根据 MapReduce 运行全流程,对每个环节进行调优
MapReduce 运行流程图
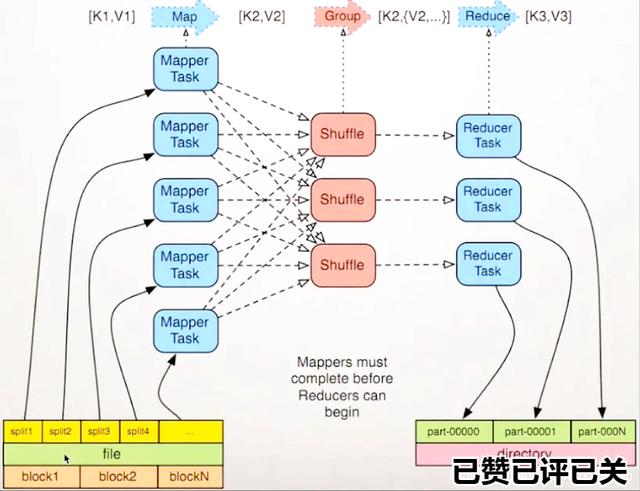
MapReduce 运行流程关键环节及相关参数
- 文件输入:对文件进行切片,可设置切片大小,可设置是否合并小文件
- Map:Map 数量 = 输入文件切片数量
- Map 文件输出:是否合并设置,合并为多大,什么情况下会合并
- Reduce: hive 自动计算 reduce 个数 或者 显式指定 reduce 个数
- Reduce 文件输出:是否合并,合并为多大,什么情况下合并
- 最终文件压缩:job 之间 文件输出是否压缩, Hive Sql 执行完毕的最终结果是否合并。
文件输入阶段
切片大小设置
map reduce.input.fileinputformat. Split .minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue 默认值Long.MAXValue因此,默认情况下,切片大小=blocksize
- Split 切片:是 MapReduce 的最小计算单元,计算公式:computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))。因此默认与 HDFS 的 block 保持一致。
- maxsize(切片最大值): 参数如果调到比 blocksize 小,则会让切片变小,而且就等于配置的这个参数的值。
- minsize(切片最小值): 参数调的比 blockSize 大,则可以让切片变得比 blocksize 还大。
- 注意,==MapReduce 的切片是基于文件进行切片,不是切分数据集整体,也不是切分 block==。
示例:
--设置maxsize大小为10M,也就是说一个block的大小为10M
set mapreduce.input.fileinputformat. split .maxsize=10485760; 小文件合并
(Hive 默认就是合并的)
注意,==MapReduce 的切片是基于文件进行切片,不是切分数据集整体,也不是切分 block==。所以,如果有好多小文件,且不开启合并小文件的功能,一个小文件就会对应一个 MapTask,这是非常不划算的。(具体参考本文档上面 MapReduce 框架原理。非常好的博文 )
# hive 的默认值就是这个,不用特别设置
set hive.input.format= org. apache . Hadoop .hive.ql.io.CombineHiveInputFormat;
Map
Map 个数:输入文件切片的个数就是 Map 个数,跟 输入文件集合的 文件个数、文件大小有关系。
如何控制:通过设置 split(切片) 大小、合并小文件,控制 Map 的个数。
Map 不是越多越好:大量小文件,如果每个小文件一个 Map,是集群资源的浪费。
Map 也不是越少越好:如果一个 127 M 文件,但是只有 2 个字段,一共有几百万行、几千万行数据,且数据处理逻辑还挺复杂,那么一个 Map 明显就有点少了。
Map 输出文件
合并 map 阶段和 reduce 阶段输出的小文件
我们知道文件数目小,容易在文件存储端造成瓶颈,给 HDFS 带来压力,影响处理效率。对此,可以通过合并 Map 和 Reduce 的结果文件来消除这样的影响。
用于设置合并属性的参数有:
# 是否合并Map输出文件,默认值为真
hive. merge .mapfiles=true
# 是否合并Reduce 端输出文件,默认值为假:
hive.merge.mapredfiles=false
# 合并文件的大小,默认值为 256000000:
hive.merge.size.per.task=256*1000*1000()
更多参数:
作用:当 map 端 或者 reduce 端 输出的平均文件大小小于我们设定的这个值时,就开启合并,将文件合并成一个大文件。
如果 map 端文件合并开关开启了,就合并,否则不合并
如果 reduce 端文件合并开关开启了,就合并,否则不合并
<property>
<name>hive.merge.smallfiles.avgsize</name>
<value>16000000</value>
<description>
When the average output file size of a job is less than this number , Hive will start an additional
map-reduce job to merge the output files into bigger files. This is only done for map-only jobs if hive.merge.mapfiles is true, and for map-reduce jobs if hive.merge.mapredfiles is true.
</description>
</property> Reduce
根据配置自动计算
1)每个 Reduce 处理的数据量默认是 256MB
- 当数据量特别大,并且集群资源足够的时候,可以将默认值适当调小,让多个 reduce task 并行处理,但是要注意,如果 有数据倾斜,或者数据只会发送到两个 reduce 上面,开启再多的 reduce 也没有用,具体情况参考下面的 join 优化、group by 优化。reduce 个数也不是越多越好,如果一个 reduce 处理的数据量太小,那么开启、释放 reduce task 的时间就会占用很大一部分,得不偿失;
- 当数据量特别大,但是集群资源并没有那么多的时候,reduce 的个数设置的太多,甚至超过了集群总体线程数,那么部分 task 就会阻塞等待先申请到资源的 task 运行完毕才能申请到资源,这样的话,任务不仅不会更快执行完,反而会不停地开启、释放 reduce task ,也就是不停地开启、释放 JVM,造成额外的开销,这个时候为了避免这种情况,反而要把默认值适当调大,让一个 reduce 一次性处理比较大的数据集。
set hive.exec.reducers.bytes.per.reducer=256000000;
- 每个任务最大的 reduce 数,默认为 1009
- set hive.exec.reducers.max=1009;
- 计算 reducer 数的公式
- N=min(参数 2,总输入数据量/参数 1)
直接指定
# 默认值是 -1 ,就是说 默认是系统自动计算 reduce 个数
hive> set mapreduce.job.reduces;
mapreduce.job.reduces=-1
# 设置每一个job中reduce个数
set mapreduce.job.reduces=3;
注意
如果 reduce 太少:如果数据量很大,会导致这个 reduce 异常的慢,从而导致这个任务不能结束,也有可能会 OOM。
如果 reduce 太多: 过多启动和初始化,也会消耗时间和资源。且产生的小文件太多,合并起来代价太高, namenode 的内存占用也会增大。
Reduce 输出文件
见 Map 输出文件,道理是一样的
输出文件压缩
注意 :这里的压缩,不包含 Map 输出文件的压缩,只包含 reduce 输出文件的压缩,有如下两种情况:
- 整个 HiveSql 任务执行完了,最终的结果写入到 HDFS 上的时候,要不要压缩
- 某个 HiveSql 可能有多个 mapreduce 任务串行,那么 每一个 mapreduce 任务完成后,这个任务输出的 临时中间结果文件 要不要压缩。
Hive 表中间数据压缩。
#设置为true为激活中间数据压缩功能,默认是false,没有开启。
# This controls whether intermediate files produced by Hive between multiple map-reduce jobs are compressed.
set hive.exec. compress .intermediate=true;
# 设置中间数据的压缩算法。
# 这个参数有问题吧?这难道不是 map 输出的压缩格式吗?
set mapred.map.output.compression.codec= org.apache.hadoop.io.compress. Snappy Codec; Hive 表最终输出结果压缩
# This controls whether the final outputs of a query (to a local/HDFS file or a Hive table) is compressed.
set hive.exec.compress.output=true;
set mapred.output.compression.codec= org.apache.hadoop.io.compress.SnappyCodec;
Hive 配置文件中的说明:
<property>
<name>hive.exec.compress.output</name>
<value>false</value>
<description>
This controls whether the final outputs of a query (to a local/HDFS file or a Hive table) is compressed.
The compression codec and other options are determined from hadoop config variables mapred.output.compress*
</description>
</property>
<property>
<name>hive.exec.compress.intermediate</name>
<value>false</value>
<description>
This controls whether intermediate files produced by Hive between multiple map-reduce jobs are compressed.
The compression codec and other options are determined from Hadoop config variables mapred.output.compress*
</description>
</property> join 操作调优
a. Join 原则
- shuffle 之后,在 reduce 阶段,左边的表先加载进内存,所以把小表放在左边不容易 OOM
- 多表 join, 如果 a.id = b.id, b.id=d.id,join 的字段是一致的,只开启一个 Job 任务
- 如果不一致,有几个 join,就是几个 Job 任务
b. MapJoin
/*+ MAPJOIN(pv) / 用法是老版本的,现在 hive 是自动进行 mapjoin 的,无需通过 / + MAPJOIN(pv) */ 告诉解释器 开启 mapjoin 。
--默认为true
set hive.auto.convert.join = true;
--大表小表的 阈值 设置(默认25M以下认为是小表)
set hive.mapjoin.smalltable.filesize=25000000; c. Skew Join
SKEW join 原理:
如果某个 Key 产生了数据倾斜,则 这个 key 暂时不进行运算,存入 HDFS,马上开启另外一个 Job 专门处理这个 key,用 map Join 的方式进行。

- hive.optimize.skewjoin.compiletime
- 如果建表语句元数据中指定了 skew key,则使用 set hive.optimize.skewjoin.compiletime=true 开启 skew join。
- 可以通过如下建表语句指定 SKEWED key:
- CREATE TABLE list_bucket_single (key STRING, value STRING) SKEWED BY (key) ON (1,5,6) [STORED AS DIRECTORIES];
- hive.optimize.skewjoin
- 该参数为在运行时动态指定数据进行 skewjoin,一般和 hive.skewjoin.key 参数一起使用
- set hive.optimize.skewjoin=true; set hive.skewjoin.key=100000;
- 以上参数表示当记录条数超过 100000 时采用 skew join 操作
- 区别
- hive.optimize.skewjoin.compiletime 和 hive.optimize.skewjoin 区别为前者为编译时参数,后者为运行时参数。前者在生成执行计划时根据元数据生成 skewjoin,此参数要求倾斜值一定;后者为运行过程中根据数据条数进行 skewjoin 优化。hive.optimize.skewjoin 实际上应该重名为为 hive.optimize.skewjoin.runtime 参数,考虑兼容性没有进行重命名
Group By 操作调优
group by:聚合
- sum,count,max,min 等 UDAF,不怕数据倾斜问题,hadoop 在 map 端的汇总合并优化,使数据倾斜不成问题。
- count(distinct ),在数据量大的情况下,效率较低,如果是多 count(distinct )效率更低,因为 count(distinct)是按 group by 字段分组,按 distinct 字段排序,一般这种分布方式是很倾斜的。举个例子:比如男 uv,女 uv,像淘宝一天 30 亿的 pv,如果按性别分组,分配 2 个 reduce,每个 reduce 处理 15 亿数据。
关于 Group BY,我的总结就是两句话:
- 能 预聚合 的,就进行 预聚合。如:sum, count(1), max(), min()。(avg 不能进行预聚合)
- 不能进行预聚合的,在必要的情况下就开启 负载均衡 ,如:count(distinct)。注意:也不是所有情况下都需要开启这个。注意要满足两个条件。
a Map 端部分聚合(预聚合)
// 用于设定是否在 map 端进行聚合,默认值为真
hive.map.aggr=true
// 用于设定 map 端进行聚合操作的条目数
hive.groupby.mapaggr.checkinterval=100000
// 如果 map 端的聚合率 大于 50%,就自动关闭预聚合功能,这个是在 参考链接3 中有说明,hive 配置文件中有这个配置项
Hive.map.aggr.hash.min.reduction=0.5 hive.groupby.mapaggr.checkinterval:map 端做聚合时,group by 的 key 所允许的数据行数,超过该值则进行分拆,默认是 100000;
b 开启负载均衡
考虑下面情况
select gender, count(distinct id) from user group by gender
这种情况下: gender 是非散列的,只有两个值,因此也就只有两个 reducer; 而 map 却需要把所有的 id 发送到 reduce 端,这个没办法提前进行预聚合。(为什么?要想清楚。以为这是去重操作,某个 id 可能在多个 map 端都由,在 map 端去重,会造成去重不彻底,重复计数。) 这样就会导致两个 reduce 服务要处理的数据量实在是太大了,所以需要开启负载均衡
负载均衡原理
将 sql 变成 两个 MR 程序。
第一个 MR 的 reduce_key 是 gender + id,这样就是散列的,就会开启很多的 reduce,不会存在数据倾斜的情况。在 reduce 端,就进行第一个 reduce 聚合,分别在自己的服务器上计数。
注意:这里要想清楚,为什么第一次 reduce 不会影响最终的结果,不会出现上面说的去重不彻底的问题?因为 gender + id 如果是一样的,肯定发送到了 同一个 reduce 上面,就不会有问题。
注明:女_id1 是 key,1 是 单词计数的那个计数
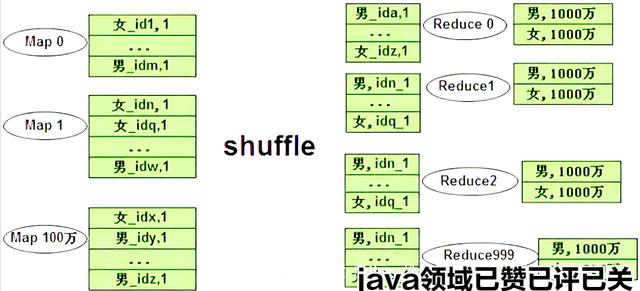
第二个 MR 做最终的聚合。
虽然这个聚合还是只有两个 reduce,但是每个 map 端的数据,只有两条了。

参数
# 这个值默认是 false
set hive.groupby.skewindata = true;
当选项设定为 true 是,生成的查询计划有两 个 MapReduce 任务。在第一个 MapReduce 中,map 的输出结果集合会随机分布到 reduce 中, 每个 reduce 做部分聚合操作,并输出结果。这样处理的结果是,相同的 Group By Key 有可 能分发到不同的 reduce 中,从而达到负载均衡的目的;第二个 MapReduce 任务再根据预处 理的数据结果按照 Group By Key 分布到 reduce 中(这个过程可以保证相同的 Group By Key 分布到同一个 reduce 中),最后完成最终的聚合操作。
看情况开启负载均衡
如下面的例子
select id, count(gender) from user group by id
很明显,reduce_key 此时 为 id, id 本身就是散列的,所以数据本身就很平衡,不用开启。
==负载均衡适用情况==
- groupby_key,也就是 reduce_key,不散列,如 gender
- distinct_key, 非常散列
其它的一些情况,mapJoin 已经足够解决问题了。
SQL 语句优化
严格模式
Hive 提供了一个严格模式,可以防止用户执行那些可能意想不到的不好的影响的查询。
通过设置属性 hive.mapred.mode 值为默认是非严格模式 nonstrict 。开启严格模式需要修改 hive.mapred.mode 值为 strict ,开启严格模式可以禁止 3 种类型的查询。
--设置非严格模式(默认)
set hive.mapred.mode=nonstrict;
--设置严格模式
set hive.mapred.mode=strict;
(1)对于 分区表 ,除非 where 语句中含有分区字段过滤条件来限制范围,否则不允许执行
--设置严格模式下 执行 sql语句 报错; 非严格模式下是可以的
select * from order_partition;
异常信息:Error: Error while compiling statement : FAILED: Semantic Exception [Error 10041]: No partition predicate found for Alias "order_partition" Table "order_partition" (2)对于使用了 order by 语句的查询,要求必须使用 limit 语句
--设置严格模式下 执行sql语句报错; 非严格模式下是可以的
select * from order_partition where month='2019-03' order by order_price;
异常信息:Error: Error while compiling statement: FAILED: SemanticException 1:61 In strict mode, if ORDER BY is specified, LIMIT must also be specified. Error encountered near token 'order_price' (3)限制笛卡尔积的查询
严格模式下,避免出现笛卡尔积的查询
列裁剪
博客文章中写了有参数,默认就是开启的。
我在 hive 的配置文件中没有搜到那个参数,新版本应该是自动进行的。
分区裁剪
同上。
避免使用 笛卡尔积
join 不加 on 条件
GROUP BY 替代 COUNT(DISTINCT) 达到优化效果
计算 uv 的时候,经常会用到 COUNT(DISTINCT),但在数据比较倾斜的时候 COUNT(DISTINCT) 会比较慢。这时可以尝试用 GROUP BY 改写代码计算 uv。
数据量小的时候无所谓,数据量大的情况下,由于 count distinct 操作只能用一个 reduce Task 来完成,这一个 Reduce 需要处理的数据量太大,就会导致整个 Job 很难完成,一般 count distinct 使用先 group by 再 count 的方式替换。
--每个reduce任务处理的数据量 默认256000000(256M)
set hive.exec.reducers.bytes.per.reducer=32123456;
-- 很明显会将所有的 IP 发送到同一个 reduce 上面去,所以存在问题。
select count(distinct ip ) from log_text;
转换成
select count(ip) from (select ip from log_text group by ip) t;
虽然会多用一个Job来完成,但在数据量大的情况下,这个绝对是值得的。
无效 key 问题
方法 1:过滤 + Union
第一种方法:先过滤,再 union,也可以不用 union,随意
SELECT * FROM log a
JOIN bmw_users b
ON a.user_id IS NOT NULL AND a.user_id=b.user_id
UNION All SELECT * FROM log a WHERE a.user_id IS NULL 方法 2:null 转为 随机字符串
第二种方法:将 空值 变成 字符串 + 随机数字,就会将其分散到不同的 reduce 上面。因为空值不参与关联,即使分到不同 的 Reduce 上,也不会影响最终的结果
SELECT * FROM log a LEFT OUTER
JOIN bmw_users b ON
CASE WHEN a.user_id IS NULL THEN CONCAT(‘dp_hive’, RAND ()) ELSE a.user_id END =b.user_id; 实践证明:方案二 比 方案一 效果更好一些。因为只有 1 个 job, IO 也少了。
不同数据类型关联产生的倾斜问题
略过。参考链接 2
使用 union All
Hive 多表 union all 会优化成一个 job。要充分利用 这个 操作。
参考链接 1 中的例子。
Union All 不能优化 嵌套 join count 的如何办
略过。
集群运行角度调优
fetch 抓取
Fetch 抓取是指,==Hive 中对某些情况的查询可以不必使用 MapReduce 计算==
例如:select * from employee;
在这种情况下,Hive 可以简单地读取 employee 对应的存储目录下的文件,然后输出查询结果到控制台
在 hive-default.xml.template 文件中 ==hive.fetch.task.conversion 默认是 more==,老版本 hive 默认是 minimal,该属性修改为 more 以后,在全局查找、字段查找、limit 查找等都不走 mapreduce。
本地模式
在 Hive 客户端测试时,默认情况下是启用 hadoop 的 job 模式,把任务提交到集群中运行,这样会导致计算非常缓慢;
Hive 可以通过本地模式在单台机器上处理任务。对于小数据集,执行时间可以明显被缩短。
案例实操
--开启本地模式,并执行查询语句
set hive.exec.mode.local.auto=true; //开启本地mr
--设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,
--默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
--设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,
--默认为4
set hive.exec.mode.local.auto.input.files.max=5;
--执行查询的sql语句
select * from employee cluster by deptid;
决定是否执行本地模式的条件,都需要满足:
- 总数据量小于给定值,默认 128 M。
- 文件数 小于给定数量,默认 4 。
并行执行
把一个 sql 语句中没有相互依赖的阶段并行去运行。提高集群资源利用率
--开启并行执行
set hive.exec.parallel=true;
--同一个sql允许最大并行度,默认为8。
set hive.exec.parallel.thread.number=16;
具体解释 : (参考链接)
hive.exec.parallel 参数控制在同一个 sql 中的不同的 job 是否可以同时运行,默认为 false.
下面是对于该参数的测试过程:
测试 sql:
select r1.a
from (
select t.a from sunwg_10 t join sunwg_10000000 s on t.a=s.b) r1
join
(select s.b from sunwg_100000 t join sunwg_10 s on t.a=s.b) r2
on (r1.a=r2.b); 1 当参数为 false 的时候,三个 job 是顺序的执行
set hive.exec.parallel=false;
2 但是可以看出来其实两个子查询中的 sql 并无关系, 可以并行的跑。
set hive.exec.parallel=true;
总结: 在资源充足的时候 hive.exec.parallel 会让那些存在并发 job 的 sql 运行得更快,但同时消耗更多的资源 可以评估下 hive.exec.parallel 对我们的刷新任务是否有帮助.
JVM 重用
- JVM 重用是 Hadoop 调优参数的内容,其对 Hive 的性能具有非常大的影响,特别是对于很难避免小文件的场景或 task 特别多的场景,这类场景大多数执行时间都很短。
- JVM 重用可以使得 JVM 实例在同一个 job 中重新使用 N 次。减少进程的启动和销毁时间。
- — 设置jvm重用个数 set mapred.job.reuse.jvm.num.tasks=5;
推测执行
- Hadoop 采用了推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
学习更多JAVA知识与技巧,关注与私信博主(学习)



