR ( 4000 );
SET sTemp= ‘$’ ;
SET sTempChd = CAST (dep_id AS CHAR );
SET sTemp = CONCAT (sTemp, ‘,’ ,sTempChd);
SELECT parent_id INTO sTempChd FROM department_info WHERE id = sTempChd;
WHILE sTempChd <> 0 DO
SET sTemp = CONCAT (sTemp, ‘,’ ,sTempChd);
SELECT parent_id INTO sTempChd FROM department_info WHERE id = sTempChd;
END WHILE ;
RETURN sTemp;
END
;;
DELIMITER ;
测试:查询技术部所有的祖先节点? SELECT queryParentDepInfo( 7 );
SELECT * FROM department_info WHERE FIND_IN_SET( id ,queryParentDepInfo( 7 ));
节点的增删改
- 增加节点 比如要在技术部下添加一个测试部门 INSERT INTO department_info( `id` , `dep_name` , `level` , `parent_id` ) VALUES ( 12 , ‘测试部’ , 5 , 7 );
- 修改节点 比如:将测试部(ID = 12)提出来,放到产品部(ID = 4)下;就只需要将测试部对应的父节点ID修改为4即可 SET @ id = 12 ;
SET @pid = 4 ;
UPDATE department_info SET `parent_id` = @pid WHERE `id` = @ id ; - 删除节点 删除相比于添加修改,情况就会特殊一些,如果删除的节点存在子节点,意味着子节点也需要同步删除掉;因此这里就需要用到上面创建的递归查询子孙节点ID的函数(queryChildrenDepInfo)比如:删除技术部门; DELETE FROM department_info WHERE FIND_IN_SET( id ,queryChildrenDepInfo( 7 ));
是否存在子节点(叶子节点)
在该方案下,要想判断是否是叶子节点,有两种实现方式:
- 统计当前节点以及子孙节点的数量递归查询所有子节点的ID,并统计数量,由于函数查询包含了节点自身,所以这里使用了 COUNT(*)-1 来计算子节点的数量,如果等于0就是叶子节点,大于0说明不是叶子节点; — 查看设计部(ID=6)是不是叶子节点
SET @ id = 6 ;
— 由于数量包含了自身,由于统计的是子节点的数量,所以这里需要-1将自己去掉
SELECT COUNT (*) -1 FROM department_info WHERE FIND_IN_SET( id ,queryChildrenDepInfo(@ id )); - 添加叶子节点的标记在表中添加一个isLeaf字段,当节点增删改操作的时候,用这个字段来标记一下当前是否是叶子节点
查询出所有的下级部门(子节点)
查询所有的下级部门,此时就需要借助当前节点的id和level字段
例:查询产品部(id = 4,level = 3)的子节点
SET @id = 4;
SET @lv = 3;
SELECT * from department_info where parent_id = @id AND `level` = @lv + 1;

查询所有的下下级部门(孙节点)
实际业务场景下,这种需求很少,这里主要用来演示可操作性,不排除特殊的场合下用得上;
查询孙节点相比与子节点就麻烦很多了,因为当前节点和孙节点是没有任何数据上的关联,因此需要借助子节点才能找到孙节点,因此这里又必须得用上递归查询子孙节点ID的函数了;
例:查询产品部(id = 4,level = 3)的孙节点
-- 查询孙节点
SET @id = 4;
SET @lv = 3;
SELECT * FROM department_info WHERE FIND_IN_SET(id,queryChildrenDepInfo(@id)) AND `level` = @lv + 2;

查询所有的下属部门
查询下属部门就和查询下下级部门(孙节点)类似,只是不用校验层级即可;
例:查询产品部下所有的下属部门?
SET @id = 4;
SELECT * FROM department_info WHERE FIND_IN_SET(id,queryChildrenDepInfo(@id));

查询隶属部门
也就是查询节点;在该方案下,节点中已经保存了父节点的ID,通过ID就能直接获取到父节点
查询所有上级部门
由于当前节点只保存了父级节点ID,更上一级的信息只能通过递归逐级获取;
例:查询技术部(id = 7)的所有上级部门;
SET @id = 7;
SELECT * FROM department_info WHERE FIND_IN_SET(id,queryParentDepInfo(@id));

统计所有下属部门的数量
和查询是否是叶子节点的方式一样,只是对得到的数据解读的方式不同而已;
例:统计技术部的下属部门数量?
SET @id = 7;
SELECT COUNT(*)-1 FROM department_info WHERE FIND_IN_SET(id,queryChildrenDepInfo(@id));

2改进后的先序树方案
从从上述的父子关系方案可以看出,大部分的操作,都需要递归查询出所有的子孙节点后才行,如果出现文章开始说的,层级多,深度深的话,递归的过程,就会大大影响查询、统计的性能;
下面就来介绍一下改进后的先序树的树形结构方案,节点不再保存父节点的ID,而是 为每个节点增加左值和右值 :
如下图示:
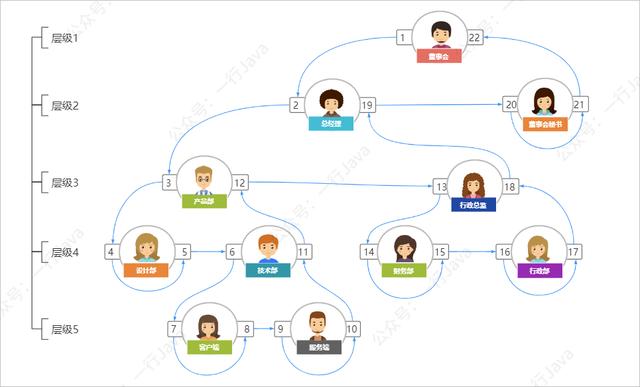
对应的数据如下:
iddep_name(部门名称)lt(左值)rt(右值)lv(层级) 1董事会1221 2总经理2192 3董事会秘书20212 4产品部3123 5行政总监13183 6设计部454 7技术部6114 8财务部14154 9行政部16174 10客户端785 11服务端9105
SQL语句:
DROP TABLE IF EXISTS `department_info2`;
CREATE TABLE `department_info2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`dep_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '名称',
`lt` int(11) NOT NULL COMMENT '节点左数',
`rt` int(11) NOT NULL COMMENT '节点右数',
`lv` int(11) NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 12 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `department_info2` VALUES (1, '董事会', 1, 22, 1);
INSERT INTO `department_info2` VALUES (2, '总经理', 2, 19, 2);
INSERT INTO `department_info2` VALUES (3, '董事会秘书', 20, 21, 2);
INSERT INTO `department_info2` VALUES (4, '产品部', 3, 12, 3);
INSERT INTO `department_info2` VALUES (5, '行政总监', 13, 18, 3);
INSERT INTO `department_info2` VALUES (6, '设计部', 4, 5, 4);
INSERT INTO `department_info2` VALUES (7, '技术部', 6, 11, 4);
INSERT INTO `department_info2` VALUES (8, '财务部', 14, 15, 4);
INSERT INTO `department_info2` VALUES (9, '行政部', 16, 17, 4);
INSERT INTO `department_info2` VALUES (10, '客户端', 7, 8, 5);
INSERT INTO `department_info2` VALUES (11, '服务端', 9, 10, 5);
方案特点
- 优点
- 查询汇总简单高效
- 无需递归查询,性能高
- 缺点
- 结构相对复杂,数据层面理解难度较高
- 不易维护以为左右值的存在,会直接影响到后续的节点,因此,当前节点增删改时,都会对后续的节点产业影响;
示例
节点的增删改
- 新增 如下图:在技术部下新增一个测试部,新增节点对应的左右值分别为11、12;过程分析: 第一步 ,所有比11(新增节点的左数)大的左数全部+2(紫色部分) 第二步 ,所有比12(新增节点的右数)大的右数全部+2(橙色部分) 第三步 ,添加左右数分别为11、12的部门节点 由于这里涉及到多个步骤,我们需要保证数据库操作的原子性,因此需要做事务操作,这里为了方便,创建一个存储过程;存储过程并不式必须的,同样也可以以代码的形式来保证事务操作;只是使用存储过程,可靠性会高一些; 添加节点存储过程 : DROP PROCEDURE IF EXISTS insertDepartment;
CREATE PROCEDURE insertDepartment( IN lt_i INT , IN rt_i INT , IN lv_i INT , IN dn VARCHAR ( 256 ))
BEGIN
DECLARE d_error INTEGER DEFAULT 0 ;
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET d_error= -2 ; — 异常时设置为1
DECLARE CONTINUE HANDLER FOR NOT FOUND SET d_error = -3 ; — 如果表中没有下一条数据则置为2START TRANSACTION ;
— 将所有左值大于新增左值的部门全部+2
UPDATE department_info2 SET lt=lt+ 2 WHERE lt > lt_i;
— 将所有右值大于新增右值的部门全部+2
UPDATE department_info2 SET rt=rt+ 2 WHERE rt >= lt_i;
— 新增部门
INSERT INTO department_info2(dep_name,lt,rt,lv) VALUES (dn,lt_i,rt_i,lv_i);
SET d_error= ROW_COUNT ();IF d_error != 1 THEN
ROLLBACK ; — 结果不等于1 的时候,说明新增失败,回滚操作
ELSE
COMMIT ; — 等于1的时候,说明添加成功,提交
END IF ;
select d_error;
END
输入参数 lt_i :新增部门的左值 rt_i :新增部门的右值 lv_i :行政部门的层级 dn :部门名称 如上图的示例,就可以调用新增的存储过程添加: call insertDepartment( 11 , 12 , 5 , “测试部” ); - 修改 普通的节点信息修改,这里就不多多说了,很简单; 节点移动是此方案下,最复杂的修改操作 ,因为整个过程涉及到位置的变化,层级的变化等多个维度的调整,而且还得保证事务操作; 例:我们要将技术部(id = 4)交由总经理(id = 2)直接负责,也就是移动到总经理之下;过程分析: 第一步 ,计算技术部的左右数差值 第二步 ,计算与移动后的上级节点之间的差值 第三步 ,确定是左移还是右移 第四步 ,将本节点与目标节点之间的差值减去(左移)/加上(右移) 第五步 ,将移动的节点以及子孙的节点与父节点之间的差值减去(左移)/加上(右移) 第六步 ,调整层级 整个过程如下图所示,稍微有点点复杂,可以结合图示以及存储过程的代码,仔细的理解一下:为了方便操作,避免出错,这里同样以存储过程的方式来实现核心逻辑,降低出错风险: DROP PROCEDURE IF EXISTS moveDepartment;
CREATE PROCEDURE moveDepartment( IN fid INT , IN tid INT )
BEGIN
DECLARE d_error INTEGER DEFAULT 0 ;
DECLARE num INTEGER DEFAULT 0 ; — 删除节点左右值之间的差值
DECLARE mnum INTEGER DEFAULT 0 ; — 移动阶段与上级节点之间的差值
DECLARE ids VARCHAR ( 1000 ); — 保存所有正在移动的id集合,保证多个节点移动时也能正常
DECLARE blt INT ; — 需要移动节点的左数
DECLARE brt INT ; — 需要移动节点的右数
DECLARE blv INT ; — 需要移动节点的层级
DECLARE tlt INT ; — 目标节点的左数
DECLARE trt INT ; — 目标节点的右数
DECLARE tlv INT ; — 目标节点的层级
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET d_error= -2 ; — 异常时设置为1
DECLARE CONTINUE HANDLER FOR NOT FOUND SET d_error = -3 ; — 如果表中没有下一条数据则置为2START TRANSACTION ;
— 查询待移动的节点的左右数以及层级
SELECT lt,rt,lv INTO blt, brt,blv FROM department_info2 WHERE id = fid;
— 查询目标节点的左右数以及层级
SELECT lt,rt,lv INTO tlt, trt,tlv FROM department_info2 WHERE id = tid;
— 查询所有要一定的节点,当前节点以及其子孙节点
SELECT GROUP_CONCAT ( id ) INTO ids FROM department_info2 WHERE lt>=blt AND rt <=brt;
IF tlt > blt AND trt < brt THEN
— 将自己移动到自己的下属节点 暂时不允许 如果要如此操作,需要将下级调整为平级 再移动
SET d_error = -4 ;
ELSEIF blt > tlt AND brt < trt AND blv = tlv + 1 THEN
— 说明本身就已经是目标节点在子节点了,不需要处理,直接成功
SET d_error = 0 ;
ELSE
— 计算移动节点与上级节点之间的差值
SET mnum = trt – brt -1 ;
— 计算当前节点及其子节点的差值
SET num = brt – blt + 1 ;— 首先将移动前的节点整个元素表中移除掉
IF trt > brt THEN
— 左往右移动
UPDATE department_info2 SET lt=lt- num WHERE lt > brt AND lt < trt;
UPDATE department_info2 SET rt=rt- num WHERE rt > brt AND rt < trt;
ELSE
— 从右往左移动 将系数全部变为负值,-负数就等于+正数
SET mnum = -mnum;
SET num = – num ;
UPDATE department_info2 SET lt=lt- num WHERE lt >= trt AND lt < blt;
UPDATE department_info2 SET rt=rt- num WHERE rt >= trt AND rt < blt;
END IF ;— 调整移动的节点以及下属节点
UPDATE department_info2 SET lt=lt+mnum,rt=rt+mnum,lv = lv – (blv – tlv -1 ) WHERE FIND_IN_SET( id ,ids);
SET d_error= ROW_COUNT ();IF d_error <= 0 THEN
ROLLBACK ;
ELSE
COMMIT ;
END IF ;
END IF ;
select d_error;
END
输入参数 fid :移动的节点id tid :目标节点id 测试: CALL moveDepartment( 7 , 2 ) - 删除 删除的过程正好与新增相反,在删除节点及其自己点的时候,大于删除节点的所有左右值都需要减去删除节点的左右差值+1;如下图示例: 删除技术部 过程: 第一步 ,计算出删除节点的左右差值+1;技术部的左右值分别时6和11,差值+1:11 – 6 + 1 第二步 ,删除节点机器所有子节点 第三步 ,所有大于删除节点左右值的节点,全部减去差值 同样为了方便操作,我们也创建一个存储过程: DROP PROCEDURE IF EXISTS removeDepartment;
CREATE PROCEDURE removeDepartment( IN did INT )
BEGIN
DECLARE d_error INTEGER DEFAULT 0 ;
DECLARE num INTEGER DEFAULT 0 ; — 删除节点左右值之间的差值
DECLARE dlt INT ; — 删除节点的左值
DECLARE drt INT ; — 删除节点的右值值
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET d_error= -2 ; — 异常时设置为1
DECLARE CONTINUE HANDLER FOR NOT FOUND SET d_error = -3 ; — 如果表中没有下一条数据则置为2START TRANSACTION ;
— 查询删除节点的左右值
SELECT lt,rt INTO dlt, drt FROM department_info2 WHERE id = did;
— 计算当前节点及其子节点的差值
SET num = drt – dlt + 1 ;— 删除当前节点及其子节点
DELETE FROM department_info2 WHERE lt>=dlt AND rt<=drt;
SET d_error= ROW_COUNT ();— 左右值减少对应的插值
UPDATE department_info2 SET lt=lt- num WHERE lt > dlt;
UPDATE department_info2 SET rt=rt- num WHERE rt > drt;IF d_error != num/2 THEN — 判断删除的数量与当前节点+子孙节点的数量是否一致;不一致的话,直接回滚
ROLLBACK ;
ELSE
COMMIT ;
END IF ;
select d_error;
END
测试: — 设计部的id = 7
SET @ id = 7 ;
call removeDepartment(@ id );
是否存在子节点(叶子节点)
无需额外的查询,直接通过节点的左右数,即可判断是否是叶子节点了;当 右数 – 左数 = 1 时,说明当前节点就属于叶子节点,否则就不是;
查询所有的下级部门
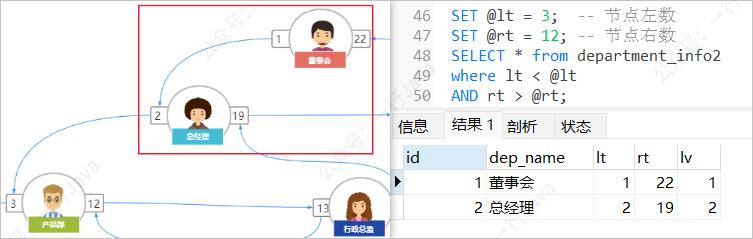
等价于:查询左数比当前节点大,右数比当前节点小,且层比当前节点大1的所有节点;
例:查询产品部(lt = 3,rt = 12,lv = 3)的所有下级部门:
SET @lt = 3; -- 节点左数
SET @rt = 12; -- 节点右数
SET @lv = 3; -- 当先的层级
SELECT * from department_info2 where lt > @lt AND rt < @rt AND `lv` = @lv + 1

查询所有的下下级部门(孙节点)
实际业务中很少会出现此需求,这里仅仅用于可行性演示;
孙节点的查询和子节点类似,仅仅层级由+1变为了+2
例:查询产品部(lt = 3,rt = 12,lv = 3)的所有下下级部门:
SET @lt = 3; -- 节点左数
SET @rt = 12; -- 节点右数
SET @lv = 3; -- 当先的层级
SELECT * from department_info2 where lt > @lt AND rt < @rt AND `lv` = @lv + 2;

查询所有下属部门
等价于:比当前节点左数大,右数小的节点,全部是子孙节点;
例,查询产品部(lt = 3,rt = 12)的所有下属部门:
SET @lt = 3; -- 节点左数
SET @rt = 12; -- 节点右数
SELECT * from department_info2 where lt > @lt AND rt < @rt;

查询隶属部门
等价于:左数比自己小,右数比自己大,且层级-1的节点,也就是父节点
例,查询技术部(lt = 6 , rt = 11)的隶属部门:
SET @lt = 6; -- 节点左数
SET @rt = 11; -- 节点右数
SET @lv = 4; -- 当先的层级
SELECT * from department_info2 where lt < @lt AND rt > @rt AND `lv` = @lv - 1 ;

查询所有的上级部门
与查询父节点类似,只是不再需要校验层级了,所有左数比自己小,右数比自己大都是自己的祖先节点;
例,查询产品部(lt = 3,rt = 12)的所有上级部门
SET @lt = 3; -- 节点左数
SET @rt = 12; -- 节点右数
SELECT * from department_info2 where lt < @lt AND rt > @rt;
统计所有下属部门的数量
统计子孙节点数量,无需额外查询,只需根据自己的左右数,即可计算出子节点的数量;
计算公式: (右数 – 左数 – 1 )/ 2 ;
例,计算产品部(id = 4)的下属部门的数量:
SELECT dep_name,(rt - lt - 1) / 2 as num FROM department_info2 where id = 4

3格式化数据
不管是那种方案,数据层面都是扁平的,只是通过字段逻辑表达了结构化的关系,那查询出来之后,要如何将数据结构化成树形结构之后展示呢,下面介绍递归和非递归的两种方式实现方式:

- 基础的对象 @Data
@RequiredArgsConstructor
public class LrItem {@NonNull
private Integer id;@NonNull
private String depName;@NonNull
private Integer left;@NonNull
private Integer right;private Integer level;
private Integer parentId;
/**
* 是否是叶子
*/
private Boolean isLeaf;private List<LrItem> childItem;
} - 测试数据这里只是演示格式化数据,就不整那么复杂了;实际业务场景,这批数据一般都是从数据库中查询出来的。 List<LrItem> deps = new ArrayList<>();
deps.add( new LrItem( 1 , “董事会” , 1 , 22 ));
deps.add( new LrItem( 2 , “总经理” , 2 , 19 ));
deps.add( new LrItem( 3 , “董事会秘书” , 20 , 21 ));
deps.add( new LrItem( 4 , “产品部” , 3 , 12 ));
deps.add( new LrItem( 5 , “行政总监” , 13 , 18 ));
deps.add( new LrItem( 6 , “设计部” , 4 , 5 ));
deps.add( new LrItem( 7 , “技术部” , 6 , 11 ));
deps.add( new LrItem( 8 , “财务部” , 14 , 15 ));
deps.add( new LrItem( 9 , “行政部” , 16 , 17 ));
deps.add( new LrItem( 10 , “客户端” , 7 , 8 ));
deps.add( new LrItem( 11 , “服务端” , 9 , 10 )); - 整理数据 public static void init (List<LrItem> deps) {
// 如果数据库排序过了之后 这里就不用排序了
deps.sort(Comparator.comparing(LrItem::getLeft));// 为计算层级 缓存节点右侧的值
List<Integer> rights = new ArrayList<>();
Map<Integer, Integer> mp = new HashMap<>();// 初始化节点的层级,叶子节点 以及 父节点ID 对应的数据
deps.forEach(item -> {
if (rights.size() > 0 ) {
// 一旦发现本次节点右侧的值比前一次的大,说明出现层级上移了 需要移除前一个底层及的值
// 这里大部分情况下只存在移除前面一个值情况
while (rights.get(rights.size() – 1 ) < item.getRight()) {
rights.remove(rights.size() – 1 ); //从rights末尾去除
}
}
Integer _level = rights.size() + 1 ;
item.setLevel(_level);
mp.put(_level, item.getId());
item.setParentId(mp.containsKey(_level – 1 ) ? mp.get(_level – 1 ) : 0 ); //计算出上级部门编号
item.setIsLeaf(item.getLeft() == item.getRight() – 1 ); //判断是否叶子部门
rights.add(item.getRight());
});System.out.println(rights);
System.out.println(mp);
}
递归整理
递归的思路比较简单清晰,就是拿到当前节点之后,在所有是节点中找自己的子节点,当所有节点都找过一遍之后,整个树形结构话的过程就完了;
我们可以结合Java 8 Stream新特性,让整个递归代码相对简单清晰;
/**
* @param deps 所有数据
*/public static void recursive(List<LrItem> deps) {
init(deps);
//获取父节点
List<LrItem> collect = deps.stream()
.filter(m -> m.getParentId() == 0)
.map(m ->
{
m.setChildItem(getChildrens(m, deps));
return m;
}
).collect(Collectors.toList());
// 普遍请求下,根节点只会有一个,所以这里取出第一个元素,如果由多个,可根据需求调整,这里仅做测试使用
System.out.println(JSON.toJSON(collect.get(0)));
}
/**
* 递归查询子节点
*
* @param root 根节点
* @param all 所有节点
* @return 根节点信息
*/private static List<LrItem> getChildrens(LrItem root, List<LrItem> all) {
List<LrItem> children = all.stream()
.filter(m -> Objects.equals(m.getParentId(), root.getId()))
.map(m -> {
m.setChildItem(getChildrens(m, all));
return m;
}
).collect(Collectors.toList());
return children;
}
非递归倒序整理
这是一个 以空间换时间 的方案;
此方式的特点:按层级排序后的数据,只需要一次for循环,就能整理出结构化的数据。
- 第一步,计算出层级以及父节点ID
- 第二步,按层级进行排序
- 第三步,倒序从最深的节点让root节点遍历遍历过程以 Map<Integer, List<LrItem>> 的方式缓存ID及当前节点的数据,当上升一个层级之后,就将Map中缓存的关于我的自阶段取出来,保存到自己对象的 childItem 字段中
public static void reverseFormat(List<LrItem> deps) {
init(deps);
deps.sort(Comparator.comparing(LrItem::getLevel));
deps.forEach(item -> System.out.println(JSON.toJSONString(item)));
// 临时缓存各自节点的容器
Map<Integer, List<LrItem>> childCache = new HashMap<>();
// 当前节点
LrItem lrItem = null;
//int level = 0;
// 采用倒序遍历,整理各个子节点的集合
for (int i = deps.size() - 1; i >= 0; i--) {
lrItem = deps.get(i);
Integer parentId = lrItem.getParentId();
if (null == lrItem || null == parentId) {
continue;
}
List<LrItem> childItems = childCache.get(parentId);
if (null == childItems) {
childCache.put(parentId, childItems = new ArrayList<>());
}
childItems.add(lrItem);
// 如果不是叶子节点的时候,说明他肯定有子节点,去缓存中找到,回填回去
if (!lrItem.getIsLeaf()) {
childItems = childCache.get(lrItem.getId());
childItems.sort(Comparator.comparing(LrItem::getId));
lrItem.setChildItem(childItems);
childCache.remove(lrItem.getId());
}
}
System.out.println(JSON.toJSONString(lrItem));
}
格式化后的数据
不管那种方式,最终都会得到以下的结构化数据;
{
"depName": "董事会",
"id": 1,
"isLeaf": false,
"left": 1,
"level": 1,
"prientId": 0,
"right": 22,
"childItem": [
{
"depName": "总经理",
"id": 2,
"isLeaf": false,
"left": 2,
"level": 2,
"prientId": 1,
"right": 19,
"childItem": [
{
"depName": "行政总监",
"id": 5,
"isLeaf": false,
"left": 13,
"level": 3,
"prientId": 2,
"right": 18,
"childItem": [
{
"depName": "设计部",
"id": 6,
"isLeaf": true,
"left": 4,
"level": 4,
"prientId": 4,
"right": 5
},
{
"depName": "技术部",
"id": 7,
"isLeaf": false,
"left": 6,
"level": 4,
"prientId": 4,
"right": 11,
"childItem": [
{
"depName": "客户端",
"id": 10,
"isLeaf": true,
"left": 7,
"level": 5,
"prientId": 7,
"right": 8
},
{
"depName": "服务端",
"id": 11,
"isLeaf": true,
"left": 9,
"level": 5,
"prientId": 7,
"right": 10
}
]
}
],
"depName": "产品部",
"id": 4,
"isLeaf": false,
"left": 3,
"level": 3,
"prientId": 2,
"right": 12
},
{
"childItem": [
{
"depName": "财务部",
"id": 8,
"isLeaf": true,
"left": 14,
"level": 4,
"prientId": 5,
"right": 15
},
{
"depName": "行政部",
"id": 9,
"isLeaf": true,
"left": 16,
"level": 4,
"prientId": 5,
"right": 17
}
]
}
]
},
{
"depName": "董事会秘书",
"id": 3,
"isLeaf": true,
"left": 20,
"level": 2,
"prientId": 1,
"right": 21
}
]
}
4比较
针对上面的详解,下来以表格的形式来更直观的对两者做一下对比:
功能父子关系方案先序数方案 新增 简单 复杂 修改 简单 复杂 删除复杂复杂 判断叶子节点复杂(除非增加编辑难度,提前整理好) 简单 查询子节点 简单简单 查询孙节点复杂 简单 查询父节点 简单简单 查询祖先节点复杂 简单 统计子孙节点数量复杂 简单 适用场景结构简单,层级少,统计少,频繁改动结构复杂,改动少,层级深,需要复杂统计
5总结
经过对两种方案常用场景的分析,发现其实各自都有自己的优缺点,所以原谅我标题稍微有点点标题党;相比起来,个人还是比较喜欢改进的先序数方案
父子关系方案适合结构相对简单、层级少的需求;
而先序数方案就更适合结构复杂,改动少,层级深,需要频繁汇总统计的需求了;
所以说,还是那句话, 没有绝对好的方案,只有合不合适的场景 ;需要更具自己业务的实际情况,酌情挑选对项目最有利的方案。
好了,今天的分享就到这里;如果有任何问题,欢迎随时交流指正!


