网络通信的开发,就涉及到一些开发框架: Java NIO 、 Netty 、 Mina 等等。
理论上来说,类似于序列化器,可以为其定义一套统一的接口,让不同类型的框架实现,事实上, Dubbo 就是这么干的。
但是,作为一个简单的 RPC 框架, ccx- RPC 就先不统一了,因为基本上网络框架是不会换的,而且统一起来代码量巨大。
ccx-rpc 选择的网络框架是 Netty , Netty 是一款大名鼎鼎的异步事件驱动的网络应用程序框架,支持快速地开发可维护的高性能的面向协议的服务器和客户端。
Netty 在 JDK 自带的 NIO 基础之上进行了封装,解决了 JDK 自身的一些问题,具备如下优点:
- 入门简单,使用方便,文档齐全,无其他依赖,只依赖 JDK 就够了。
- 高性能,高吞吐,低延迟,资源消耗少。
- 灵活的 线程 模型,支持阻塞和非阻塞的I/O 模型。
- 代码质量高,目前主流版本基本没有 Bug。
下面我们先来介绍一下 Netty 的核心设计吧。
Netty 线程模型设计#
服务收到请求之后,执行的逻辑大致有:编解码、消息派发、业务处理以及返回响应。这些逻辑是放到一个线程串行执行,还是分配到不同线程中执行,会对程序的性能产生很大的影响。优秀的线程模型对一个高性能网络库来说是至关重要的。
Netty 采用了 Reactor 线程模型的设计。
什么是 Reactor#
Wikipedia 的定义是:
从上面的定义可以看出有几个重点:
- 事件驱动
- 能处理一个或多个输入源
- 多路复用、分发事件给对应的处理器
Reactor 线程模型有几个角色:
- Reactor:负责响应事件,将事件分发给绑定了该事件的 Handler 处理;
- Handler:事件处理器,绑定了某类事件,负责对事件进行处理;
- Acceptor:Handler 的一种,绑定了连接事件。当客户端发起连接请求时,Reactor 会将 accept 事件分发给 Acceptor 处理。
简单来说,其核心原理是 Reactor 负责监听事件,在监听到事件之后,分发给相关线程的处理器进行处理。
为什么用 Reactor#
我们先来看看 传统阻塞 I/O 模型的缺点 :
- 每个连接都需要独立线程处理,当并发数大时,创建线程数多,占用资源
- 采用阻塞 I/O 模型,连接建立后,若当前线程没有数据可读,线程会阻塞在读操作上,造成资源浪费
针对传统阻塞 I/O 模型的两个问题,可以采用如下的方案
- 基于池化思想,避免为每个连接创建线程,连接完成后将业务处理交给 线程池 处理
- 基于 I/O 复用模型,多个连接共用同一个阻塞对象,不用等待所有的连接。遍历到有新数据可以处理时,操作系统会通知程序,线程跳出阻塞状态,进行业务逻辑处理
Reactor 线程模型的思想就是 线程池 和 I/O复用 的结合。
为了帮助你更好地了解 Netty 线程模型的设计理念,我们将从最基础的单 Reactor 单线程模型开始介绍,然后逐步增加模型的复杂度,最终到 Netty 目前使用的非常成熟的线程模型设计。
1. 单 Reactor 单线程#
Reactor 对象监听客户端请求事件,收到事件后通过进行分发。
- 如果是 建立连接 事件,则由 Acceptor 通过 Accept 处理连接请求,然后创建一个 Handler 对象处理连接建立之后的业务请求。
- 如果是 读写 事件,则 Reactor 会将事件分发对应的 Handler 来处理,由单线程调用 Handler 对象来完成读取数据、业务处理、发送响应的完整流程。
具体情况如下图所示:
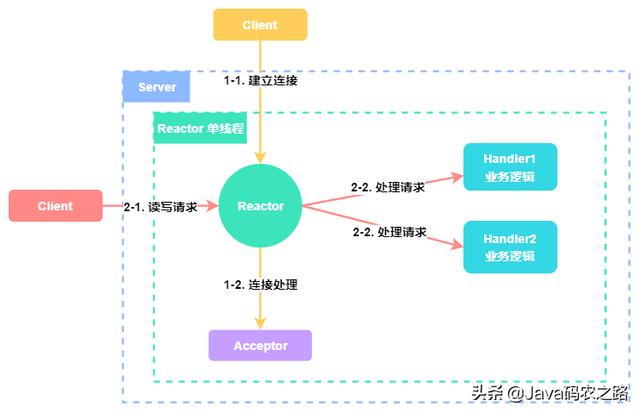
单 Reactor 单线程的优点就是:线程模型简单,没有引入多线程,自然也就没有多线程并发和竞争的问题。
但其缺点也非常明显,那就是性能瓶颈问题,一个线程只能跑在一个 CPU 上,能处理的连接数是有限的,无法完全发挥 多核 CPU 的优势。一旦某个业务逻辑耗时较长,这唯一的线程就会卡在上面,无法处理其他连接的请求,程序进入假死的状态,可用性也就降低了。正是由于这种限制,一般只会在 客户端 使用这种线程模型。
2. 单 Reactor 多线程#
其流程跟 “单 Reactor 单线程” 的流程差不多,也是 Acceptor 处理连接事件,Handler 处理读写事件。
唯一的区别就是:Handler 处理请求的时候,使用的是 线程池 来处理。
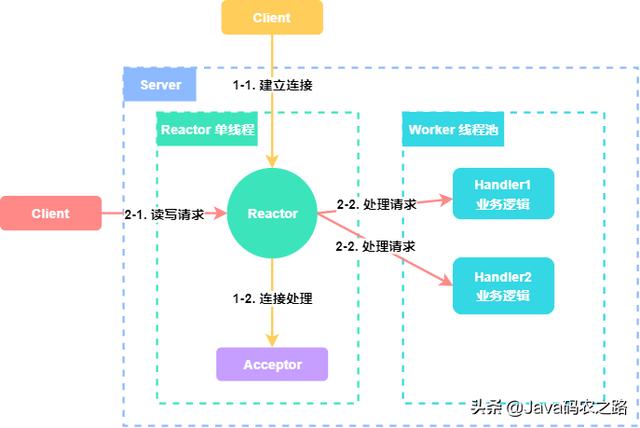
很明显,单 Reactor 多线程的模型可以充分利用多核 CPU 的处理能力,提高整个系统的吞吐量,但引入多线程模型就要考虑线程并发、数据共享等问题。
在这个模型中,只有 一个线程 来处理 Reactor 监听到的所有 I/O 事件,其中就包括连接建立事件以及读写事件,当连接数不断增大的时候,这个唯一的 Reactor 线程也会遇到瓶颈。
3. 主从 Reactor 多线程#
为了解决单 Reactor 多线程模型中的问题,我们可以引入多个 Reactor。
- Reactor 主线程接收建立连接事件,然后给 Acceptor 处理。网络连接建立之后,主 Reactor 会将连接分配给 子 Reactor 进行后续监听。
- 子 Reactor 分配到连接之后,负责监听该连接上的读写事件。读写事件到来时分发给 Worker 线程池的 Handler 处理。
4. Netty 线程模型#
Netty 同时支持上述几种线程模式,Netty 针对服务器端的设计是在主从 Reactor 多线程模型的基础上进行的修改,如下图所示:
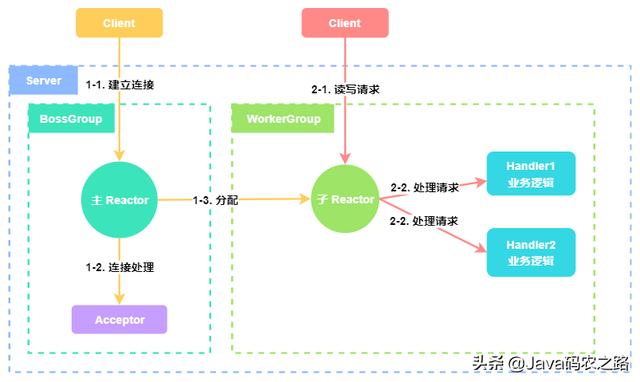
Netty 抽象出两组线程池:BossGroup 专门用于接收客户端的连接,WorkerGroup 专门用于网络的读写。
BossGroup 里的线程 会监听连接事件,与客户端建立网络连接后,生成相应的 NioSocketChannel 对象,表示一条网络连接。之后会将 NioSocketChannel 注册到 WorkerGroup 中某个线程上。
WorkerGroup 里的线程会监听对应连接上的读写事件,当监听到读写事件的时候,会通过 Pipeline 添加的多个处理器进行处理,每个处理器中都可以包含一定的逻辑,例如编解码、心跳、业务逻辑等。
Netty 的核心组件#
介绍完 Netty 优秀的线程模型设计,接下来开始介绍 Netty 的核心组件。
1. EventLoopGroup / EventLoop#
在前面介绍 Netty 线程模型的时候,提到 BossGroup 和 WorkerGroup,他们就是 EventLoopGroup ,一个 EventLoopGroup 当中会包含一个或多个 EventLoop ,EventLoopGroup 提供 next 接口,可以从一组 EventLoop 里面按照一定规则获取其中一个 EventLoop 来处理任务。EventLoop 从表面上看是一个不断循环的 线程 。
EventLoop 最常用的实现类是:NioEventLoop,一个 NioEventLoop 包含了一个 Selector 对象, 可以支持多个 Channel 注册在其上,该 NioEventLoop 可以同时服务多个 Channel,每个 Channel 只能与一个 NioEventLoop 绑定,这样就实现了线程与 Channel 之间的关联。
EventLoop 并不是一个纯粹的 I/O 线程,它除了负责 I/O 的读写之外,还兼顾处理以下两类任务:
- 系统任务 :通过调用 NioEventLoop 的 execute(Runnable task) 方法实现,Netty 有很多系统任务,当 I/O 线程和用户线程同时操作网络资源时,为了防止并发操作导致的锁竞争,将用户线程的操作封装成任务放入消息队列中,由 I/O 线程负责执行,这样就实现了局部无锁化。
- 定时任务 :通过调用 NioEventLoop 的 schedule(Runnable command, long delay, TimeUnit unit) 方法实现。
2. Channel#
Channel 是 Netty 对网络连接的抽象,核心功能是执行网络 I/O 操作,是服务端和客户端进行 I/O 数据交互的媒介。
工作流程:
- 当客户端连接成功,将新建一个 Channel 于该客户端进行绑定
- Channel 从 EventLoopGroup 获得一个 EventLoop,并注册到该 EventLoop,Channel 生命周期内都和该 EventLoop 在一起(注册时获得selectionKey)
- Channel 与客户端进行网络连接、关闭和读写,生成相对应的 event(改变selectinKey信息),触发 EventLoop 调度线程进行执行
- 如果是读事件,执行线程调度 Pipeline 来处理逻辑
3. Pipeline#
上面介绍 Channel 的时候提到,如果是读事件,则通过 Pipeline 来处理。一个 Channel 对应一个 Pipeline,一个 Pipeline 由多个 Handler 串成一个有序的链表,一个 Handler 处理完,调用 next 获得下一个 Handler 进行处理。
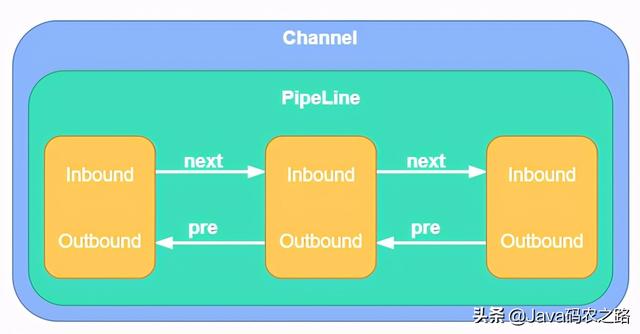
上图黄色部分即为 Handler,一个 Handler 可以是 Inbound、OutBound。处理入站事件时,Handler 按照正向顺序执行。处理出站事件时,Handler 按照 反向 顺序执行。
常规 Pipeline 的 Handler 注册代码如下:
new ChannelInitializer<SocketChannel>() {
@ Override
protected void initChannel(SocketChannel ch) {
ChannelPipeline p = ch.pipeline();
// 30 秒之内没有收到客户端请求的话就关闭连接
p.addLast(new IdleStateHandler(30, 0, 0, TimeUnit.SECONDS));
// 编解码器
p.addLast(new NettyEncoder());
p.addLast(new NettyDecoder());
// RPC 消息处理器
p.addLast(serviceHandlerGroup, new NettyServerHandler());
}
}
4. ByteBuf#
在进行跨进程远程交互的时候,我们需要以字节的形式发送和接收数据,发送端和接收端都需要一个高效的数据容器来缓存字节数据, byte Buf 就扮演了这样一个数据容器的角色。
ByteBuf 类似于一个 字节数组 ,其中维护了一个读索引( readerIndex )和一个写索引( writerIndex ),分别用来控制对 ByteBuf 中数据的读写操作。还有一个 capacity 用来记录缓冲区的总长度,当写数据超过 capacity 时,ByteBuf 会自动扩容,直到 capacity 达到 maxCapacity 。
ByteBuf 的结构如下:
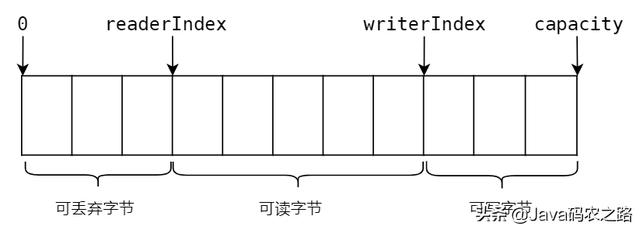
Netty 中主要分为以下三大类 ByteBuf:
- Heap Buffer (堆缓冲区):这是最常用的一种 ByteBuf,它将数据存储在 JVM 的堆空间,其底层实现是在 JVM 堆内分配一个数组,实现数据的存储。堆缓冲区可以快速分配,当不使用时也可以由 GC 轻松释放。
创建代码: Unpooled.buffer() 或者 ctx.alloc().buffer() - Direct Buffer (直接缓冲区):直接缓冲区会使用堆外内存存储数据,不会占用 JVM 堆的空间,使用时应该考虑应用程序要使用的最大内存容量以及如何及时释放。直接缓冲区在使用 Socket 传递数据时性能很好,当然,它也是有缺点的,因为没有了 JVM GC 的管理,在分配内存空间和释放内存时,比堆缓冲区更复杂,Netty 主要使用内存池来解决这样的问题。
创建代码: Unpooled.directBuffer() 或者 ctx.alloc().directBuffer() - Composite Buffer (复合缓冲区):我们可以创建多个不同的 ByteBuf,然后提供一个这些 ByteBuf 组合的视图,也就是 CompositeByteBuf。它就像一个列表,可以动态添加和删除其中的 ByteBuf。
例如:一条消息由 header 和 body 两部分组成,将 header 和 body 组装成一条消息发送出去,可能 body 相同,只是 header 不同,使用CompositeByteBuf 就不用每次都重新分配一个新的缓冲区。
创建代码: Unpooled.compositeBuffer() 或者 ctx.alloc().compositeBuffer()
Netty 使用 ByteBuf 对象作为数据容器,进行 I/O 读写操作,其实 Netty 的内存管理也是围绕着 ByteBuf 对象高效地分配和释放。从 内存管理 角度来看,ByteBuf 可分为 Unpooled 和 Pooled 两类。
- Unpooled :是指 非池化 的内存管理方式。每次分配时直接调用系统 API 向操作系统申请 ByteBuf,在使用完成之后,通过系统调用进行释放。Unpooled 将内存管理完全交给系统,不做任何特殊处理,使用起来比较方便,对于申请和释放操作不频繁、操作成本比较低的 ByteBuf 来说,是比较好的选择。
使用示例: Unpooled.buffer() - Pooled :是指 池化 的内存管理方式。该方式会预先申请一块大内存形成 内存池 ,在需要申请 ByteBuf 空间的时候,会将内存池中一部分合理的空间封装成 ByteBuf 给服务使用,使用完成后回收到内存池中。前面提到 DirectByteBuf 底层使用的堆外内存管理比较复杂,池化技术很好地解决了这一问题。
池化分配器 ByteBufAllocator 需要从 ChannelHandlerContext 中获取实例: ByteBufAllocator byteBufAllocator = ctx.alloc() ,然后再生成 ByteBuf 对象: Byte BufAllocator.buffer()`
最后,我们来总结一下 ByteBuf 的优点:
- 通过内置的复合缓冲区类型实现了透明的零拷贝。
- 容量可以按需增长。
- 在读和写这两种模式之间切换不需要调用 ByteBuffer 的 flip()方法。
- 读和写使用了不同的索引。
- 支持引用计数。
- 支持池化。
总结#
上面我们介绍了 Netty 优秀的线程模型和核心组件,Netty 优秀的设计还有很多,感兴趣的读者可以再去深入了解,以上介绍的已经够写一个 RPC 框架了。
接下来,我们就要讲到 网络通信 的核心实现了,敬请期待!


