在日常开发中,我们一般会使用 关系型数据库 比如 MySQL 作为数据存储和数据读写的工具,为了扛住读写流量和提高吞吐量,可以采用数据分片 (分库分表) 和读写分离 (一主多从) 的架构,但是随着数据的积累和流量的激增,仅仅靠持久层数据库已经扛不住更高的并发流量,且读写性能也会受限于磁盘 IO;内存操作的速度是远远大于磁盘操作的,大部分业务通常是读多写少,针对这些数据,通常在系统中加入缓存层来提高响应速度,同时缓存在高并发场景下对数据库也有一定的保护作用。
一. 缓存架构该选择一致性还是可用性?
当加入了缓存后,数据存在于两个空间,所以就会出现新的挑战:数据一致性;根据 CAP 理论, 分布式系统 在 分区容错性、可用性 和 一致性 上无法兼得,而分区容错性是分布式系统的基础无法避免,故我们只能在 可用性 和 一致性 上进行取舍。
选择一致性还是可用性?
因为引入了缓存层,修改时就需要同时维护两个组件:「缓存」与「数据库」,由于是两个不同的组件,不管如何操作二者之间总会存在 不一致的时间窗口 ,并且无法保证二者一定 同时成功或同时失败 ,除非引入分布式事务等手段去维护强一致,当然性能也会大幅下降。而在常规业务上是允许数据存在一段时间的不一致,所以我们会更加注重系统的可用性,通常我们选择 可用性 ,保证最终一致性即可 (想要强一致就不建议使用缓存) 。
缓存的一致性主要分为两种, 「持久层数据库(DB)和缓存间的一致性」 与 「同级缓存间的一致性」 。 「同级缓存间的一致性」 比较简单 (消息广播删除) ,本文讨论的是「数据库」和「缓存」的一致性。
二. 旁路缓存模式
数据库与缓存的一致性问题的又叫作双写一致性问题 (这里我们暂时讨论 分布式缓存 ,比如 redis ) ,在业界已经有几种通用的 缓存 设计模式。
Cache- Aside (旁路缓存模式) 是应用最广泛的缓存一致性模式,实现起来也非常简单,读写工作流程如下:
- 读: 先读 缓存 ,如果缓存存在直接返回;如果不存在去读 数据库 ,并将数据写回缓存,最后再将数据返回;
- 写: 先更新 「数据库」 ,然后失效 「缓存」 。
读的这个流程是没有什么疑问的,我们先不看旁路缓存模式写流程,直观来看保证「缓存」和「数据库」的一致性需要同时维护二者,就有以下四种方式:
1. 先更新「缓存」,再更新「数据库」
2. 先更新「数据库」,再更新「缓存」
3. 先失效「缓存」,再更新「数据库」
4. 先更新「数据库」,再失效「缓存」 (旁路缓存模式)
我们先来分析下更新缓存的方式。
先更新「缓存」,再更新「数据库」
这种方式主要有两种情况导致不一致: 更新数据库失败和并发写
更新「数据库」失败导致不一致
当我们更新缓存成功后,更新数据库失败,就会造成缓存和数据库的不一致,如下:
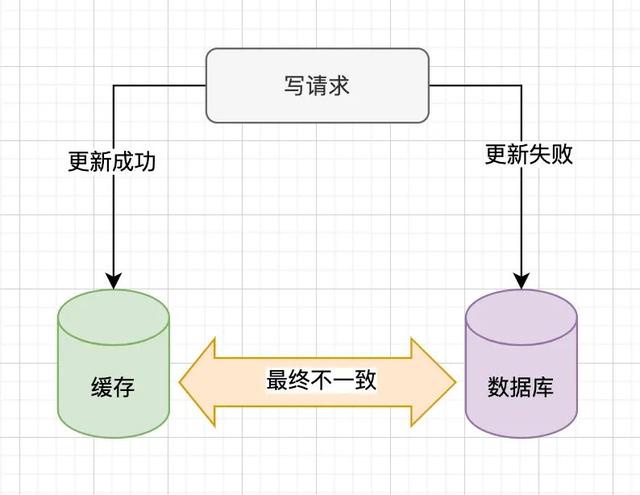
MySQL 可能会因为唯一键冲突、连接被占满或网络异常等问题导致更新失败,而这个时候为了保证一致性就需要对 Redis 也写一套回滚逻辑,比较麻烦。
并发写导致不一致
当在并发写的场景下也会出现不一致的问题,假设我们有两个 线程 去更新同一个数值,线程 A 把数据更新为 1,线程 B 把数据更新为 2,我们期望的结果是以下两种情况之一:
1. 「缓存」里的数据是 1 且「数据库」里的数据也是 1
2. 「缓存」里的数据是 2 且「数据库」里的数据也是 2
我们模拟一下这样的场景:
时刻 | 线程A(写) | 线程B(写) |
T1 | 更新缓存为 1 |
|
T2 |
| 更新缓存为 2 |
T3 |
| 更新数据库为 2 |
T4 | 更新数据库为 1 |
|
最终「缓存」里的数据是 2,「数据库」里的数据是 1,最终不一致。
在实际场景里还是很容易出现上述情况的,因为是并发写,线程 A 更新完缓存后可能因为线程切换、gc等情况导致阻塞,线程B 此时畅通无阻的执行完,后续分配到 CPU 时间片的线程 A 被唤醒后将数据库修改为 1,从而导致数据不一致的问题。
想要解决这个问题可以对上述两步操作加分布式锁,当然又会增加系统复杂度和降低吞吐量,那先更新「数据库」再更新「缓存」呢?
先更新「数据库」再更新「缓存」
这种方式也同样是两种方式导致不一致:更新缓存失败和并发写。
更新缓存失败导致不一致
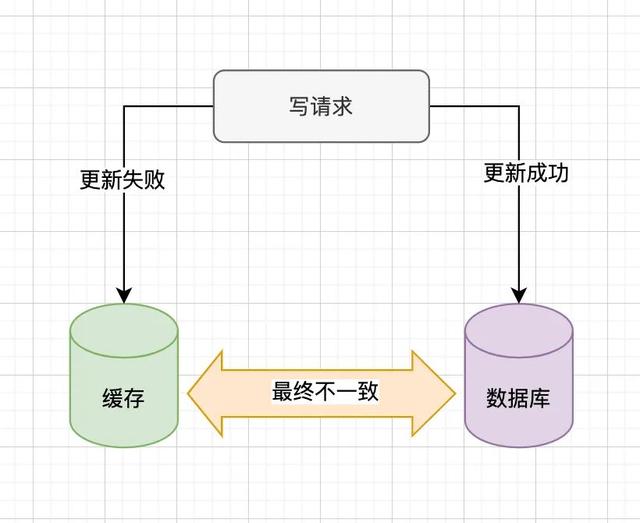
我们更新「数据库」成功后更新「缓存」失败,也会导致数据库和缓存的不一致。
这种情况我们可以借助「数据库」的事务解决, 伪代码 如下:
begin; // 开启事务
boolean success = updateDB(); // 更新数据库
if (!success) return;
success = updateCache(); // 更新缓存
if(!success) return;
commit ; // 提交事务 更新缓存失败可以利用 数据库事务 触发回滚或补偿重试解决。
并发写导致不一致
并发写出现不一致的原因和「先更新缓存再更新数据库」的方式基本一样,还是同样的假设:有两个线程去更新同一个数值,线程 A 把数据更新为 1,线程 B 把数据更新为 2,我们期望的结果是以下两种情况之一:
1. 「数据库」里的数据是 1 且「缓存」里的数据也是 1;
2. 「数据库」里的数据是 2 且「缓存」里的数据也是 2;
模拟并发写场景:
时刻 | 线程A(写) | 线程B(写) |
T1 | 更新数据库为 1 |
|
T2 |
| 更数据库为 2 |
T3 |
| 更新缓存为 2 |
T4 | 更新缓存为 1 |
|
最终「数据库」里的数据是 2,「缓存」里的数据是 1,数据不一致。
分析完更新缓存的方式,我们再来分析下失效缓存的方式。
先失效「缓存」再更新「数据库」
这种方式就不需要考虑「缓存」操作成功「数据库」操作失败的情况了,因为就算「数据库」更新失败,我们只是删除了缓存,并没有造成数据的不一致;同样并发写的场景,不管多个线程按照什么顺序写最终都是删除缓存,也不会造成不一致问题。
造成不一致的问题出现在并发读写的场景下。
考虑这样的场景:目前 a 在缓存和数据库的值都为 1,现在有线程 A 去将 a 修改为 2,同时有线程 B 去读取 a,我们期望的结果是以下两种情况之一:
1. a 在「缓存」中失效且 a 在「数据库」中的值是 2;
2. a 在「缓存」中的值是 2 且 a 在「数据库」中的值是 2。
我们来模拟下并发读写导致不一致的场景:
时刻 | 线程A(写) | 线程B(读) |
T1 | 删除缓存 a |
|
T2 |
| 先读缓存,发现缓存失效; 从数据库中读取 a 的值为1 |
T3 | 更新数据库 a 的值为 2 |
|
T4 |
| 更新 a 缓存为 1 |
最终 a 在缓存中的值是 1,在数据库中的值是2,数据不一致。
我们看到当读请求 (读数据库) 发生在 写请求的删除缓存之后 、 更新数据库之前 ,就会将脏数据写入缓存,最终导致缓存和数据库不一致。
针对这个问题,业界有个叫做 “延时双删” 的策略,就是在更新完数据库后,延迟一段时间再删除缓存一次,将上述的脏缓存失效掉;而为了这个删除的有效性,通常延迟的时间需要大于业务中读请求的耗时。在代码中可以通过 线程 sleep 或 延迟队列 异步删除实现。但是由于运行环境的不确定性,这个延迟的时间也很难确定。并且由于在这个延迟的时间内「数据库」和「缓存」还是不一致的,所以同时还需考虑 业务对数据不一致的容忍度 。
先更新「数据库」再先失效「缓存」
这种方式在业界被称作 旁路缓存模式 ,并发写不会出现不一致的问题,但 并发读写 也会出现不一致的问题,但是 条件非常苛刻 。
我们来模拟一下该场景:同样目前 a 数据库的值都 1 且在缓存中失效,现在有线程 A 去将 a 修改为 2,同时有线程 B 去读取 a,我们期望的结果是以下两种情况之一:
1. a 在「缓存」中失效且 a 在「数据库」中的值是 2;
2. a 在「缓存」中的值是 2 且 a 在「数据库」中的值是 2。
时刻 | 线程A(写) | 线程B(读) |
T1 |
| 先读缓存,发现缓存失效; 从数据库中读取 a 的值为 1 |
T2 | 更新数据库 a 的值为 2 |
|
T3 | 删除缓存 a |
|
T4 |
| 更新 a 缓存为 1 |
最终数据库中 a 的值为 2,缓存中 a 的值为 1,数据不一致。
在缓存失效的前提下:线程 B 先读缓存,发现缓存失效,从数据库中读取 a 的值为 1,假设这时发生线程切换或者所在实例发生 STW 等导致阻塞,这时线程 A 将数据库中 a 的值修改为 2 并删除缓存,线程 B 此时被唤醒更新 a 缓存为 1,最终造成数据库和缓存的不一致。
其实出现上述情况需要满足以下两个条件:
1. 并发读写之前缓存失效;
2. 写请求发生在读请求的「数据库读取操作」之前、「更新缓存」之后。
分析完这四种方式我们来小结一下,在读多写少的场景下,旁路缓存模式 (先更新数据库再失效缓存) 大部分情况下可以保证一致性;但是当读写相当时 (读写都很多) 时,旁路缓存模式会导致缓存频繁失效,大量读请求就会打到数据库,甚至导致数据库不可用,这种读写相当的场景就可以采用更新缓存的方式,当然还是需要具体场景具体分析。
三. 如何保证最终一致性?
当发生极端情况如何保证最终一致性?
过期时间
当系统向 Redis 发出删除命令时,由于网络异常、 Redis 重启导致删除失败或上述极端条件下发生数据不一致问题时,我们根据业务对数据不一致的容忍程度对缓存设置过期时间,过期时间到后缓存自动失效,比如我们设置过期时间 60 s,如果发生极端情况,数据不一致只在这 60s 的时间窗口内,保证数据库和缓存的最终一致性。
补偿机制
针对缓存删除失败,在程序中是可以拿到执行结果的,我们可以对删除失败的缓存进行异步重试,比如使用消息队列,再限制下重试次数,当超过重试次数还失败就进行告警 (重试多次还失败的情况基本可以忽略,除非 Redis 挂了) 。
伪代码如下:
public void delKey(String key, int times) {
boolean success = redisClient.del(key); // 删除缓存
if(sucess) return;
if(times >= 3) {
messageClient. alert (key); // 大于重试 阈值 告警
return;
}
kafka Client.produce(key, times + 1); // 发送至消息队列重试
} 使用的消息队列来重试还是对代码有一定的入侵性。
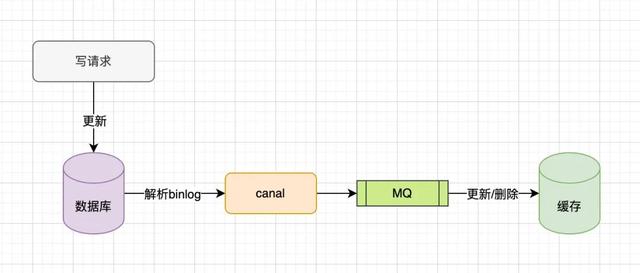
CDC 同步
在业界有种优雅的方式,就是 基于数据库的变更日志去删除缓存 ,在代码中变更数据时只需要修改数据即可,无需操作缓存;拿 MySQL 举例,当 MySQL 数据库有变更时,会记录一条 binlog 日志,我们可以订阅 binlog 日志来操作缓存。
binlog 解析组件可以使用 阿里巴巴 开源的 canal 。大概原理就是 canal 模拟 MySQL slave 的交互协议,伪装成从节点,接收 MySQL 主节点推送的 binlog 变更日志,对 binlog 日志进行解析并上报到消息队列,消费端消费消息对缓存进行操作。
四. 其他缓存策略
Read-Through
Read-Through 被称作 读穿透模式 ,读穿透模式就是将旁路缓存模式封装成抽象缓存层,读取数据只需从抽象缓存中读,无需关心内部逻辑,代码实现更加简洁,比如在 Java 中我们可以这么实现读穿透模式:
public <T> T getObjectFromString(Class<T> clazz,
String key,
Callable<T> selector,
long expireSeconds) throws Exception {
T bean = null;
String value = redisClient.get(key);
if (value != null) {
if (String.class == clazz) return (T) value;
bean = JSON.parseObject(value, clazz);
return bean;
}
bean = selector.call(); // 当缓存为空时从DB读取
String cacheVal;
if (bean == null) return bean;
else if (bean instanceof String) cacheVal = bean.toString();
else cacheVal = JSON.toJSONString(bean);
redisClient.setEx(key, cacheVal, expireSeconds); // 更新缓存
return bean;
} 其实就是将旁路缓存的逻辑抽象出来,查询数据库逻辑以 Callable 函数接口传入方法内,代码实现更简洁;同时我们也可以将解决缓存雪崩 (过期时间+随机时间) 、缓存穿透 (数据库没有就设置空值到缓存) 等逻辑加在里面。
Write-Through
Write-Trough 被称作 直写模式 ,也是将维护缓存与数据库的一致性逻辑封装成抽象缓存层,代码中只需访问抽象层。直写模式封装的是:先更新数据库再更新缓存的策略 (需要加锁保证一致性) ;该模式一般应用于存储本身而非业务,比如 Redis 和 MySQL 的持久化策略。
Write-Behind
Write-Behind 被称作 异步回写模式 ,Write-Behind 在处理写请求时,只更新缓存而不更新数据库,后续通过定时任务异步批量执行写入数据库。如果缓存 宕机 会导致数据丢失,需要做好缓存的高可用和持久化;该模式适合写多的场景,比如电商的秒杀库存扣减。
五. 总结
本文介绍了一些常用的缓存策略,并分析了会出现不一致的极端情况以及解决方案;当我们引入了缓存,就代表放弃了强一致,高性能和强一致性就像鱼和熊掌,不可兼得;我们只有通过一些手段来保证最终一致性,例如延迟双删、异步重试、CDC同步等。这些方案都提升了系统复杂度,需综合考虑业务的容忍度,方案的复杂度等。


