
0
介绍
分享这篇文章是因为在SQL JOIN,你想知道的应该都有这篇文章中有个小伙伴问我,ON和WEHRE执行的顺序是怎样的,并且SQL执行顺序在面试中也经常被问,所以把姜承尧大佬《MySQL技术内幕 SQL编程》中关于SQL执行顺序的部分简单概述了一下,并配上例子,有想深入了解的可以去看书
SQL语言不同于其他编程语言(如C++,Java),最明显的不同体现在处理代码的顺序上。在大多数编程语言中,代码按编码顺序被处理。但在SQL语言中,第一个被处理的子句总数FROM子句,下面显示了逻辑查询处理的顺序以及步骤的序号
(8)SELECT (9) DISTINCT <select_list>
(1)FROM <left_table>
(3)<join_type> JOIN <right_table>
(2)ON <join_condition>
(4)WHERE <where_condition>
(5)GROUP BY <group_by_list>
(6)WITH {CUBE|ROLLUP}
(7)HAVING <having_condition>
(10)ORDER BY <order_by_list>
(11)LIMIT <limit_number>
可以看到一共有11个步骤,最先执行的是FROM操作,最后执行的是LIMIT操作。每个操作都会产生一张虚拟表。该虚拟表作为一个处理的输入。这些虚拟表对用户不是透明的,只有最后一步生成的虚拟表才会返回给用户。如果没有在查询中指定某一子句, 则将跳过相应的步骤。
我们来具体分析查询处理的各个阶段
- FROM:对FROM子句中的左表<left_table>和右表<right_table>执行笛卡尔积,产生虚拟表VT1
- ON:对虚拟表VT1应用ON筛选,只有那些符合<join_condition>的行才被插入虚拟表VT2中
- JOIN:如果指定了OUTER JOIN(如LEFT OUTER JOIN ,RIGTH OUTER JOIN),那么保留表中未匹配的行作为外部行添加到虚拟表VT2中,产生虚拟表VT3。如果FROM子句含两个以上表,则对上一个连接生成的结果表VT3和下一个表重复执行步骤1~步骤3,直到处理完所有的表为止
- WHERE: 对虚拟表VT3应用VT3应用WEHRE过滤条件,只有符合<where_conditon>的记录才被插入虚拟表VT4中
- GROUP BY:根据GROUP BY 子句中的列,对VT4中的记录进行分组操作,产生VT5
- CUBE|ROLLUP:对表VT5进行CUBE或ROLLUP操作,产生表VT6
- HAVING:对虚拟表VT6应用HAVING过滤器,只有符合<having_condition>的记录才被插入虚拟表VT7中
- SELECT:选定指定的列,插入到虚拟表VT8中
- DISTINCT:去除重复数据,产生虚拟表VT9
- ORDER BY:将虚拟表VT9中的记录按照<order_by_list>进行排序操作,产生虚拟表VT10
- LIMIT:取出指定行的数据,产生虚拟表VT11,并返回给查询用户
准备的数据如下:
CREATE TABLE `customers` (
`customer_id` varchar (10) NOT NULL,
`city` varchar(10) NOT NULL,
PRIMARY KEY (`customer_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `orders` (
`order_id` int(10) NOT NULL AUTO_INCREMENT,
`customer_id` varchar(10) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;


1
执行笛卡尔积
第一部需要做的是对From子句前后的两张表进行笛卡尔积操作,也称作交叉连接(Cross Join),生产虚拟表VT1。如果FROM子句前的表中包含a行数据,From子句后的表中包含b行数据,那么虚拟表VT1中将包含a*b行数据。
SELECT c.customer_id AS c_customer_id, c.city, o.order_id, o.customer_id AS o_customer_id FROM customers c JOIN orders o

2
应用ON过滤器
SELECT查询一共有3个过滤过程,分别是ON,WHERE,HAVING。ON是最先执行的过滤过程。根据上一个步骤产生的虚拟表VT1,应用ON进行过滤
SELECT c.customer_id AS c_customer_id, c.city, o.order_id, o.customer_id AS o_customer_id FROM customers c JOIN orders o ON c.customer_id = o.customer_id

3
添加外部行
这一步只有在连接类型为OUTER JOIN时才发生,如LEFT OUTER JOIN,RIGHT OUTER JOIN,FULL OUTER JOIN。虽然在大多数时候我们可以省略OUTER关键词,但OUTER代表的就是外部行。LEFT OUTER JOIN把左表记为保留表,RIGHT OUTER JOIN把右表记为保留表,FULL OUTER JOIN把左右表都记为保留表。添加外部行的工作就是在VT2表的基础上添加保留表中被过滤条件过滤掉的数据,非保留表的数据被赋予NULL值,最后生成虚拟表VT3
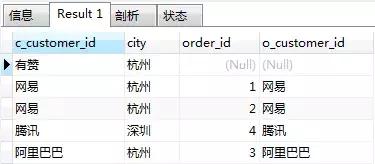
在这个例子中,保留表时customers,设置保留表的过程如下:
customers c LEFT JOIN orders o
顾客有赞在VT2表中由于没有订单而被过滤,因此有赞作为外部行被添加到虚拟表VT2中,将非保留表中的数据赋值为NULL
SELECT c.customer_id AS c_customer_id, c.city, o.order_id, o.customer_id AS o_customer_id FROM customers c LEFT JOIN orders o ON c.customer_id = o.customer_id
如果需要连接表的数量大于2,则对虚拟表VT3重做步骤1-步骤3,最后产生的虚拟表作为下一个步骤的输出
4
应用WEHRE过滤器
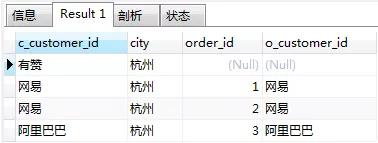
对上一个步骤产生的虚拟表VT3进行WHERE条件过滤,只有符合<where_condition>的记录才会输出到虚拟表VT4中。
在当前应用WHERE过滤器时,有两种过滤是不被允许的
- 由于数据还没有分组,因此现在还不能再WHERE过滤器中使用where_condition=MIN(col)这类对统计的过滤
- 由于没有进行列的选取操作,因此在SELECT中使用列的别名也是不被允许的,如SELECT city as c FROM t WHERE c = “shanghai”是不允许出现的
SELECT c.customer_id AS c_customer_id, c.city, o.order_id, o.customer_id AS o_customer_id FROM customers c LEFT JOIN orders o ON c.customer_id = o.customer_id WHERE c.city = "杭州"
5
分组
在本步骤中根据指定的列对上个步骤中产生的虚拟表进行分组,最后得到虚拟表VT5

6
应用ROLLUP或CUBE
如果指定了ROLLUP选项,那么将创建一个额外的记录添加到虚拟表VT5的最后,并生成虚拟表VT6。因为我们的查询并未用到ROLLUP,所以将跳过本步骤。
对于CUBE选项,MySQL数据库虽然支持该关键字的解析,但是并未实现该功能。
7
应用HAVING过滤器
这是最后一个条件过滤器了,之前已经分别应用了ON和WHERE过滤器。在该步骤中对于上一步产生的虚拟表应用HAVING过滤器,HAVING是对分组条件进行过滤的筛序器。
SELECT c.customer_id AS c_customer_id, c.city, o.order_id, o.customer_id AS o_customer_id FROM customers c LEFT JOIN orders o ON c.customer_id = o.customer_id WHERE c.city = "杭州" GROUP BY c.customer_id HAVING count( o.customer_id ) < 2
网易的订单数是2个,所以被过滤掉了

8
处理SELECT列表
虽然SELECT是查询中最先被指定的部分,但是直到步骤8时才真正进行处理。在这一步中,将SELECT中指定的列从上一步产生的虚拟表中选出
SELECT c.customer_id, count( o.order_id ) AS total_orders FROM customers AS c LEFT JOIN orders AS o ON c.customer_id = o.customer_id WHERE c.city = "杭州" GROUP BY c.customer_id HAVING count( o.order_id ) < 2

9
应用DISTINCT子句
如果在查询中指定了DISTINCT子句,则会创建一张内存临时表(如果内存中存放不下就放到磁盘上)。这张内存临时表的表结构和上一步产生的虚拟表一样,不同的是对进行DISTINCT操作的列增加了一个唯一索引,以此来去除重复数据。
由于在这个SQL查询中未指定DISTINCT,因此跳过本步骤。另外对使用了GROUP BY的查询,再使用DISTINCT是多余的,因为已经进行分组,不会移除任何行
10
应用ORDER BY子句
根据ORDER BY子句中指定的列对上一个输出的虚拟表进行排列,返回新的虚拟表。
SELECT c.customer_id, count( o.order_id ) AS total_orders FROM customers AS c LEFT JOIN orders AS o ON c.customer_id = o.customer_id WHERE c.city = "杭州" GROUP BY c.customer_id HAVING count( o.order_id ) < 2 ORDER BY total_orders DESC;

11
LIMIT子句
在该步骤中应用LIMIT子句,从上一步骤的虚拟表选出从指定位置开始的指定行数据。对于没有应用ORDER BY的LIMIT子句,结果同样可能是无序的,因此LIMIT子句通常和ORDER BY子句一起使用
Java识堂
一个有干货的公众号


