本文预计阅读时间10分钟,分为前言、填坑两部分,主要包含 缓存 的基本使用到高级应用场景的介绍
一、前言
在处理高并发请求时,缓存几乎是无往不利的利器。举个例子,在下图中有两个请求:请求1命中缓存,总耗时= 网络耗时t1 + 缓存数据获取t2,请求2总耗时 = 网络耗时 t1 + 缓存数据获取t3。t3-t2就是缓存带来的性能提升。实际业务场景中,查询一次DB需要耗时20ms,读取一次缓存耗时1ms,那么就节省了19ms。
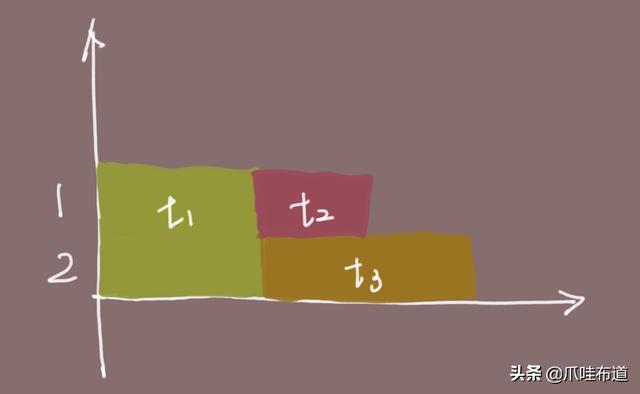
从实际的场景出发,可以将缓存的使用分为两大类:
1. 使用更快的存储介质替代慢的,减少数据访问时间,比如内存替代磁盘
2. 缓存计算结果,节省计算资源,比如缓存DB查询结果
对于第一类使用方式,可能不是特别直观,我们看下数据

从上图可以看到,最快的一级缓存到最慢的网络读写之间差了 3亿倍 。
第二类比较好理解,从开篇举的例子就能看出,计算消耗的资源越多,缓存的效果就越明显。
通常这两类使用方式结合,能达到优化响应,节省计算资源,降低后端负载的目的。但是有利就有弊,相对于他的巨大好处,带来的弊端也是巨大的,甚至某些场景并不适合缓存。
1. 数据不一致性。无论多么好的设计,缓存数据与真实数据源一定存在着一定时间窗口,这段时间内数据是不一致的
2. 代码维护成本。有缓存后,代码就会在原数据源基础上加入缓存的相关代码,例如某数据存储在DB中,通过sql进行查询,现在需要同步设计一套缓存的存储、同步、使用的代码。必然增加代码工作量和系统架构的复杂度
二、填坑
在缓存带来的高收益面前,也会有很多的坑,主要下面几类
2.1 缓存一致性
当数据时效性要求很高时,需要保证缓存与数据源的数据保持一致,不能存在差异。因为数据存在两个地方,理论上不可能达到100%的一致,只能尽可能的较少不一致的时间窗口。这依赖于缓存的更新策略。一般有两大类:主动更新和被动更新。
2.1.1 主动更新
- 监听数据变更事件,一旦发生变更,则主动更新缓存
- 定时刷新缓存数据
2.1.2 被动更新
- 设置缓存过期时间,查询缓存时发现过期,则重新获取数据,并且写入到缓存中
对于一致性解决方案,目前没有统一标准,通过上面的策略调整,可以尽可能的缩短不一致的窗口期,达到最终一致,在业务可接受范围时间内的不一致性,都是认为可接受的。
2.2 缓存击穿
这里要区分一下击穿与雪崩的差别,击穿指一个“热点”Key失效导致大量相同请求打到后端,雪崩则是大量的Key同时失效。明确概念,解决起来就简单多了。
2.2.1 相同请求合并
设置互斥锁,保证缓存过期之后,只有一个请求查询DB,更新缓存,其他请求则不断轮训DB,等待处理。 伪代码 如下:
public Object get(String key) {
Object value = getFromCache(key);
if (value != null) {
return value;
}
if (tryLock()) {
value = queryAndUpdateCache(key);
releaseLock();
} else {
sleep(10L);
value = get(key);
}
return value;
} 2.2.2 提前触发更新
在Value内部设置一个过期时间timeout1,缓存的时间过期时间为timeout2,在获取Key的时候,检查一下timeout1,已经过期,则触发缓存更新。
2.2.3 永不过期
这里的永不过期,是指物理上永不过期,但是设置一个逻辑过期时间。该方案相对“提前触发更新”,会占据更多的存储空间,但是不会存在缓存失效问题。
2.3 缓存穿透
缓存穿透是指查询一个一定不存在的数据时,由于缓存肯定不会命中,每次请求都会由后端处理,实际又不会更新。针对这种情况,一般有两种方案
2.3.1 缓存空值
将value为空的也缓存起来,在下次请求过来之后,就可以直接从缓存中获取。这里要注意一个点, 如何判定一定不存在!!
2.3.2 布隆过滤
如图所示,在访问所有资源(cache, DB)之前,将存在的key用 布隆过滤器 提前保存起来,做第一层拦截。算法的简单图解如下

但是布隆过滤需要一开始就初始化好全量数据,在实际运用场景中,面对TB级的数据,预热阶段可能就需要耗费特别长时间。
2.4 缓存雪崩
前面讲过,雪崩是指大量请求透过缓存直接打到后端,对DB/RPC/HTTP后端服务造巨大压力,甚至瘫痪。
出现对情况多种多样,大量Key同时过期、Cache服务 宕机 或者不响应等等,都可能导致。这里就需要针对情况来做处理。
2.4.1 Cache服务可用性
Redis/Memcache都是支持集群部署的,并且通过一些容灾策略比如一致性hash、哨兵机制、数据备份、主从复制来保证某个cache节点不可用的情况下,可以快速切换到可用节点。
2.4.2 提前预防
为了避免对DB/RPC/HTTP后端服务造巨大压力,我们还要预防,一般通过限流策略,结合熔断机制,在超出系统负荷的时候,拒绝掉部分流量,保证系统的整体可用
2.4.3 Key过期时间优化
过期时间尽量设置的较为离散,比如对不同key设置不同长度的过期时间,某些key设置为1分钟,某些设置为10min
关于作者
某团基础架构部搬砖工,专注于高并发、高可靠系统研发。本公号主要素材来自于个人日常工作、思考,偶尔也有前沿新闻、国外译文。关注我就对了= =
往期文章:


