前言
数组(Array)是一种 线性表 数据结构,利用一组 连续的内存空间 ,存储一组具有 相同类型 的数据。
概念介绍
首先我们说一下什么是 线性表 ,线性表就是数据排成一条线的数据结构,每个线性表最多只有前和后两个方向,数组、链表、队列、栈等都是线性表结构。那么什么是 非线性表 呢?二叉树、堆、图等数据结构就是非线性表,在非线性表中数据之间并不是简单的前后关系。
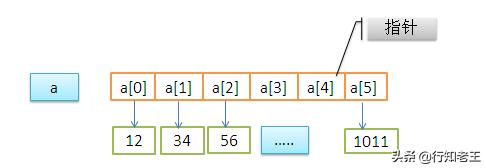
其次,数组的内存空间是连续的,数据类型也是相同的,正是因为这两个特性,数组的随机访问速度非常快。我们来看下数组是怎么进行随机访问的,假定我们有一个长度为10的int类型的数组int[] a = new int[10],计算机给该数组分配的内存空间为100~110,其中内存块的首地址base_address=100。当计算机随机访问数组中的某个元素时,会先通过寻址公式 a[i]_address = base_address + i * data_type_size 计算出该元素的内存地址,其中data_type_size代表数组中每个元素的大小,我们的数组是int类型的,所以每个元素就是4个字节。这样计算出元素的地址后就立马找到该元素了。
面试的时候我们经常被问到数组和链表的区别,有时候我们会回答“链表适合插入、删除, 时间复杂度 是O(1);数组适合查找,查找的时间复杂度是O(1)”,其实这种描述是不准确的,数组适合查找这是没问题的,但是时间复杂度不是O(1),即便是用二分查找对排好序的数组进行查找,时间复杂度也是O(Logn),所以,正确的表述应该是“数组支持随机访问,根据下标随机访问的时间复杂度是O(1)”。
数组声明
数组声明有两种方式:
- 数据类型 [] 数组名称 = new 数据类型[数组长度];
- 数据类型 [] 数组名称 = {数组元素1,数组元素2,……}
数组实现
我们知道,一个数组需要具备如下功能:
- 插入数据
- 查找数据
- 删除数据
- 迭代数据
下边,我们实现一个自己的数组结构:
public class MyArray {
// 定义一个数组
private int[] intArray;
// 定义数组的实际有效长度
private int elems;
// 定义数组的最大长度
private int length ;
// 默认构造一个长度为50的数组
public MyArray() {
elems = 0;
length = 50;
intArray = new int[length];
}
// 构造函数,初始化一个长度为length 的数组
public MyArray(int length) {
elems = 0;
this.length = length;
intArray = new int[length];
}
// 获取数组的有效长度
public int getSize() {
return elems;
}
/**
* 遍历显示元素
*/
public void display() {
for (int i = 0; i < elems; i++) {
System.out.print(intArray[i] + " ");
}
System.out.println();
}
/**
* 添加元素
*
* @param value,假设操作人是不会添加重复元素的,如果有重复元素对于后面的操作都会有影响。
* @return 添加成功返回true,添加的元素超过范围了返回false
*/
public boolean add(int value) {
if (elems == length) {
return false;
} else {
intArray[elems] = value;
elems++;
}
return true;
}
/**
* 根据下标获取元素
*
* @param i
* @return 查找下标值在数组下标有效范围内,返回下标所表示的元素 查找下标超出数组下标有效值,提示访问下标越界
*/
public int get(int i) {
if (i < 0 || i > elems) {
System.out.println("访问下标越界");
}
return intArray[i];
}
/**
* 查找元素
*
* @param searchValue
* @return 查找的元素如果存在则返回下标值,如果不存在,返回 -1
*/
public int find(int searchValue) {
int i;
for (i = 0; i < elems; i++) {
if (intArray[i] == searchValue) {
break;
}
}
if (i == elems) {
return -1;
}
return i;
}
/**
* 删除元素
*
* @param value
* @return 如果要删除的值不存在,直接返回 false;否则返回true,删除成功
*/
public boolean delete(int value) {
int k = find(value);
if (k == -1) {
return false;
} else {
if (k == elems - 1) {
elems--;
} else {
for (int i = k; i < elems - 1; i++) {
intArray[i] = intArray[i + 1];
}
elems--;
}
return true;
}
}
/**
* 修改数据
*
* @param oldValue原值
* @param newValue新值
* @return 修改成功返回true,修改失败返回false
*/
public boolean modify(int oldValue, int newValue) {
int i = find(oldValue);
if (i == -1) {
System.out.println("需要修改的数据不存在");
return false;
} else {
intArray[i] = newValue;
return true;
}
}
}
插入数据
前面我们说了,数组的插入和删除操作效率特别低,这是因为内存空间是连续的,为了保证内存空间的连续性,在插入和删除时会做很多搬移数据的操作。比如,我们有一个长度为n的数组,现在要将一个数据插入到数组的第k个位置,为了把这个位置腾出来给新来的数据,我们需要将第k~n这部分的元素顺序的往后挪一位,如下代码所示:
public static int[] insertVal(int[] arr, int insertIndex, int insertVal){
if(insertIndex < 0 || insertIndex > arr.length){
throw new IllegalArgumentException("插入位置错误");
}
int[] tmpArr = Arrays.copyOf(arr, arr.length + 1);
// 将insertIndex后边的元素一次挪动一位,给新元素腾空,从最后一个元素开始挪
for (int i = tmpArr.length - 1; i > insertIndex; i--) {
tmpArr[i] = tmpArr[i - 1];
}
tmpArr[insertIndex] = insertVal;
return tmpArr;
}
如果在数组的末尾插入元素,那就不需要移动数据了,这时的时间复杂度为O(1)。但如果在数组的开头插入元素,那所有的数据都需要依次往后移动一位,所以最坏时间复杂度是O(n)。因为我们在每个位置插入元素的概率是一样的,所以平均情况时间复杂度为 (1+2+…n)/n=O(n)。如果数组中的数据是有序的,我们在某个位置插入一个新的元素时,就必须按照刚才的方法搬移k之后的数据。但是,如果数组中存储的数据并没有任何规律,数组只是被当作一个存储数据的集合。在这种情况下,如果要将某个数组插入到第k个位置,为了避免大规模的数据搬移,我们还有一个简单的办法就是,直接将第k位的数据搬移到数组元素的最后,把新的元素直接放入第k个位置。如下代码所示:
public static int[] insertVal(int[] arr, int insertIndex, int insertVal){
if(insertIndex < 0 || insertIndex > arr.length){
throw new IllegalArgumentException("插入位置错误");
}
int[] tmpArr = Arrays.copyOf(arr, arr.length + 1);
if(insertIndex == arr.length){
// 插入到最后
tmpArr[insertIndex] = insertVal;
} else {
tmpArr[arr.length] = arr[insertIndex];
tmpArr[insertIndex] = insertVal;
}
return tmpArr;
}
利用这种方式,在特定场景下,在第k个位置插入一个元素的时间复杂度就会降为O(1),快速排序算法就是这么干的。
删除数据
和上面的插入数据一样,如果我们要删除第k个位置的数据,为了保证内存的连续性,第k之后的数据都要往前挪一位,和插入类似,如果删除数组末尾的数据,则最好情况时间复杂度为O(1);如果删除开头的数据,则最坏情况时间复杂度为O(n);平均情况时间复杂度也为 O(n)。如下代码所示:
public static int[] delete(int[] arr, int index) {
// 判断是否合法
if (index >= arr.length || index < 0) {
throw new IllegalArgumentException("位置错误");
}
int[] res = new int[arr.length - 1];
for (int i = 0; i < res.length; i++) {
if (i < index) {
res[i] = arr[i];
} else {
res[i] = arr[i + 1];
}
}
return res;
}
实际上,在某些特殊场景下,我们可以将多次删除操作合并执行,例如数组a[8]中存储了8个元素:a,b,c,d,e,f,g,h。现在,我们要依次删除 a,b,c三个元素。为了避免 d,e,f,g,h 这几个数据会被搬移三次,我们可以先记录下已经删除的数据。每次的删除操作并不是真正地搬移数据,只是记录数据已经被删除。当数组没有更多空间存储数据时,我们再触发执行一次真正的删除操作,这样就大大减少了删除操作导致的数据搬移。
以上其实就是JVM的标记清除算法的实现原理(大多数主流虚拟机采用可达性分析算法来判断对象是否存活,在标记阶段,会遍历所有 GC ROOTS(根对象),将所有GC ROOTS可达的对象标记为存活。只有当标记工作完成后,清理工作才会开始。不足:1.效率问题:标记和清理效率都不高,但是当知道只有少量垃圾产生时会很高效。2.空间问题:会产生不连续的内存空间碎片。)
数组越界问题
在C语言中,只要不是访问受限的内存,所有的内存空间都是可以自由访问的。所以在C语言中即便数据访问越界,程序依然是可以执行的,只是这时候程序会出现莫名其妙的执行结果,数组越界在C语言中是一种未决行为,并没有规定数组访问越界时编译器应该如何处理。因为,访问数组的本质就是访问一段连续内存,只要数组通过偏移计算得到的内存地址是可用的,那么程序就可能不会报任何错误。但是高级语言,如java语言是自带检查机制的,如果访问数据越界会报 java.lang.ArrayIndexOutOfBoundsException 错误。
容器类与数组的使用场景
现在很多的编程语言中都提供了容器类,如java语言中的ArrayList,那么在进行开发的时候,什么时候用容器类,什么时候用数组呢?还是以java中的ArrayList为例,这也是我用的最多的容器类,它最大的优势就是使用方便,已经封装了一系列的操作,而且不用手动为其扩容,ArrayList支持动态扩容。
数组定义的时候需要预先指定大小,进而分配连续的存储空间。如果我们定义的数组大小是10,这时候来了第11个数组元素,我们需要重新分配一块更大的存储空间,将原来的数组复制过去(java中已经封装了工具类System.arraycopy和Arrays.copyOf),然后将新的数据插入。如果使用ArrayList,我们就不需要关心底层的扩容逻辑,ArrayList已经帮我们实现好了,每次空间不够的时候,它就会将空间自动扩容为1.5倍大小,如下为ArrayList中扩容的代码:
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = **Arrays.copyOf**(elementData, newCapacity);
}
由以上ArrayList的源码可以看出,其实其内部在扩容时也是封装了数组的拷贝 Arrays.copyOf 。 oldCapacity >> 1 右移一位操作,如果该数为正,则高位补0,若为负数,则高位补1,说白了就是除以2。由此可以看出新的列表是老的列表的1.5倍。
不过因为扩容涉及到内存申请和数据搬移,是比较耗时的,所以,如果我们事先能确定需要存储的数据大小,最好在创建ArrayList的时候就事先指定数据大小。以下代码为ArrayList的两种创建方式:
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
......
......
/**
* Constructs an empty list with the specified initial capacity.
*
* @param initialCapacity the initial capacity of the list
* @throws IllegalArgumentException if the specified initial capacity
* is negative
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
可以看出,如果不指定大小,ArrayList默认就是一个空的对象。在添加元素时,该对象会将大小设置为 10 ,下面为ArrayList的源码:
/**
* Default initial capacity.
*/
private static final int **DEFAULT_CAPACITY** = 10;
......
......
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return **Math.max(DEFAULT_CAPACITY, minCapacity);**
}
return minCapacity;
}
言归正传,我们接着说数组,ArrayList这一类的集合类已经这么强大了,我们还要数组干什么呢?
其实很多时候,用数组比用ArrayList这一类的集合类更合适:
- 1. 比如int、long这一类的基础数据类型,如果用ArrayList存储,则需要进行装箱操作,将其封装为Integer、Long类,装箱拆箱操作时需要时间的,有一定性能消耗。所以这时候就可以选择数组。
- 2. 如果事先知道数据大小,并且集合类中的大部分方法用不到,操作非常简单的话就可以用数组。
- 3. 在表示多维数组时,用数组会更加直观,如果用集合类,则需要进行嵌套。
当然,其实很多时候我们没必要过于追求性能,损耗一丢丢的性能,大部分情况下对系统整体性能没有什么影响,集合类已经帮我们实现了很多的操作,用起来是非常方便的。但是如果是做底层开发,性能就必须做到极致,这时候优先选择数组。
二维数组
对于 m * n 的数组,m表示这个二维数组有多少个一维数组,表示每一个一维数组的元素有多少个。元素 a[i][j] (i<m,j<n)的地址计算方式为:
- address = base_address + ( i * n + j) * type_size
二维数组在进行内存分配时,必须知道其一维数组的大小,首先给一个地址值给数组a,然后开始为二位数组的一维数组部分进行分配空间,如果在定义二维数组时,并没有告诉其二维数组部分的大小,如: 数据类型[][] 数组名 = new 数据类型[m][] 这时候就无法为其一维数组分配静态的内存空间,这时候打印其地址值都是null,但是可以动态的分配空间。
下标之谜
现在我们思考一个问题,数组的下标为什么从0开始,按照人的思维逻辑,从1开始应该是更合理才是?
从数组存储数据的内存模型上来看,“下标”最确切的定义应该是“偏移(offset)”,也就是元素距离数组首地址的偏移量。a[0]也就是偏移量为0的位置,也就是首地址,a[k]表示偏移k个元素类型长度的位置,所以a[k]的内存地址计算公式为:
a[k]_address = base_address + k * type_size
但是,如果数组从1开始计数呢,那计算a[k]的内存地址公式就变为:
a[k]_address = base_address + (k-1)*type_size
对比以上两个计算公式,我们会发现,如果数组下标从1开始,每次随机访问数组元素时都多了一次减法运算,对于CPU来说,就多了一次减法指令。数组值得称赞的地方就是通过下标随机访问元素的速度,而通过下标随机访问数组元素又是非常基础的编程操作,效率的优化自然要做到极致。为了减少一次减法操作,数组选择从0开始编号也就是理所当然了。当然还有一方面原因,就是C语言中的数组下标从0开始,其他语言都是在C语言之后出现的,为了减少学习学习成本,尽量模仿C语言中的语法因此也继续用0开始做下标。
数组常用操作
排序
- 直接排序
public static void sort(int[] arr) {
for (int x = 0; x < arr.length - 1; x++) {
for (int y = x + 1; y < arr.length; y++) {
if (arr[x] > arr[y]) {
int temp = arr[x];
arr[x] = arr[y];
arr[y] = temp;
}
}
}
}
- 冒泡排序
public static void sort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
boolean f = true;// 每一轮都定义一个开关
// 每次内循环的比较,从0索引开始,每次都在递减。注意内循环的次数应该是(arr.length - 1 - i)。
for (int j = 0; j < arr.length - 1 - i; j++) {
// 比较的索引是j和j+1
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
f = false;// 发生交换,修改开关的状态
}
}
// 此轮结束,查看开关的状态
if (f) {
// 开关状态没变,说明已经完成了排序
// 所以,不用继续下一轮了。
break;
}
}
}
- 比较排序(选择排序)
public static void sort(int[] arr) {
// 外层循环控制的是比较的轮数:元素的个数-1
for (int i = 0; i < arr.length - 1; i++) {
// 内层控制的是两两比较的次数
for (int j = i + 1; j < arr.length; j++) {
if (arr[i] > arr[j]) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
}
}
}
上面这种选择排序方式可以优化为下面的方式:
public static void sort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
int index = i;
int value = arr[i];
for (int j = i + 1; j < arr.length; j++) {
if (arr[j] < value) {
index = j;
value = arr[j];
}
}
// 判断,是否有必要交换两个元素
if (index != i) {
int tmp = arr[i];
arr[i] = arr[index];
arr[index] = tmp;
}
}
}
这样可以减少很多数据交换次数。
- 插入排序
public static void sort(int[] a) {
for (int i = 1; i < a.length; i++) {
for (int j = i; j > 0; j--) {
if (a[j] < a[j - 1]) {
int temp = a[j - 1];
a[j - 1] = a[j];
a[j] = temp;
} else
break;
}
}
}
- 快速排序
快速排序的基本思路如下:
- 假设我们对数组{7, 1, 3, 5, 13, 9, 3, 6, 11}进行快速排序。
- 首先在这个序列中找一个数作为基准数,为了方便可以取第一个数。
- 遍历数组,将小于基准数的放置于基准数左边,大于基准数的放置于基准数右边。
- 此时得到类似于这种排序的数组{3, 1, 3, 5, 6, 7, 9, 13, 11}。
- 在初始状态下7是第一个位置,现在需要把7挪到中间的某个位置k,也即k位置是两边数的分界点。
- 那如何做到把小于和大于基准数7的值分别放置于两边呢,我们采用双指针法,从数组的两端分别进行比对。
- 先从最右位置往左开始找直到找到一个小于基准数的值,记录下该值的位置(记作 i)。
- 再从最左位置往右找直到找到一个大于基准数的值,记录下该值的位置(记作 j)。
- 如果位置i<j,则交换i和j两个位置上的值,然后继续从(j-1)的位置往前和(i+1)的位置往后重复上面比对基准数然后交换的步骤。
- 如果执行到i==j,表示本次比对已经结束,将最后i的位置的值与基准数做交换,此时基准数就找到了临界点的位置k,位置k两边的数组都比当前位置k上的基准值或都更小或都更大。
- 上一次的基准值7已经把数组分为了两半,基准值7算是已归位(找到排序后的位置)。
- 通过相同的排序思想,分别对7两边的数组进行快速排序,左边对[left, k-1]子数组排序,右边则是[k+1, right ]子数组排序。
- 利用递归算法,对分治后的子数组进行排序。
快速排序的优势
快速排序之所以比较快,是因为相比冒泡排序,每次的交换都是跳跃式的,每次设置一个基准值,将小于基准值的都交换到左边,大于基准值的都交换到右边,
这样不会像冒泡一样每次都只交换相邻的两个数,因此比较和交换的此数都变少了,速度自然更高。当然,也有可能出现最坏的情况,就是仍可能相邻的两个数进行交换。
快速排序基于分治思想,它的时间平均复杂度很容易计算得到为O(nlogn)。
实现代码如下:
public static void quickSort(int[] array) {
int len;
if (array == null || (len = array.length) == 0 || len == 1) {
return;
}
sort(array, 0, len - 1);
}
// 递归实现快速排序
public static void sort(int[] array, int left, int right) {
if (left > right) {
return;
}
// base中存放基准数
int base = array[left];
int i = left, j = right;
while (i != j) {
// 顺序很重要,先从右边开始往左找,直到找到比base值小的数
while (array[j] >= base && i < j) {
j--;
}
// 再从左往右边找,直到找到比base值大的数
while (array[i] <= base && i < j) {
i++;
}
// 上面的循环结束表示找到了位置或者(i>=j)了,交换两个数在数组中的位置
if (i < j) {
int tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
}
// 将基准数放到中间的位置(基准数归位)
array[left] = array[i];
array[i] = base;
// 递归,继续向基准的左右两边执行和上面同样的操作
// i的索引处为上面已确定好的基准值的位置,无需再处理
sort(array, left, i - 1);
sort(array, i + 1, right);
}
- JDK自带排序
Arrays.sort(arr);
在JDK1.7之前,JDK中自带的排序算法是 经典快排 ,但是在JDK1.7的时候,JDK中自带的数组排序算法已经换成了 Dual-Pivot Quicksort(双轴快速排序算法) ,该算法的时间复杂度是O(nLogn)。
JDK1.8中的排序算法如下:
/**
* 归并排序中的最大运行次数
*/
private static final int MAX_RUN_COUNT = 67;
/**
* 归并排序中运行的最大长度
*/
private static final int MAX_RUN_LENGTH = 33;
/**
* 如果要排序的数组长度小于此常量,则使用快速排序优先于合并排序。
*/
private static final int QUICKSORT_THRESHOLD = 286;
static void sort(int[] a, int left, int right, int[] work, int workBase, int workLen) {
// Use Quicksort on small arrays
if (right - left < QUICKSORT_THRESHOLD) {
sort(a, left, right, true);
return;
}
/*
* Index run[i] is the start of i-th run (ascending or descending
* sequence).
*/
int[] run = new int[MAX_RUN_COUNT + 1];
int count = 0;
run[0] = left;
// Check if the array is nearly sorted
for (int k = left; k < right; run[count] = k) {
if (a[k] < a[k + 1]) { // ascending
while (++k <= right && a[k - 1] <= a[k])
;
} else if (a[k] > a[k + 1]) { // descending
while (++k <= right && a[k - 1] >= a[k])
;
for (int lo = run[count] - 1, hi = k; ++lo < --hi;) {
int t = a[lo];
a[lo] = a[hi];
a[hi] = t;
}
} else { // equal
for (int m = MAX_RUN_LENGTH; ++k <= right && a[k - 1] == a[k];) {
if (--m == 0) {
sort(a, left, right, true);
return;
}
}
}
/*
* The array is not highly structured, use Quicksort instead of
* merge sort.
*/
if (++count == MAX_RUN_COUNT) {
sort(a, left, right, true);
return;
}
}
// Check special cases
// Implementation note: variable "right" is increased by 1.
if (run[count] == right++) { // The last run contains one element
run[++count] = right;
} else if (count == 1) { // The array is already sorted
return;
}
// Determine alternation base for merge
byte odd = 0;
for (int n = 1; (n <<= 1) < count; odd ^= 1)
;
// Use or create temporary array b for merging
int[] b; // temp array; alternates with a
int ao, bo; // array offsets from 'left'
int blen = right - left; // space needed for b
if (work == null || workLen < blen || workBase + blen > work.length) {
work = new int[blen];
workBase = 0;
}
if (odd == 0) {
System.arraycopy(a, left, work, workBase, blen);
b = a;
bo = 0;
a = work;
ao = workBase - left;
} else {
b = work;
ao = 0;
bo = workBase - left;
}
// Merging
for (int last; count > 1; count = last) {
for (int k = (last = 0) + 2; k <= count; k += 2) {
int hi = run[k], mi = run[k - 1];
for (int i = run[k - 2], p = i, q = mi; i < hi; ++i) {
if (q >= hi || p < mi && a[p + ao] <= a[q + ao]) {
b[i + bo] = a[p++ + ao];
} else {
b[i + bo] = a[q++ + ao];
}
}
run[++last] = hi;
}
if ((count & 1) != 0) {
for (int i = right, lo = run[count - 1]; --i >= lo; b[i + bo] = a[i + ao])
;
run[++last] = right;
}
int[] t = a;
a = b;
b = t;
int o = ao;
ao = bo;
bo = o;
}
}
有关 Dual-Pivot Quicksort(双轴快速排序算法) 的讲解可参考如下几篇文章:
数组反转
public static void fanzhuan(int[] a) {
for (int i = 0; i < a.length / 2; i++) {
int tp = a[i];
a[i] = a[a.length - i - 1];
a[a.length - i - 1] = tp;
}
}
也可以将数组转为ArrayList,然后调用Collections.reverse(arrayList);进行反转
查找
最笨的方法,就是从前往后一个个的查找,这种方式不到不得以,不要使用,太笨。
- 二分查找
二分查找的实现思路:
1. 定义查找的范围,也就是开始索引(如 int start = 0)和结束索引(如 int end = srr.length – 1)。
2. 判断 start 是否小于等于 end ,如果 start 大于 end,则结束查找,直接返回-1代表没有找到所查找的元素。如果满足条件,则计算出 start 和 end 之间的中间索引 middle ,并获取该中间索引对应的值 middleVal。
- int middle = (start + end)/2.
- int middleVal = arr(middle);
3. 把中间索引对应的值 middleVal 和要查找的元素 key 进行比较:
- 如果 middleVal 等于 key,就返回当前的中间索引 middle;
- 如果 middleVal 大于 key:
- 对于升序数组:end = middle – 1;
- 对于降序数组:start = middle + 1;
- 如果 middleVal 小于 key:
- 对于升序数组:start = middle + 1;
- 对于降序数组:end = middle – 1;
4. 重新执行第二步操作。
使用二分查找前,必须对数据进行排序 ,如果未排序,则有可能找不到所查找的元素。如果数组包含多个指定值的元素,则不确定返回哪个位置上的该元素。
public static int binarySearch(int[] arr, int key) {
// 在不断缩小范围的过程中,可以
// 返回-1则说明找不到这个数
// 定义起始、终点、中间索引,目标key值索引
int start = 0;
int end = arr.length - 1;
// 在数组中找要找的数,因为不一定会一下子找到,所以这应该是一个重复寻找的过程,即会用到循环
while (start <= end) {// 看出start不断增大,end不断缩小;如果当start和end相等时都还找不到,start会继续增加,end继续变小,此时这已经不是一个正常的数组,结束循环
int middle = (start + end) / 2;
int value = arr[middle];
// 让中间索引对应的值value与要查找的值key进行比较
if (key == value) {
// 如果相等,即找到,则返回中间索引,并跳出循环
return middle;
} else if (key > value) { // key > value
if (arr[0] < arr[1]) { // 升序
start = middle + 1;
} else { // 降序
end = middle - 1;
}
} else { // key < value
if (arr[0] < arr[1]) { // 升序:end = middle - 1
end = middle - 1;
} else {// 降序:start = middle + 1
start = middle + 1;
}
}
} // while括号
return -1;
}
- jdk自带的二分查找
Arrays.binarySearch(arr, val);
public static int binarySearch(int[] a, int key) {
return binarySearch0(a, 0, a.length, key);
}
......
private static int binarySearch0(int[] a, int fromIndex, int toIndex, int key) {
int low = fromIndex;
int high = toIndex - 1;
while (low <= high) {
int mid = (low + high) >>> 1;
int midVal = a[mid];
if (midVal < key)
low = mid + 1;
else if (midVal > key)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found.
}
数组操作工具类
public class GenericArray<T> {
private T[] data;
private int size;
// 根据传入容量,构造Array
public GenericArray(int capacity) {
data = (T[]) new Object[capacity];
size = 0;
}
// 无参构造方法,默认数组容量为10
public GenericArray() {
this(10);
}
// 获取数组容量
public int getCapacity() {
return data.length;
}
// 获取当前元素个数
public int count() {
return size;
}
// 判断数组是否为空
public boolean isEmpty() {
return size == 0;
}
// 修改 index 位置的元素
public void set(int index, T e) {
checkIndex(index);
data[index] = e;
}
// 获取对应 index 位置的元素
public T get(int index) {
checkIndex(index);
return data[index];
}
// 查看数组是否包含元素e
public boolean contains(T e) {
for (int i = 0; i < size; i++) {
if (data[i].equals(e)) {
return true;
}
}
return false;
}
// 获取对应元素的下标, 未找到,返回 -1
public int find(T e) {
for (int i = 0; i < size; i++) {
if (data[i].equals(e)) {
return i;
}
}
return -1;
}
// 在 index 位置,插入元素e, 时间复杂度 O(m+n)
public void add(int index, T e) {
checkIndex(index);
// 如果当前元素个数等于数组容量,则将数组扩容为原来的2倍
if (size == data.length) {
resize(2 * data.length);
}
for (int i = size - 1; i >= index; i--) {
data[i + 1] = data[i];
}
data[index] = e;
size++;
}
// 向数组头插入元素
public void addFirst(T e) {
add(0, e);
}
// 向数组尾插入元素
public void addLast(T e) {
add(size, e);
}
// 删除 index 位置的元素,并返回
public T remove(int index) {
checkIndexForRemove(index);
T ret = data[index];
for (int i = index + 1; i < size; i++) {
data[i - 1] = data[i];
}
size--;
data[size] = null;
// 缩容
if (size == data.length / 4 && data.length / 2 != 0) {
resize(data.length / 2);
}
return ret;
}
// 删除第一个元素
public T removeFirst() {
return remove(0);
}
// 删除末尾元素
public T removeLast() {
return remove(size - 1);
}
// 从数组中删除指定元素
public void removeElement(T e) {
int index = find(e);
if (index != -1) {
remove(index);
}
}
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append(String.format("Array size = %d, capacity = %d n", size, data.length));
builder.append('[');
for (int i = 0; i < size; i++) {
builder.append(data[i]);
if (i != size - 1) {
builder.append(", ");
}
}
builder.append(']');
return builder.toString();
}
// 扩容方法,时间复杂度 O(n)
private void resize(int capacity) {
T[] newData = (T[]) new Object[capacity];
for (int i = 0; i < size; i++) {
newData[i] = data[i];
}
data = newData;
}
private void checkIndex(int index) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("Add failed! Require index >=0 and index <= size.");
}
}
private void checkIndexForRemove(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("remove failed! Require index >=0 and index < size.");
}
}
}

微信公众号:行知老王


