
RPC 的目的,是将远程调用变得像本地调用一样简单方便,主要由客户端、服务端、注册中心三部分组成。
那么,服务端发布的接口怎么向客户端暴露?客户端怎么获取到服务端的地址并创建连接执行调用逻辑呢?
本篇将带大家 通过分析一个由 zookeeper 引发的全链路服务雪崩的真实案例,来说明注册中心的生产场景诉求和选型原则。
0.1注册中心

如图所示
Provider 主要向注册中心进行服务注册,以及上报服务节点心跳。
Consumer 需要向注册中心订阅感兴趣的服务,将对应服务的节点信息缓存到本地,同时接受注册中心下发的服务变动通知。
注册中心 的职权也很明确了,就是维护服务信息以及服务实例节点信息,同时监测服务节点心跳,确认节点状态,在节点状态不健康时,从实例列表中剔除;同时在节点列表变动时,负责通知订阅者,以实现服务的及时更新和数据一致性
0.2Zookeeper 注册中心实现方案
ZK曾经真的非常火,当然现在也不差。很多年之前,同事曾经笑称,只要架构里用上ZK,就可以叫分布式。
ZK是经常被提及的注册中心选型。那么ZK怎么实现注册中心呢?
节点创建的能力
持久化节点。在节点创建后,就一直存在,直到有删除操作来主动清除这个节点。
临时节点。将自身的生命周期和客户端状态绑定。如果客户端会话失效,那么这个节点就会自动被清除掉。注意,这里提到的是会话失效,而非连接断开。
监听通知的能力
也就是Watch机制。一个zk的节点可以被监控,包括这个目录中存储的数据的修改,子节点目录的变化,一旦变化可以通知设置监控的客户端。
这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的集中管理,集群管理,分布式锁等等。
ZK的上述两个关键能力,让其成为注册中心成为可能 。
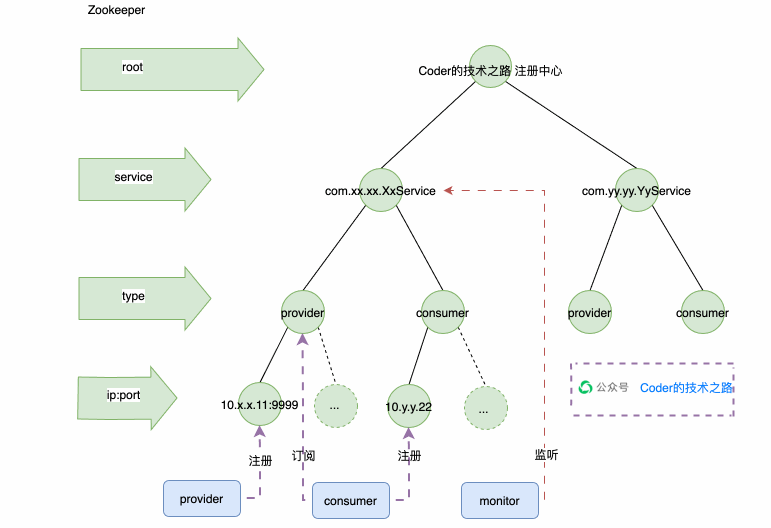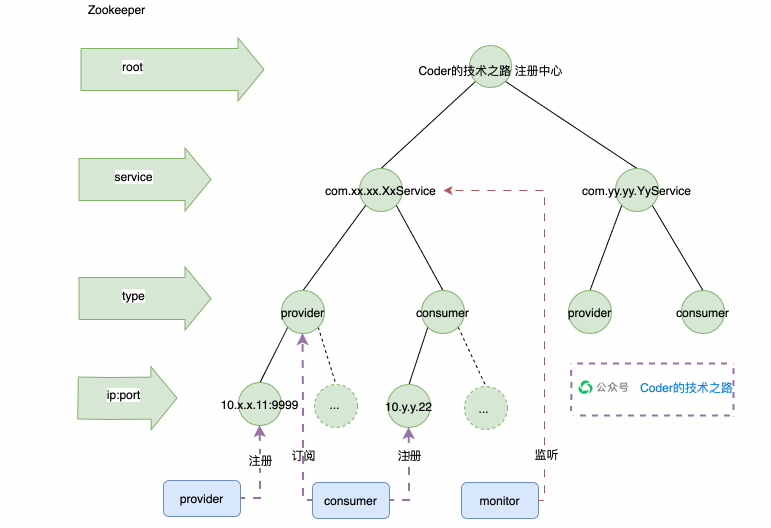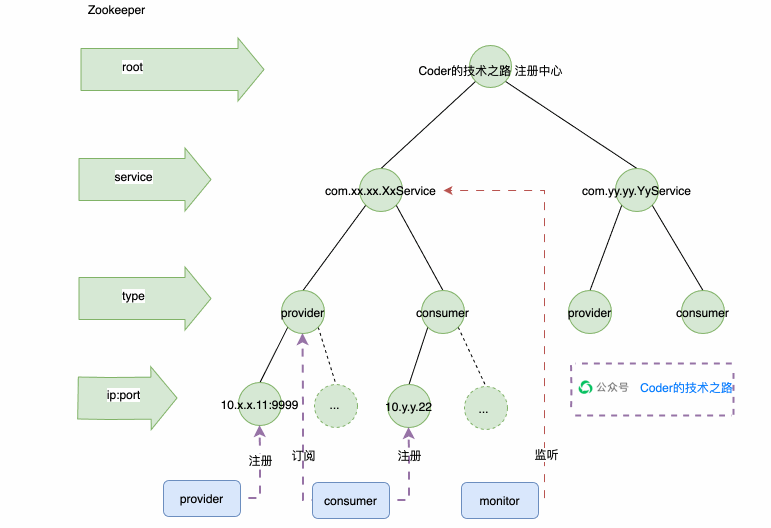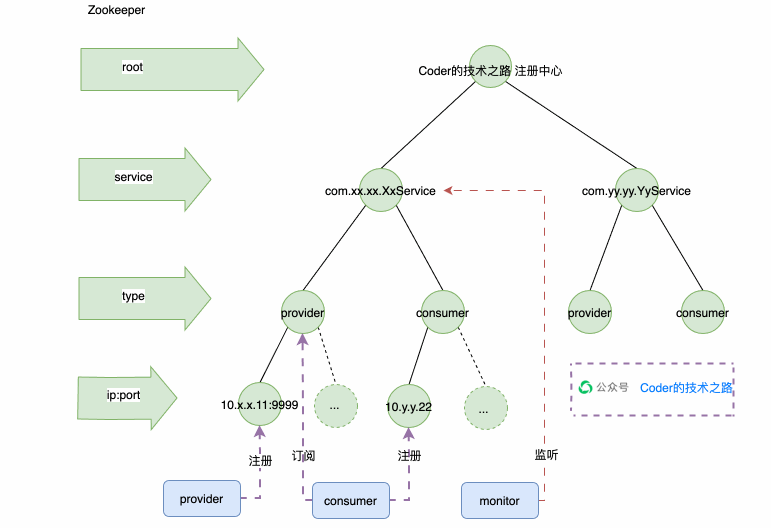
Zookeeper注册中心
如上图所示,ZK创建了Service的持久化节点,在Service下创建了Provider和Consumer两个子节点,也是持久化的;在Provider和Consumer下挂着很多临时节点,每一个临时节点,代表一个应用实例。这样方便根据实例状态进行动态增减。然后用wtach机制来监听服务端心跳,通知客户端服务节点的变动,从而实现注册中心的整个能力。
0.3用Zookeeper真的合适么
前些时候,一篇 阿里 为什么不用 Zookeeper 做服务发现的文章被纷纷传阅。这里,我们对涉及到主要观点再做下简要阐述:
1、注册中心的高可用诉求
问:CAP中注册中心一定要保证的是谁?
是分区容错性。
分布式服务依赖网络进行节点连通,在遇到任何网络分区故障时,仍然需要能够保证系统可以对外提供服务(一致性 或 可用性的服务),除非是整个网络环境都发生了故障。
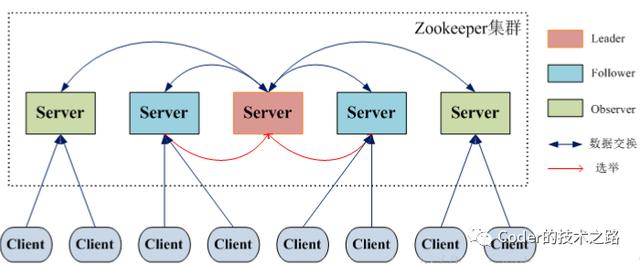
来源:www.w3cschool.cn/zookeeper/
我们不允许当节点间通信出现故障时,被孤立节点都不能提供服务。最简单的,可以让所有节点拥有所有数据。
问:在分区容错前提下,注册中心需要保的是一致性还是可用性?
如果保证一致性,是否可以满足我们对系统的诉求呢。
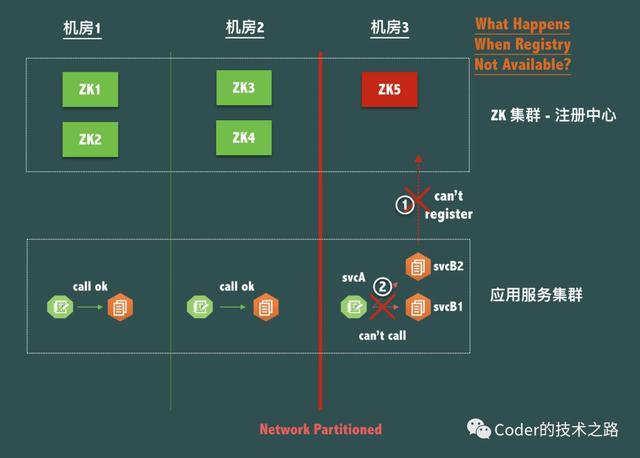
来源:infoq.cn/article/why-doesnot-alibaba-use-zookeeper
如图,假如机房3 内部署了ServiceA,ServiceB,连接ZK5,由于发生网络异常,ZK5节点无法工作,则serviceB的实例都无法进行注册,处于机房3内的serviceA , 无法正常调用ServiceB的任何实例,这个是我们不希望看到的。
而如果保证可用性,因为机房内部各节点是连通的,因此,调用无影响,这才更符合我们的希望。
然而,zookeeper实际上实现的是CP原则。当在Leader选举过程中或一些极端情况下,整个服务是不可用的。
但是我们对于注册中心的可用性诉求,要比数据一致性要大得多。也可以说,生产环境,我们是无法容忍注册中心无法保证可用性。这对实际生产的影响是灾难性的。
2、注册中心的容灾诉求
在实践中,注册中心不能因为自身的任何原因破坏服务之间本身的可连通性。所以,如果整个注册中心 宕机 了呢?
但是,zookeeper是无法实现跨机房、跨地域容灾的。
因为,它只能存在一个leader。
3、服务规模、容量的增长
互联网的发展,有一定的偶发性,现在的节点上限、带宽能满足业务发展,1年后也能满足么? 3年后呢?
当扛不住后,ZK能水平扩展么?
0.4Zookeeper导致的链路雪崩回顾
可能有的人对上述提及的点觉得很有道理,但是没有多少实际感受。
然而,对于亲身经历过2015年 JD 大促时全链路雪崩的我来说,却感触颇深。
虽然那时候的我,还是个刚参加工作不久的孩子。
历史回顾:
那个风和日丽的上午,因为促销活动早就漫天宣传,我和组里的大佬们,早早地就坐在电脑前监控系统指标。
9、10点钟,突然有一部分系统报警变多,其中的一部分机器频繁报警–连不上注册中心。
正促销呢,快,重启一下,试试能不能解决。
然而没用,更多的服务,以及更多的节点出现问题,异常从固定的机房扩展到了全部节点。
我们知道,注册中心应该是全挂了。
不断地重启希望重连注册中心,然并卵。
后来有平台的同学说先暂时不要重启,等待通知。经过漫长的等待,终于,可以重启了,果然,都连上了,但是,黄花菜。。。
到底发生了什么:
刚开始,一定是注册中心某一节点挂了,是因为秒杀活动等节点大量扩容,还是带宽打满现在不得而知了,总之是挂了。
因为Zookeeper保证的是CP,那此时只有连接Leader的那些节点能提供服务。所以,出现问题的机房,虽然业务服务器都没问题,但是没法提供服务。
可是,用户请求不会少,大量的请求被分流到了正常的机房的服务器上,业务系统扛不住挂了。连带着吧注册中心也冲垮了。
然而,ZK不保证可用性,在选举Leader等情况下是没法正常服务的。
所以,大量的业务系统同一时间想通过重启重连注册中心,要么是连不上,要么,大量写操作一起去注册服务节点,再次把注册中心冲垮。
毕竟,想要保证在高并发情况下节点创建的全局唯一,必然要付出更多的系统资源。
恶性循环出现了,越重启,越起不来。。。
所以,后面当平台要求分批重启,才使得注册中心得以恢复正常。
0.5注册中心的选型
综上所述,注册中心是需要保证AP原则,需要考虑扩容和容灾 。
JD的注册中心优化方案:
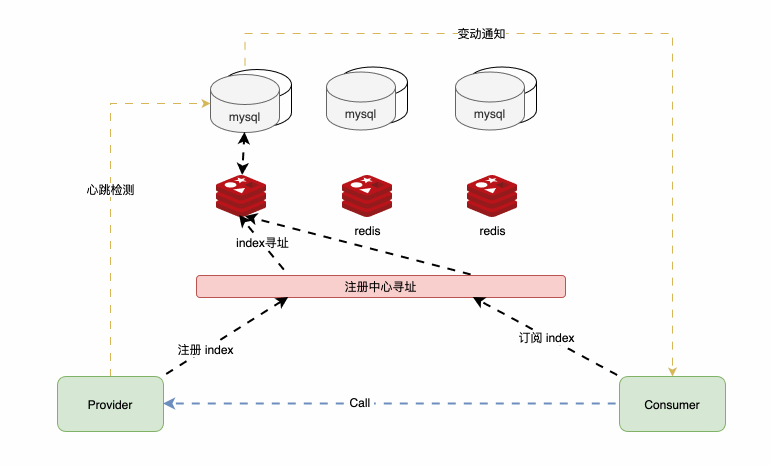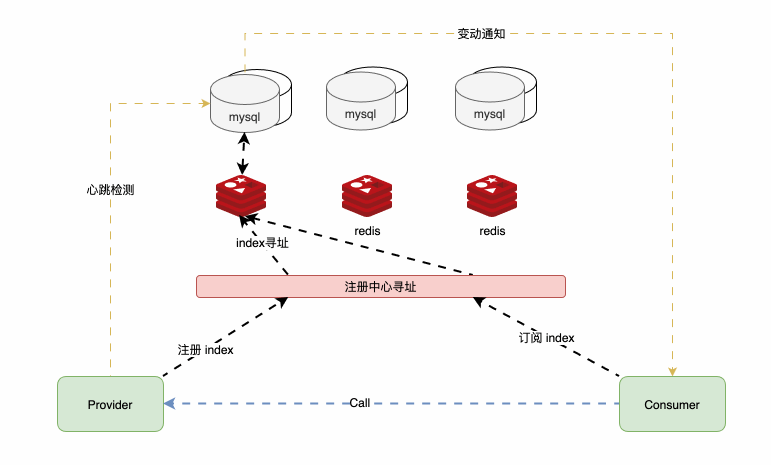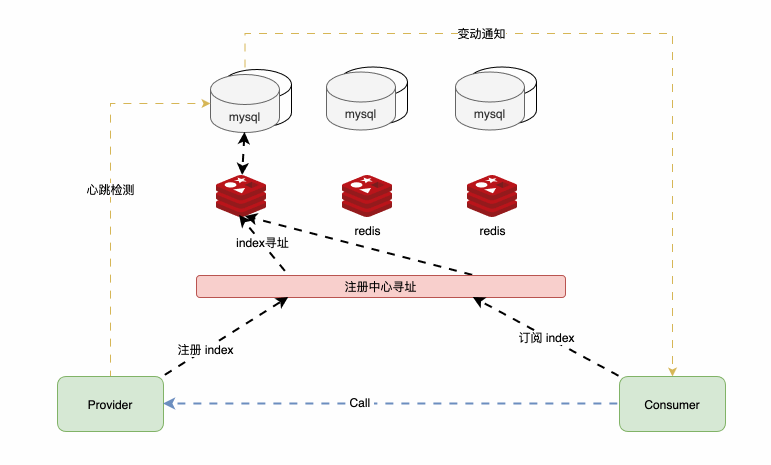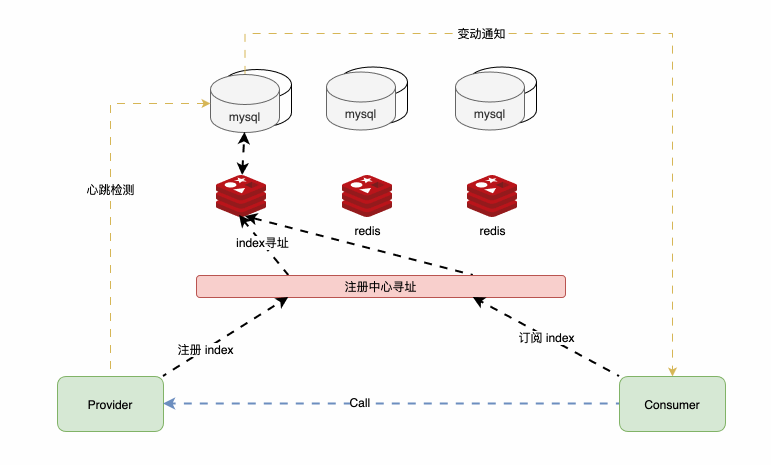
用mysql+redis 的KV形式,代替了zookeeper的树状形式;用户注册中心寻址来对注册中心分片,以实现水平扩展,并支持 容灾 。
Eureka2.0的实现
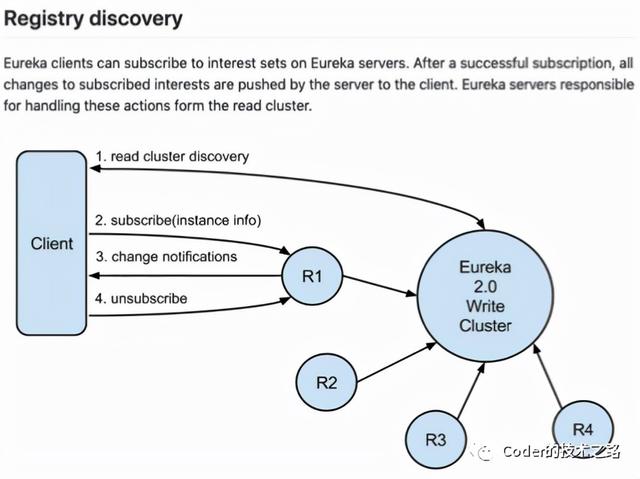
Eureka2.0在方案上支持读写集群的分离,这个思路也被蚂蚁开源的sofa注册中心中采用。
其实,大概浏览一下就会发现,当前比较火的开源注册中心,其实都是按高可用,可扩展,可容灾恢复的方向上进行的。
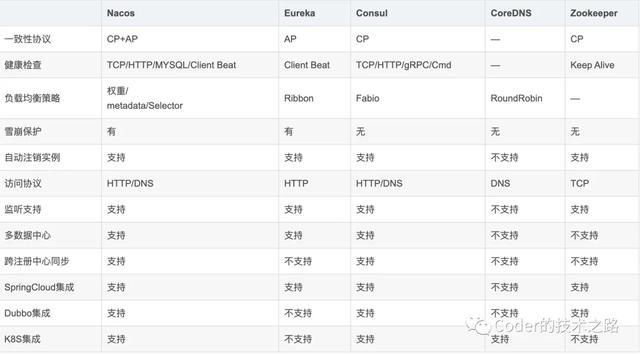
摘自:blog. csdn .net/fly910905/article/details/100023415


