Milvus 是什么?
Milvus 是一款开源的、针对海量特征向量的相似性搜索引擎。Milvus 能够很好地应对海量向量数据,它集成了目前在向量相似性计算领域比较知名的几个开源库(Faiss, SPTAG 等),通过对数据和硬件算力的合理调度,以获得最优的搜索性能。
用户只需要从 docker hub 上下载一个 Milvus 的最新镜像,一行命令即可启动,然后可以通过 Python SDK 或者 Java SDK 进行向量插入以及搜索操作,非常方便。更重要的是,Milvus 是开源的!这意味着用户可以参与到这个产品的开发以及设计中来,把自己的想法带到产品中,打造出更符合自己使用习惯的向量检索数据库。
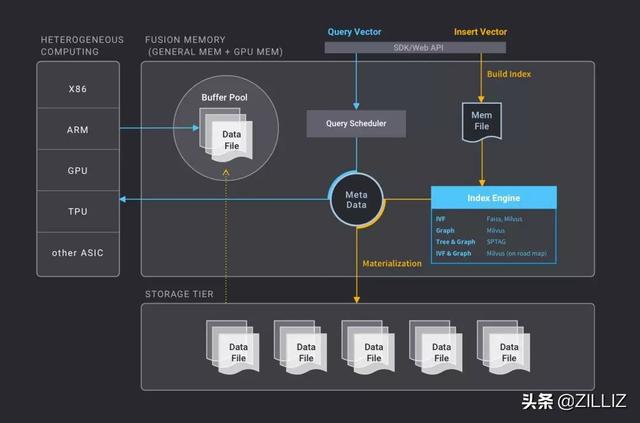
向量相似度搜索引擎 Milvus 架构图
Milvus 是如何管理数据的?
先来说一些基本概念。
表: 向量数据的集合,每条向量必须有一个唯一的ID来区分,每一条向量以及它的 ID 就是表里的一行数据,每个表里的所有向量必须是同一维度的。
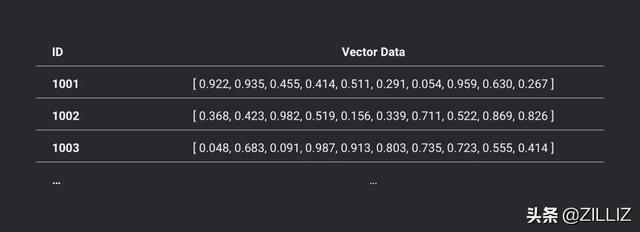
一张维度为10的表的示意图
索引: 建立索引的过程可以理解为通过某种算法把大批向量分成很多簇。索引需要额外使用磁盘空间,有些类型的索引会使得磁盘占用量翻倍。
用户可以有这些操作:创建表,插入向量,建立索引,搜索向量,获取表信息,获取索引信息,删除表,删除表里部分数据,删除索引,等等。
现在假设我们有一亿条512维度的向量,需要把这些数据管理起来,并且进行向量检索。
Insert 向量数据的录入
我们先看向量数据是怎么录入的。我们之前算过每条这样的向量要占据 2KB 的空间,一亿条就是 200GB,显然想一次性导入不现实,写入磁盘的数据文件也不可能只有一个文件,肯定要分成多个文件。插入性能也是主要性能指标之一,Milvus 允许批量地插入向量,一次性地插入几百甚至几万条向量都是允许的,对于 512 维的高维向量,通常可以达到每秒三万条的插入速度。
并不是每次插入向量数据都去写磁盘,系统会给每个表在内存里开辟一块空间作为可写缓冲(mutable buffer),数据可以很快速地直接写入 mutable buffer 里,当积累到一定数据量之后,这个可写缓冲就会被标记为只读的(immutable buffer),并且会自动开辟新的可写缓冲等待新的数据。immutable buffer 会被定时写入磁盘,写入完成后这块内存会被释放,这里的定时写磁盘机制与 Elasticsearch 类似(Elasticsearch 默认是每隔 1 秒将缓冲数据写入磁盘)。另外,熟悉 LevelDB/RocksDB 的读者能看出来这里面有 MemTable 的影子。这样做的目的主要是为了兼顾以下几点:
- 数据导入效率高
- 数据导入后尽快可见
- 数据文件不过于碎片化
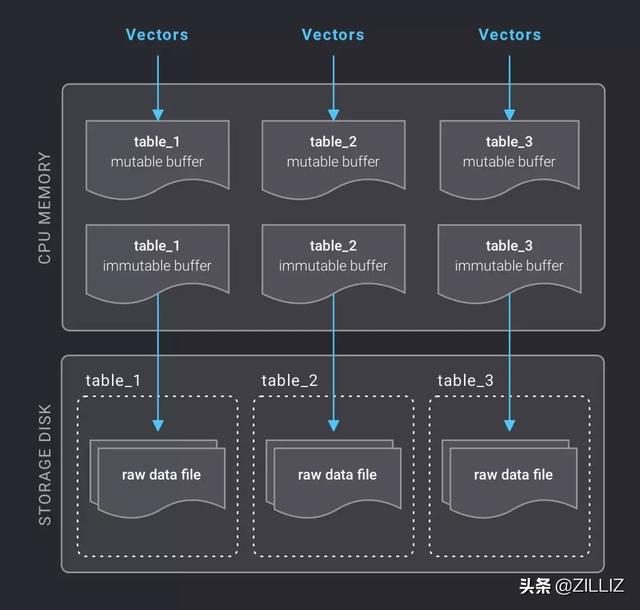
Raw Data File 原始数据文件
数据写入磁盘后 ,成为原始数据文件(Raw Data File),保存的是向量的原始数据。前面我们说过,海量的数据肯定是分散成多个文件来管理的。Milvus 有一个配置选项,用来确定每个原始数据文件的大小,默认是 1GB,也就是说,一亿条 512 维向量会被分散成大约 200 个文件来存储。
插入向量的数据量是可大可小的,用户可能一次插入 10 条向量,也可能一次插入 100 万条向量。而写磁盘的操作是间隔一秒持续进行的,并不会等到插入满 1GB 的数据之后再写磁盘,因此会形成很多大小不一的文件。零碎的文件并不利于管理,也不利于向量检索操作,因此系统会不断地把这些小文件合并,直到合并后的文件大小达到或超过 1GB。
考虑增量库的使用场景,同时会有向量插入和向量检索操作,我们需要保证一旦数据落盘,就必须能够被检索到。所以,在小文件被合并完成之前,会使用这些小文件进行检索;一旦合并完成,就会删除这些小文件,从合并之后的文件进行检索。
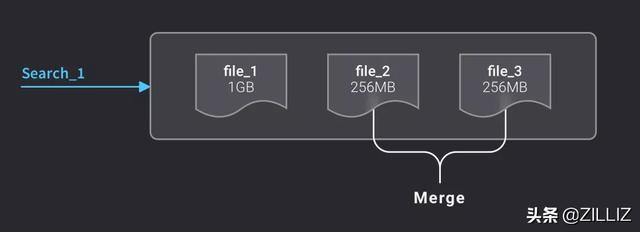
合并前的检索
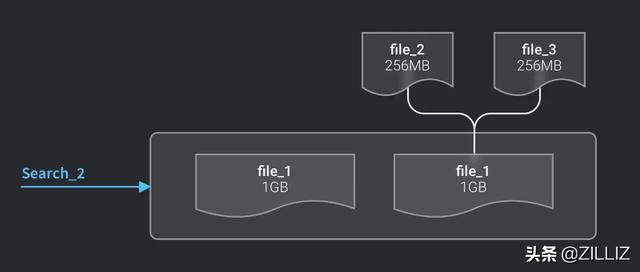
合并成功后的检索
Index File 索引文件
上面说的对 Raw Data File 的检索是一种暴力计算(brute-force search),即用目标向量和原始向量一条一条地计算距离,得出最近的k条向量,这是很低效的。建立索引可以大幅提高检索效率,之前我们说过索引是要占用额外磁盘空间的,而且建立索引也是比较耗时。
原始数据文件和索引文件的格式有何区别?简单来说,原始数据文件就是把n个向量一个接一个地记录下来,包括向量的 ID 以及向量数据;索引文件则记录了聚类运算后的结果,包括索引的类型,每个簇的中心向量,以及每个簇分别有哪些向量。下图是这两种文件格式上的简化表示:
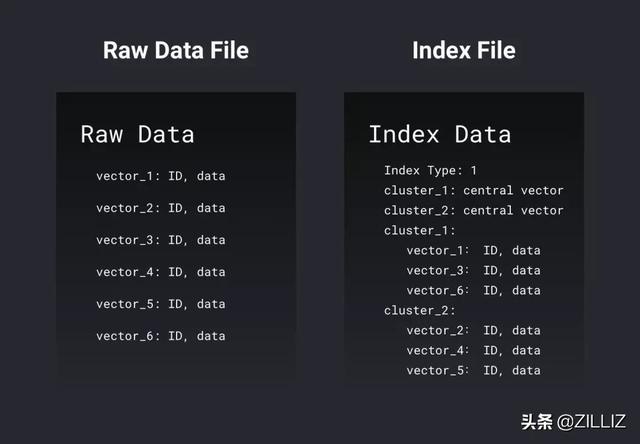
一张维度为10的表的示意图
总的来说索引文件包含的信息比原始数据文件要多,不过有的索引类型对向量数据进行了简化或者压缩,所以总的文件 size 会小很多。
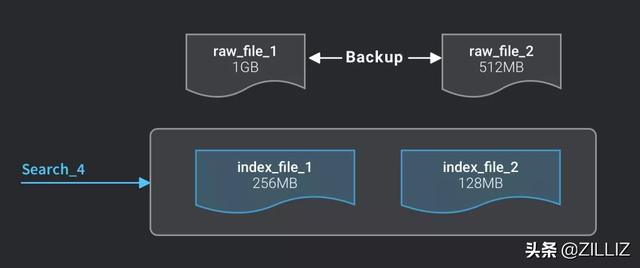
当用户建了一张新表,这张表的索引类型默认是无索引,检索都是通过暴力计算的方式进行;一旦建立了索引之后,系统会对合并后达到 1GB 的原始数据文件自动建立索引。建立好索引后,会生成一个新的索引文件,而原来的原始数据文件不会被删掉,以便以后切换成别的索引类型。
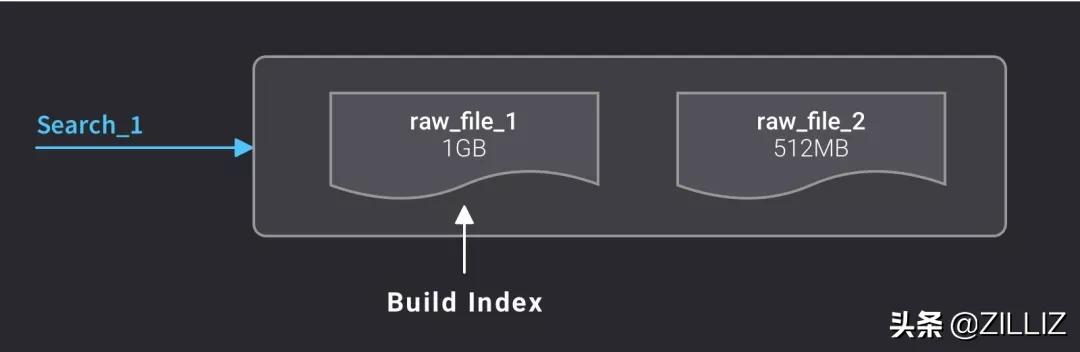
系统自动对达到1GB的原始数据文件建立索引
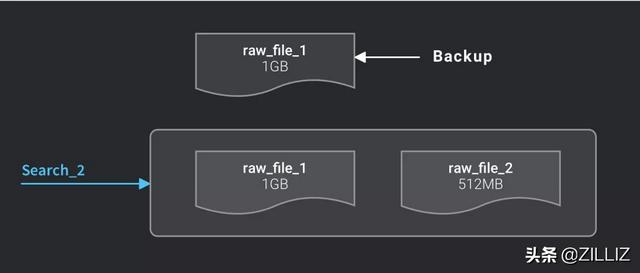
1GB的原始数据文件索引完成
未达到 1GB 的文件不会被自动建立索引,会影响检索速度。如果想得到更好的检索效率,就要对该表进行强制建立索引:
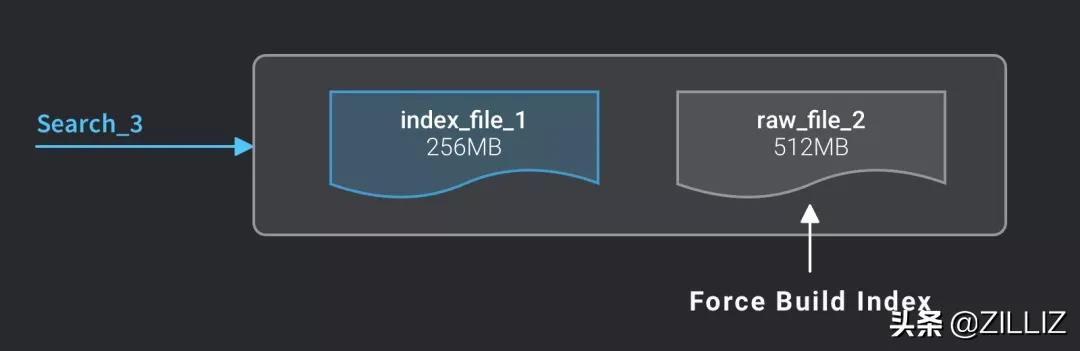
强制建立索引后检索速度最快
Meta Data 数据的信息
前面我们说一亿条 512 维向量大约会有 200 个磁盘文件,如果建立了索引,就是大约 400 个文件, Milvus 在运行过程中要修改这些文件的状态,删除文件,创建文件等等,所以就需要一套机制来管理文件的状态和信息,这就是元数据(metadata)。使用 OLTP 数据库来管理这些信息是一个很好的选择,在单机模式下,Milvus 使用 SQLite 来管理元数据,而在分布式模式下,Milvus 使用 Mysql 来管理元数据。程序启动后,会在 SQLite/MySQL 中建立两张表,分别叫 Tables 和 TableFiles。Tables是用来记录全部表的信息,TableFiles 则是记录全部数据文件以及索引文件的信息。
如下图所示,Tables 元数据信息中包括了表名(table_id),表的向量维度(dimension),创建日期(created_on),状态(state),索引类型(engine_type),聚类的分簇数量(nlist),距离计算方式(metric_type)等。TableFiles则记录了文件所属的表名(table_id),文件的索引类型(engine_type),文件名(file_id),文件类型(file_type),文件大小(file_size),向量行数(row_count),创建日期(created_on)。
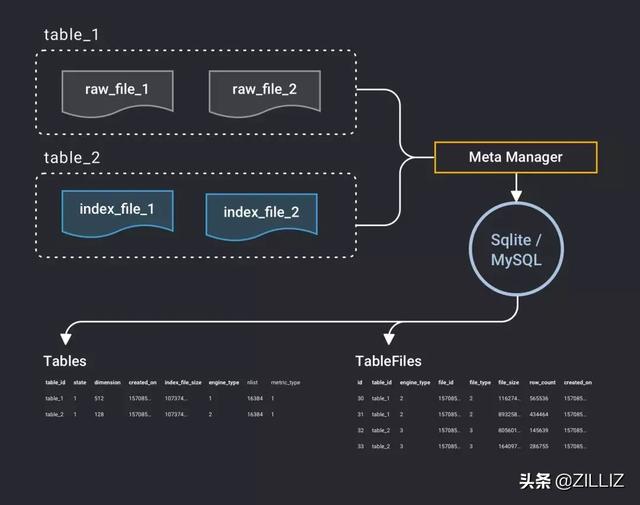
有了这些元数据,就可以根据元数据来进行各种操作了。
比如如果要对 table_2 表执行向量检索,Mega Manager 先去 SQLite/MySQL 中做一个查询,实际上就是运行一条 SQL 语句:SELECT * FROM TableFiles WHERE table_id=’table_2’ ,这样就得到了 table_2 表所有的文件信息,然后这些文件就会被查询调度器(Query Scheduler)调入内存,就可以进行运算了。
如果要删除 table_2 表,我们是不能立即把这个表以及它的文件全部删除的,因为这个时候有可能正在执行对这张表的检索,因此删除操作有软删除(soft-delete)和硬删除(hard-delete)。执行了删除表的操作后,该表会被标记为 soft-delete 状态,之后对该表的检索或修改操作都是不允许的。但删除之前所执行的查询操作仍在进行,只有当所有对该表的查询操作完成之后,该表才会被真正地删除,包括它的元数据信息,包括它的各种文件。
Query Scheduler 查询调度
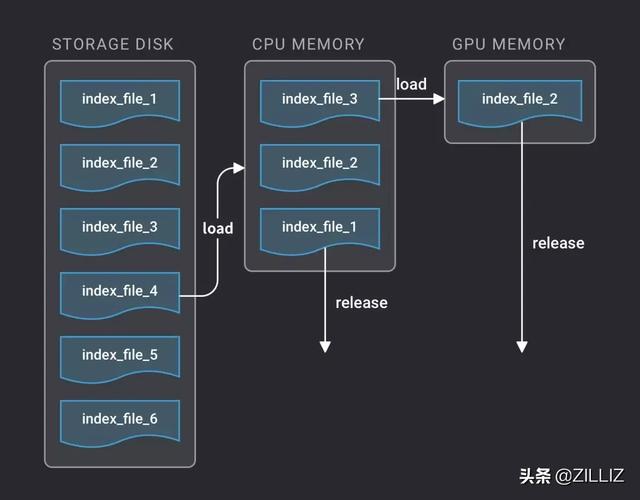
下图表示了一个有若干文件(包括原始数据文件和索引文件)的表做一次 top-k 查询时,数据在磁盘、内存、 显存 中发生拷贝,分别在 CPU 和 GPU 进行向量搜索得出最终结果的过程。
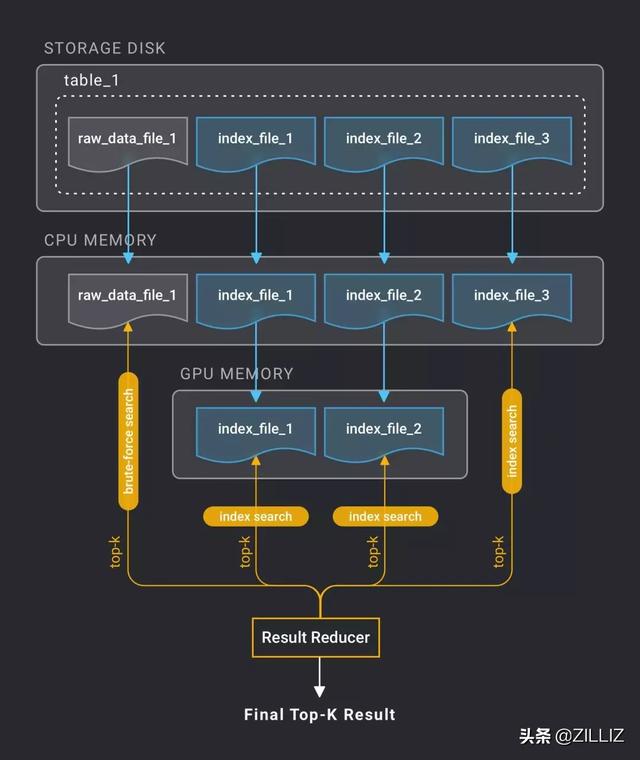
查询调度算法对性能的影响极为明显,其基本原则是最大程度地利用硬件资源获得最好的查询性能,我们会有专门文章讲解 Milvus 的查询调度机制。
我们把对某张表的第一次查询称为冷查询,其后的查询叫热查询。当 Milvus 服务启动后,第一次查询时数据都在硬盘上,需要把数据加载到内存,另外还有部分数据会加载到显存,从硬盘加载数据到内存相对是比较耗时的;而第二次查询时,部分或者全部数据已经在内存里,就省去了读硬盘的时间,查询就会变得很快。
为了避免第一次查询时间过长,Milvus 提供了预加载机制,用户可以指定服务启动后自动加载数据到内存。
对于一亿级别的表(512 维),数据量是 200GB,好一点的服务器有足够的内存装载全部数据。这种条件下的查询速度是最快的。而对于十亿以上级别的表,查询时就无法避免地要对数据做置换,也就是把使用完的部分数据从内存中释放,换上其他未查询的数据。目前我们使用 LRU(Least Recently Used)策略作为数据的置换策略 。
如下图所示,假设某张表有六个索引文件存在服务器磁盘上,该服务器的内存只够装得下三个文件,而显存只能装一个文件。查询开始时,先从磁盘读入三个文件装进内存,对第一个文件查询完成后,把它从内存中释放,同时从磁盘装入第四个文件。同理,第二个文件交给显卡处理,对该文件查询完成后把它从显存中释放,再从内存调入其他文件。
Result Reducer 结果集的归并
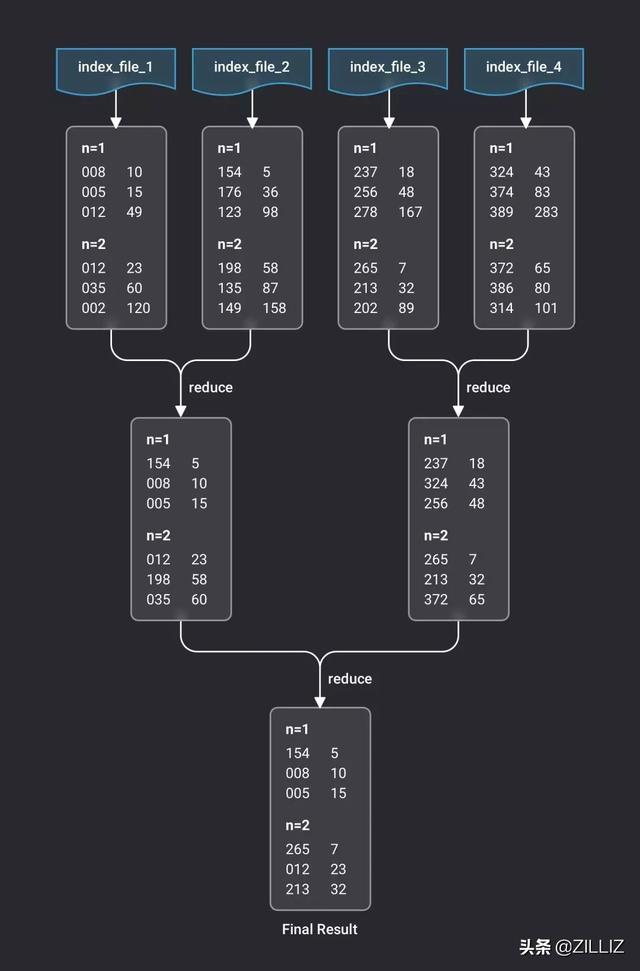
前面我们说向量检索有两个关键参数:一个是 n,指 n 条目标向量;另一个是 k,指最相似的前 k 个向量。对于一次查询来说,结果集是 n 组 key-value 键值对,每组键值对有 k 对键值。一张表包含了多个文件,不管是原始数据文件还是索引文件,都要单独做一次检索。因此,每个文件检索出 n 组 top-k 结果集。然后,将多个文件的结果集进行归并,得出全表最接近的 top-k。
下图是一个示例,假设某张表有四个索引文件,对其做一个 n=2, k=3 的查询。示例中结果集的两列数字,左边代表相似向量的编号,右边代表欧氏距离,我们之前已经知道,欧氏距离越小,意味着和目标向量越相似。调度器先分别对四个文件检索得出四组结果集,然后分别两两归并,经过两轮归并后,得到最终的结果集。
通过以上的介绍,大家应该已经初步了解了向量检索的含义以及构建一个能够应对大规模向量检索场景的系统需要应对哪些问题,另外还认识了 Milvus 这个系统。Milvus 的目标是要做成一个完备的分布式向量检索数据库,这里面还有很多涉及功能性、稳定性的事情需要做。这篇文章主要集中介绍了 Milvus 数据管理的策略,我们另外还有专门的文章介绍 Milvus 分布式、向量索引算法以及查询调度器的知识。作为一个开源项目,我们恳切邀请对此领域感兴趣的朋友一起构建一个繁荣的社区,使这个产品不断完善。有兴趣的朋友可以访问 Milvus 的开源项目: 。


