《 大数据 和人工智能交流》头条号向广大初学者新增C 、Java 、Python 、Scala、javascript 等目前流行的计算机、大数据编程语言,希望大家以后关注本头条号更多的内容。《大数据和人工智能》头条号方便有基础读者的同时照顾广大没入门的初学者。
和大数据相关文章的链接:
(一)、 hive 概述
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
1、hive实现原理介绍:
(1)Hive将SQL语句转译成MapReduce的作业在Hadoop上执行。
(2)Hive的表其实就是 HDFS 的目录,按表名把文件夹分开。如果是 分区表 ,则分区值是子文件夹。
(3)Hive对数据只是进行查询统计操作,不进行增删、修改操作,相当于hadoop客户端工具。
2、hive 体系结构
hive 体系结构主要分为以下几个部分:
(1)用户接口
用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
(2)元数据存储
hive 将元数据存储在数据库中,如 mysql 、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
(3)解释器、编译器、优化器、执行器
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
(4)Hadoop部分
hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成。
3、hive的数据存储
首先,Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 hive 中的表,只需要在创建表的时候告诉 hive 数据中的列分隔符和行分隔符,hive 就可以解析数据。
其次,hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:表(Table),外部表(External Table),分区( Partition ),桶(Bucket)。hive 中的 Table 和数据库中的 Table 在概念上是类似的,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 pvs,它在 HDFS 中的路径为:/wh/pvs,其中,wh 是在 hive-site.xml 中由 ${hive.metastore. warehouse .dir} 指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
Partition 对应于数据库中的 Partition 列的密集索引,但是 Hive 中 Partition 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个 Bucket 对应一个文件
External Table 指向已经在 HDFS 中存在的数据,可以创建 Partition。它和 Table 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
Table 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
External Table 只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在 LOCATION 后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。当删除一个 External Table 时,仅删除元数据,表中的数据不会真正被删除。
大家先对上述hive先有个总体上大致的认识,通过实战的操作再学习细节。
(二)hive的安装
在Linux环境下,首先必须安装jdk、hadoop,在CentOS和Ubuntu操作系统中,hive的安装步骤大体相同,其步骤如下所示:
(1)修改hive-env.sh
JAVA_HOME=/usr/local/jdk1.7.0_79
HADOOP_HOME=/usr/local/hadoop-2.6.0
HIVE_HOME=/usr/local/hive-1.0.1
(2)修改hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.66:3306/demo?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/usr/local/hive-1.0.1/tmp</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/hive-1.0.1/tmp</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/hive-1.0.1/tmp</value>
</property>
(3)拷贝mysql驱动到$HIVE_HOME/lib目录下
(4)启动Hive
./hive 等价于 ./hive –service cli
(三)、hive的DDL操作
1、hive的数据类型
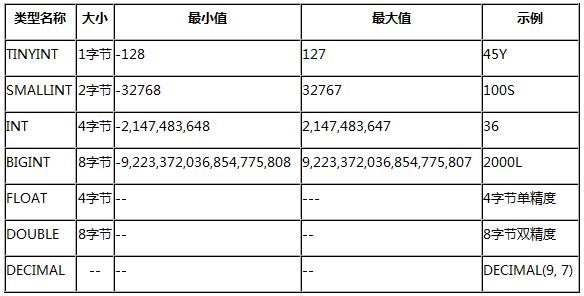
(1)数值型
Hive中的数值类型与Java中的数值类型很相似,区别在于有些类型的名称不一样,可以概括为如下的表格:
(2)字符串类型
字符串常量使用单引号或者双引号表示,Hive使用C语言风格对字符串进行转义。Hive-0.12.0版本引入了VARCHAR类型,VARCHAR类型使用长度指示器(1到65355)创建,长度指示器定义了在字符串中允许的最大字符数量。如果一个字符串值转换为或者被赋予一个varchar值,其长度超过了长度指示器则该字符串值会自动被截断。目前还没有通用的UDF可以直接用于VARCHAR类型,可以使用String UDF代替,VARCHAR将会转换为String再传递给UDF。Hive-0.13.0版本引入了CHAR类型,CHAR类型与VARCHAR类型相似,但拥有固定的长度,也就是如果字符串长度小于指示器的长度则使用空格填充。CHAR类型的最大长度为255。使用VARCHAR、CHAR创建表的例子如下:
CREATE TABLE test(c CHAR(10), vc VARCHAR(30));
(3)日期/时间类型
Hive支持带可选的纳秒级精度的UNIX timestamp。Hive中的timestamp与时区无关,存储为UNIX纪元的偏移量。Hive提供了用于timestamp和时区相互转换的便利UDF:to_utc_timestamp和 from_utc_timestamp。Timestamp类型可以使用所有的日期时间UDF,如month、day、year等。文本文件中的Timestamp必须使用yyyy-mm-dd hh:mm:ss[.f…]的格式,如果使用其它格式,将它们声明为合适的类型(INT、FLOAT、STRING等)并使用UDF将它们转换为Timestamp。Timestamp支持的类型转换为:
整数类型:转换为秒级的UNIX时间戳
浮点数类型:转换为带小数精度的UNIX时间戳
字符串类型:适合java.sql.Timestamp格式”YYYY-MM-DD HH:MM:SS.fffffffff”(9位小数精度)
Hive中DATE类型的值描述了特定的年月日,以YYYY-MM-DD格式表示,例如2014-05-29。DATE类型不包含时间,所表示日期的范围为0000-01-01 to 9999-12-31。DATE类型仅可与DATE、TIMESTAMP、STRING类型相互转化,如下表所示:

(4)复合类型
Hive支持复合数据类型常见如下:
Array:ARRAY<data_type>
Map :MAP<primitive_type, data_type>
Struct: STRUCT<col_name : data_type [COMMENT col_comment], …>
(5)其它类型
Hive支持的其它类型有BOOLEAN和BINARY
2、hive数据库和表的基本操作
在hive提示符也可以操作linux指令,格式为:!linux指令,例如:hive> ! pwd,其它的操作如下:
(1)数据库的操作
查看数据库列表
hive> show databases;
使用db(切换到某个数据库)
hive> use dbName;
创建db
hive> create database dbName;
删除数据库
hive> drop database dbName;
数据库在hdfs上面的位置可以通过配置文件hive-site.xml查询到:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
(2)表的操作
查看表
hive> show tables;
创建表
hive> create table t1(id int);
查看表结构
hive> desc t1;
删除表
hive> drop table t1;
给表增加列
hive> alter table t1 add columns(school string, age int);
(3)hiv数据加载
使用load加载数据:
hive> load data local inpath ‘/usr/local/hello.txt’ into table t1;
使用load加载数据需要指定分隔符。Hive有默认的行列分隔符,行分隔符固定是’n’
列分隔符是八进制的01,是不可见的ASCII,使用CTRL+V和CTRL+A输入即为01
建立表的时候指定行列分隔符如下:
create table t2(
id int,
name string
)
row format delimited
fields terminated by ‘t’
lines terminated by ‘n’;
load data local inpath ‘/usr/local/d1/t1’ into table t2;
直接把数据上传到hdfs中hive对应的目录下面,操作如下:
比如有个t1表为
create table t1(
id int,
)
数据为:
1
2
3
现有文本t2.txt数据如下:
4
5
那么执行指令hdfs dfs -put /usr/local /t2.txt /user/hive/warehouse/db1.db/t1;则数据为:
1
2
3
4
5
hive 可以有像DOS操作系统、Linux操作系统一样以及和oracle的存储过程一样有批处理文件,这样的话将若干条SQL语句写在一个文件里面批量执行极大的提高了效率。
【1】在hive提示符下
假设在/usr/local/d1有个文件批处理a1,内容如下:
create table t2(id int,name string)
row format delimited
fields terminated by ‘t’
lines terminated by ‘n’;
执行hive> source /usr/local/d1/a1便会自动生成表
【2】在Linux提示符下
假设在/usr/local/d1有个文件批处理a1,内容如下:
create table t2(id int,name string)
row format delimited
fields terminated by ‘t’
lines terminated by ‘n’;
执行sh hive -f hive.hql便会自动生成表。也可加 -hiveconf hive.exec.mode.local.auto=true本地模式参数。
(四)、hive的DDL操作
Hive的DDL操作和传统的关系型数据库SQL的语法基本一样,为了说明对hive表的操作,举个实际的案例,如下所示:
示例-1:
在某个大型网上书城经营智能制造、大数据、人工智能相关书籍,改书城保留了进货的日志(文件名:goods.txt),该日志格式的数据模型为:
商品编号 商品名称 商品价格(单位:元)
说明:字段之间使用跳格键(TAB)隔开
样本数据如下:
G_001 大数据采集 33
G_002 大数据存储 56
G_003 大数据分析 99
G_004 大数据展现 28
G_005 大数据测试 26
G_006 大数据运维 29
G_007 大数据安全 89
要求:
1、建立个相应的hive表t_goods,将日志数据goods.txt从本地Linux文件系统导入到t_goods
2、请将下列记录插入到hive的t_goods表
G_008 大数据概述 69
G_009 大数据导论 79
使用加载语句将数据加载到hive表后,我们就可以使用insert语句进行插入操作:
insert into t_goods values(‘G_008’ , ‘大数据概述’ , 69);
insert into t_goods values(‘G_009’ , ‘大数据导论’ , 79);
然后通过select查看数据插入的结果:
select * from t_goods;
如果要求建立个t_goods_bak表,字段和类型与t_goods一样,查询t_goods表价格大于50元的书籍,并将查询结果保存到t_goods_bak,操作如下:
insert into t_goods_bak(goods_id,goods_name,goods_price)
select goods_id,goods_name,goods_price from t_goods
如果要求查询价格在20元到50元之间的书籍:
select * from t_goods where goods_price > 20 and goods_price<50
(五)hive的复合数据类型操作
1、array类型
有个记录学生日志的文件,有3个字段:sid[学号]、sname[姓名]、score[数学、外语、计算机成绩],三个字段之间使用TAB跳格键作为分隔符,成绩之间使用逗号作为分隔符,内容如下:
1 lily1 81,91,92
2 lily2 82,93,94
3 lily3 83,95,96
那么我们使用array类型表示成绩字段,其表设计和分隔符如下所示:
create table t_student(
id int,
name string,
arr array<int>
)
row format delimited
fields terminated by ‘t’
collection items terminated by ‘,’;
那么在查询的时候可使用select arr[0] from t_student 格式检索具体的带索引的数据
2、map数据类型
有个记录学生日志的文件,有3个字段:sid[学号]、sname[姓名]、scores[数学、外语、计算机成绩],三个字段之间使用TAB跳格键作为分隔符,科目之间使用逗号作为分隔符,科目和成绩使用半角冒号分隔符内容如下:
1 lily1 math:91,english:92,bigData:93
2 lily2 math:91,english:92,bigData:93
3 lily3 math:91,english:92,bigData:93
那么我们使用map类型表示成绩字段,其表设计和分隔符如下所示:
create table t_student(
sid int,
sname string,
scores map<string,int>
)
row format delimited
fields terminated by ‘t’
collection items terminated by ‘,’
map keys terminated by ‘:’;
那么在查询的时候可使用select scores[“math”] from t_student 格式检索具体的带索引的数据
3、struct数据类型
有个记录学生日志的文件,有3个字段:sid[学号]、sname[姓名]、sinfo[年龄,性别,地址],三个字段之间使用TAB跳格键作为分隔符,学生信息年龄、性别、地址之间使用逗号分隔符内容如下:
1 lily1 21,F,dongchneg
2 lily2 22,F,xicheng
3 lily3 23,F,haidian
那么我们使用struct类型表示学生信息字段,其表设计和分隔符如下所示:
create table t_student(
sid int,
sname string,
sinfo struct<age:int,sex:string,address:string>
)
row format delimited
fields terminated by ‘t’
collection items terminated by ‘,’;
那么在查询的时候可使用select sinfo.age from t_student检索学生具体信息
hive中的各种默认分隔符
(1)行分隔符:n
(2)列分隔符:01,可以使用ctrl+v加ctrl+a输入
(3)集合元素之间的分隔符:02,可以使用ctrl+v加ctrl+b输入
(4)map的key-value之间的分隔符是:03可以使用ctrl+v加ctrl+c输入
(六)、hive的内部表和外部表
1、内部表
我们在创建表的时候
create table t_student(
id int,
name string,
)
会在hdfs上新建一个t_student目录的数据存放地比如:/user/hive/warehouse/db1.db/t_student,其对应在hive中就有了表记录,在metastore表TBLS中就有表定义,但当我们从hive中删除一张表的定义之后,其表中的数据和在metastore中的定义也就不存在了,这样的表我们叫内部表,以前演示的案例都是内部表
2、外部表
表的定义和数据的生命周期互不约束,数据只是表对HDFS上的某一个目录的引用而已,当删除表定义的时候,其表中的数据依然是存在的,这样的表我们称为外部表
创建外部表的语法:
(1)先创建表再引用数据
create external table tblName(colName colType…);
alter table tblName set location ‘hdfs_absolute_uri’;
(2)边创建表的时候边引用数据
create external table tblName(colName colType…) location ‘hdfs_absolute_uri’;
(3)外部表和内部表之间的转换
内部表转换为外部表:alter table tblName set tblproperties(‘external’=’true’);
外部表转换为内部表:alter table tblName set tblproperties(‘external’=’false’);
例如:在 hdfs的d1/t1文件内容如下:
[root@hadoop d1]# hadoop fs -text /d1/t1
1 hello
2 world
3 hive
我们创建个外部表t1_external来引用/d1/t1
create external table t1_external(
id int,
name string
)
row format delimited
fields terminated by ‘t’
location ‘/d1/’;
然后经过查询是有数据的:
hive> select * from t1_external;
OK
1 hello
2 world
3 hive
Time taken: 0.091 seconds, Fetched: 3 row(s)
但是我们浏览hdfs dfs –ls /user/hive/warehouse/db1.db发现没有数据,而在mysql的metastore,我们可以看见t1_external是外部表
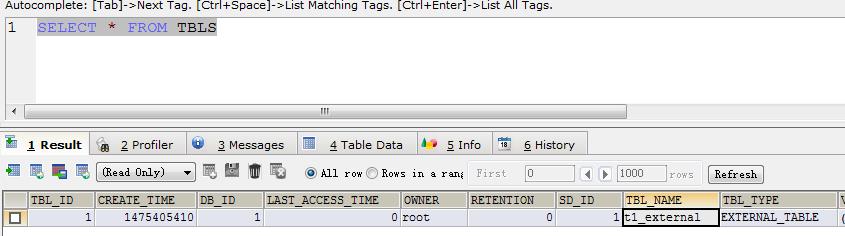
当我们执行drop table t1_external的时候mysql表中元数据metastore中对应的记录被删除了,但是/d1/t1数据还在
3、分区表
现在有北京、哈尔滨、大连、杭州…所有城市的人口数据信息,如果我们查询某个城市的人口信息势必把全表扫描一遍,如果我们按照某个城市的地区查询,那么数据量将大大较少,这时候我们可以将数据按照城市分区
(1)创建简单的分区表
create table t1_people(
p_id int,
p_name string
)
partitioned by (p_zone string)
row format delimited
fields terminated by ‘t’;
创建完毕后查看表结构:
hive> desc t1_people;
OK
p_id int
p_name string
p_zone string
# Partition Information
# col_name data_type comment
p_zone string
Time taken: 0.418 seconds, Fetched: 8 row(s)
将本地linux下/usr/local/d1/t1_people数据导入到表中,数据格式如下:
1 lily1
2 lily2
3 lily3
向分区表t1_people加载数据:
hive> load data local inpath ‘/usr/local/d1/t1_people’ into table t1_people partition(p_zone=’beijing’);
那么在 hdfs中查看分区目录结构:
[root@hadoop d1]# hdfs dfs -ls /user/hive/warehouse/t1_people
Found 1 items
drwxr-xr-x – root supergroup 0 2016-10-02 08:08 /user/hive/warehouse/t1_people/p_zone=beijing
继续查看分区目录结构:
[root@hadoop d1]# hdfs dfs -ls /user/hive/warehouse/t1_people/p_zone=beijing
Found 1 items
-rw-r–r– 1 root supergroup 24 2016-10-02 08:08 /user/hive/warehouse/t1_people/p_zone=beijing/t1_people
那么/user/hive/warehouse/t1_people/p_zone=beijing/t1_people使我们上传的文件(2)手动创建一个分区
在上述的t1_people表中,我们再增加个分区,但这时候使我们手动创建的分区,这时候这个表便会存在2个分区信息,语法格式如下:
alter table t1_people add partition(p_zone=’harbin’);
这时候我们查看分区的信息:
hive> show partitions t1_people;
OK
p_zone=beijing
p_zone=harbin
Time taken: 0.124 seconds, Fetched: 2 row(s)
我们也可以删除个分区,删除分区的时候分区中的数据也将一并删除,其语法格式如下所示:
alter table t1_people drop partition(p_zone=’harbin’);
(3)创建多个分区
在查询人口信息的时候,我们可以先按照省来划分数据,然后再按照城市来划分数据,这时候需要建立2个分区,其语法格式为:
create table t2_people(
p_id int,
p_name string
)
partitioned by (p_province string,p_zone string)
row format delimited
fields terminated by ‘t’
那么我们在加载数据的时候,形式如下:
load data local inpath ‘/usr/local/d1/t2_people’ into table t2_people partition(p_province=’heilongjiang’,p_zone=’haerbin’)
其中本地Linux下/usr/local/d1/t2_people的数据为:
1 lily1
2 lily2
3 lily3
经过上述操作,分区的信息为
hive> show partitions t2_people;
OK
p_province=heilongjiang/p_zone=haerbin
Time taken: 0.14 seconds, Fetched: 1 row(s)
那么相应的HDFS的目录结构如下:
/user/hive/warehouse/t2_people/p_province=heilongjiang/p_zone=haerbin/t2_people
相关操作如下:
[root@hadoop d1]# hdfs dfs -text /user/hive/warehouse/t2_people/p_province=heilongjiang/p_zone=haerbin/t2_people
1 lily1
2 lily2
3 lily3
有了分区之后,我们可以根据分区的条件查询数据,比如查询某个省和城市的人口信息,方法如下:
hive> select * from t2_people where p_province=’heilongjiang’ and p_zone=’haerbin’;
OK
1 lily1 heilongjiang haerbin
2 lily2 heilongjiang haerbin
3 lily3 heilongjiang haerbin
Time taken: 0.223 seconds, Fetched: 3 row(s)
(4)将HDFS中的数据引用到分区表中
我们也可以像外部表一样将将HDFS中的数据引用到分区表,语法形式如下:
alter table t2_people partition(p_province=’heilongjiang’,p_zone=’haerbin’)
set location ‘hdfs://hadoop:9000/d1/t2_data’
上述指令注意分区p_province=’heilongjiang’,p_zone=’haerbin’一定要存在,而且
location ‘hdfs://hadoop:9000/d1/t2_data’必须是绝对路径
4、桶表
在上述分区表中,我们按照城市分区避免了全表扫描的问题,但是有的条件分区里面数据量特别的大,这样在联表查询的时候和一个小表进行连接查询时候依然需要把数据量大的表或者分区扫描一遍,这时候我们可以采用hash散列算法是表的数据均匀分布,以便减少扫描次数
算法思想,假设有个表的数据如下:
1 a
2 b
3 c
4 d
5 e
6 f
7 g
8 h
那么进行取模 data%3之后,将求出0,1,2的hash散列值,那么数据的分布相对均匀,如下所示,实际项目具体取模是多少据具体需求分析而定,在hive中我们使用桶表的概念实现这个思想
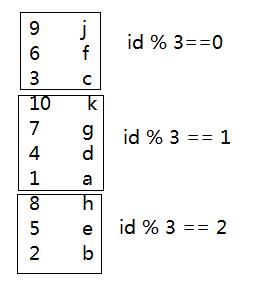
(1)桶表创建的格式
create table tblName_bucket(id int) clustered by (id) into 3 buckets;
其中:
clustered by :按照什么分桶
into x buckets:分成x个桶
(2)加载数据
第一步:先设置开启桶操作
set hive.enforce.bucketing=true;
第二步:使用insert into 指令插入数据
insert into table tblName_bucket select * from tbl_other;
注意:在插入数据之前需要先设置开启桶操作
示例:
【1】创建个桶表
create table tb1_bucket (
id int,
name string
)
clustered by (id) into 3 buckets
【2】加载数据
加载数据的时候需要从别的表导入数据,假设有个表tb1_bucket_data,其表结构
create table tb1_bucket_data(
id int,
name string
)
row format delimited
fields terminated by ‘t’
将linux目录下的数据/usr/local/d2/tb1_bucket_data导入表tb1_bucket_data,其数据如下所示:
[root@hadoop d2]# more tb1_bucket_data
1 a
2 b
3 c
4 d
5 e
6 f
7 g
8 h
9 j
10 k
hive> load data local inpath ‘/usr/local/d2/tb1_bucket_data’ into table tb1_bucket_data;
开启桶操作
hive> set hive.enforce.bucketing=true;
加载数据
hive> insert into table tb1_bucket select * from tb1_bucket_data;
hive> select * from tb1_bucket;
OK
9 j
6 f
3 c
10 k
7 g
4 d
1 a
8 h
5 e
2 b
Time taken: 0.218 seconds, Fetched: 10 row(s)
分析,经过hash求余后余数为0、1、2的数据各自放在一起,如下图所示:
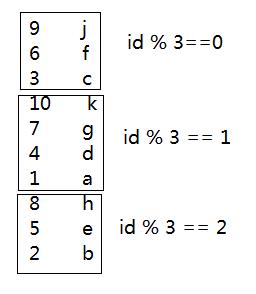
那么查看HDFS对应的目录结构如下所示:
[root@hadoop d2]# hdfs dfs -ls /user/hive/warehouse/tb1_bucket
-rw-r–r– 1 root supergroup 12 2016-10-04 00:08 /user/hive/warehouse/tb1_bucket/000000_0
-rw-r–r– 1 root supergroup 17 2016-10-04 00:08 /user/hive/warehouse/tb1_bucket/000001_0
-rw-r–r– 1 root supergroup 12 2016-10-04 00:08 /user/hive/warehouse/tb1_bucket/000002_0
那么查询hash后的散列文件如下所示:
[root@hadoop d2]# hdfs dfs -text /user/hive/warehouse/tb1_bucket/000000_0
9j
6f
3c
[root@hadoop d2]# hdfs dfs -text /user/hive/warehouse/tb1_bucket/000001_0
10k
7g
4d
1a
[root@hadoop d2]# hdfs dfs -text /user/hive/warehouse/tb1_bucket/000002_0
8h
5e
2b
在实际项目开发中,clustered by (id) into 3 buckets具体分几桶则根据具体业务情况而定
(七)总结hive数据加载的方式
1、从本地linux文件系统加载和从HDFS文件系统加载
load data [local] inpath ‘path’ [overwrite] Into table tblName
(1)local参数
有:数据从本地linux的路径中加载,其中path可以是绝对路径,也可以是相对路径
例如:load data local inpath ‘/usr/local/dir/t1_data’ into table t1
无:数据从hdfs上的相应路径中移动数据到表tblName下,相当于hadoop fs -mv hdfs_uri_1 hdfs_uri_2
例如:load data inpath ‘/dir/t1_data’ into table t1 上传完毕之后 t1_data将被移动到hive对应目录
(2)overwrite参数
有:覆盖原来的数据,只保留新上传的数据
例如:load data local inpath ‘/usr/local/d2/t2’ overwrite into table t2;
无:在原来的目录下,再增加一个数据文件
2、从其它表加载数据
语法形式:
Insert [into/overwrite] table t1 select columns… from t2;
例如:
(1) insert into table t1 select id from t2;
使用方法类似传统关系型数据库的sql
(2)insert overwrite table t1 select id from t2
使用overwirte 来覆盖掉原来的数据
(3)向分区表中插入数据
建立个分区表
create table t1(
p_id int,
p_name string
)
partitioned by (p_province string,p_city string)
row format delimited
fields terminated by ‘t’
在本地linux下有/usr/local/d2/t1文件,信息如下:
[root@hadoop d2]# more t1
1 lily1
2 lily2
3 lily3
使用hive插入数据
load data local inpath ‘/usr/local/d2/t1′ into table t1 partition(p_province=’heilongjiang’,p_city=’haerbin’)
操作如下:
hive> load data local inpath ‘/usr/local/d2/t1′ into table t1 partition (p_province=’heilongjiang’,p_city=’haerbin’);
Loading data to table db2.t1 partition (p_province=heilongjiang, p_city=haerbin)
Partition db2.t1{p_province=heilongjiang, p_city=haerbin} stats: [numFiles=1, numRows=0, totalSize=24, rawDataSize=0]
OK
Time taken: 1.232 seconds
hive> select * from t1;
OK
1 lily1 heilongjiang haerbin
2 lily2 heilongjiang haerbin
3 lily3 heilongjiang haerbin
Time taken: 0.603 seconds, Fetched: 3 row(s)
hive>
假设在Linux下的数据文件/usr/local/d2/t1文件内容修改如下:
[root@hadoop d2]# more t1
4 lily4
5 lily5
6 lily6
再次执行如下操作:
hive> load data local inpath ‘/usr/local/d2/t1′ into table t1 partition (p_province=’zhejiang’,p_city=’hangzhou’);
hive> select * from t1;
OK
1 lily1 heilongjiang harbin
2 lily2 heilongjiang harbin
3 lily3 heilongjiang harbin
4 lily4 zhejiang hangzhou
5 lily5 zhejiang hangzhou
6 lily6 zhejiang hangzhou
(4)使用动态分区表
建立的表t2:
create table t2(
p_id int,
p_name string
)
partitioned by (p_province string,p_city string)
row format delimited
fields terminated by ‘t’
或者也可以使用简单方法建立和t1一模一样的表create table t2 like t1;
由于表的分区很多,那么如果一个分区一个分区的插入,类似如下操作会很麻烦:
hive> insert overwrite table t2 partition(p_province=’heilongjiang’,p_city=’haerbin’) select p_id,p_name from t1 where p_province=’heilongjiang’ ;
hive> select * from t2;
OK
1 lily1 heilongjiang harbin
2 lily2 heilongjiang harbin
3 lily3 heilongjiang harbin
Time taken: 0.106 seconds, Fetched: 3 row(s)
hive>
那么,我们开启动态分区支持
set hive.exec. dynamic .partition=true; //使用动态分区
(可通过这个语句查看:set hive.exec.dynamic.partition;)
set hive.exec.dynamic.partition.mode=nonstrict;//无限制模式
如果模式是strict,则必须有一个静态分区,且放在最前面。
SET hive.exec.max.dynamic.partitions.pernode=10000;每个节点生成动态分区最大个数
set hive.exec.max.dynamic.partitions=100000;,生成动态分区最大个数,如果自动分区数大于这个参数,将会报错
set hive.exec.max.created.files=150000; //一个任务最多可以创建的文件数目
set dfs.datanode.max.xcievers=8192;//限定一次最多打开的文件数
hive> insert overwrite table t2 partition(p_province,p_city) select p_id,p_name,p_province,p_city from t1;
hive> select * from t1;
OK
1 lily1 heilongjiang harbin
2 lily2 heilongjiang harbin
3 lily3 heilongjiang harbin
4 lily4 zhejiang hangzhou
5 lily5 zhejiang hangzhou
6 lily6 zhejiang hangzhou
3、import和export
export可以将表数据导入到hdfs目录中,注意该目录必须事先是空目录,操作如下:
hive> export table t2 to ‘/d2/t2’;
import操作将从hdfs目录中的数据导入表中,这时系统将自动帮你创建一个表。操作如下:
hive> import table t2_bak2 from ‘/d2/t2’;

《大数据和人工智能交流》的宗旨
1、将大数据和人工智能的专业数学:概率数理统计、线性代数、决策论、优化论、博弈论等数学模型变得通俗易懂。
2、将大数据和人工智能的专业涉及到的数据结构和算法:分类、聚类 、回归算法、概率等算法变得通俗易懂。
3、最新的高科技动态:数据采集方面的智能传感器技术;医疗大数据智能决策分析;物联网智慧城市等等。
根据初学者需要会有C语言、Java语言、Python语言、Scala函数式等目前主流计算机语言。
根据读者的需要有和人工智能相关的计算机科学与技术、电子技术、芯片技术等基础学科通俗易懂的文章。


