缓存 在我们的日常开发中具有极高的使用频率,当一个系统遇到性能瓶颈的时候往往会考虑使用缓存来解决问题。
对于那些访问频率高、更新频率低的数据,我们可以考虑把查询结果保存起来,这样下次查询的时候直接根据key到缓存中查询数据,从而极大的降低数据库的访问压力、提高数据访问速度。
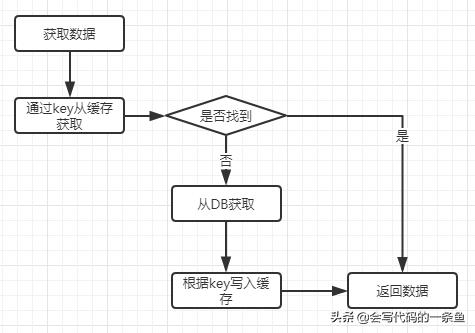
数据访问流程:
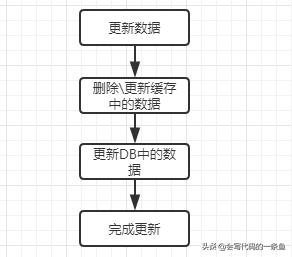
数据更新流程:
我们可以把缓存分为两大类: 分布式缓存 和本地缓存。今天我们就来深入分析一下本地缓存的特点和用法。
本地缓存使用场景
- 对于访问频率高、更新频率低。
- 本地缓存大部分情况是存放在内存中,数据量不能太大,防止内存使用率过高。
- 在多服务器实例的情况下,数据更新后比较难失效缓存里的数据,缓存的数据应该要允许短时间的数据不一致。
本地缓存的优劣
优势:相对于分布式缓存,本地缓存的优点是非常明显的。它无需网络请求,全部操作都在内存中完成,极大的提高了数据请求的速度。同时由于没有外部请求,也不易受到外部环境的影响,比如网络不稳定、DB服务器负责过高等。
劣势:所有的数据都是缓存在 服务器内存 中的,那么它的劣势也是很明显的。缓存数量控制不好,可能会导致内存不够用;缓存的数据发生了变更的化,想要同时把所有服务器上的缓存数据失效是比较困难的,会加大系统复杂度。
本地缓存的设计特点
对于本地缓存而言,最为关键的就是以下两点:
- 过期删除策略
- 缓存淘汰策略
过期策略一般有以下两种个:
- 定期删除:单独的线程对数据进行过期检查,然后删除过期的数据。特点是数据过期删除是独立进行的,比较符合单一原则。
- 惰性删除:当数据被查询时再判断是否过期。特点是实现上比较简单,过期的数据有可能会保存较长的时间。
淘汰策略也可以分为以下几种:
- FIFO(First In First out): 先进先出。当资源不足时, 干掉那些先出生的老人, 简单粗暴, 可能造成经常使用的缓存被淘汰。这种方式往往只需要设置一个缓存条目最大值即可,实现起来比较简单。
- LRU (Least recently used): 最近最少使用,LRU机制要求put缓存时,将数据放在 链表 的头部, get缓存时将数据移到链表的头部, 保证了最近使用的数据都在链表的头部区域, 最近最少使用的数据都在链表的尾部, 这样需要淘汰缓存时, 直接移除链表尾部的数据即可。
- LFU(Least frequently used): 最少频率使用
实现一个简单的本地缓存类
本地缓存实现起来其实是比较简单的,我们可以很轻易的实现一个。下面我们就基于LinkedHashMap来实现一个本地缓存:

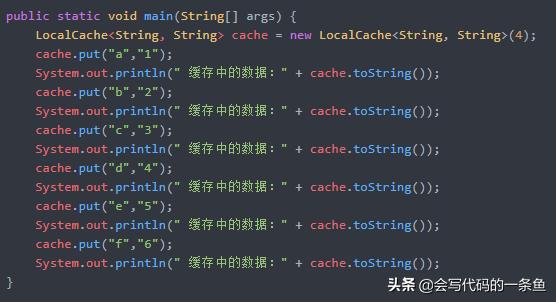
测试代码:
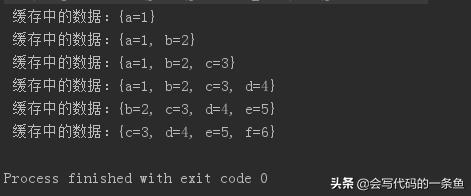
输出结果:
使用 Google 的Guava中的本地缓存
自己虽然能够很快实现一个本地缓存,但是往往功能比较简单,性能上也不够优秀。大部分情况下我们都应该使用业界优秀的开源软件来完成。其中Google Guava就能够提供比较好的本地缓存功能(据说Caffeine更加优秀,不过我还没有时间研究,以后有机会再介绍)。
Guava Cache功能非常的完善,支持多种淘汰策略,我们可以根据自己的实际需求来选择使用,感兴趣的朋友可以研究一下它的用法和实现原理。
本地缓存数据一致性
使用本地缓存必定会遇到数据一致性的问题,这是由于在实际使用过程中,任何数据都是有可能变动的,只要数据有变动就会有一致性的问题。
对于本地缓存中的数据,当数据变动的时候,我们有两种选择:
- 不做任何操作,让缓存中的数据自然失效后重新获取。这种方式是最简单的,很多时候我们都是这么干的。但是他有一个问题,在数据变更到各个服务器实例中的缓存都失效了的这段时间里,数据是不一致的。我们要么容忍这种数据不一致,要么就缩短失效时间,从而减少不一致的时间。很多时候我们选择容忍这个数据不一致。
- 另外一种做法是,当数据发送变更的时候,通知及时通知所有服务器实例进行缓存失效或者更新。这种方式能够极大的解决数据一致性问题(一般毫秒级别内就能完成数据更新),但是同时也提高了系统复杂度,只有在不能容忍长时间数据不一致的情况下使用。数据变更后的消息通知,我们可以通过消息中间件、 zookeeper 等能够及时广播信息到所有服务器的系统来完成。


