第一步:安装需要用到的安装包
jdk-8u101-windows-x64
tesseract-ocr-setup-3.05.01
jTessBoxEditor-1.7.3
简体中文chi_sim
注意 tesseract需要编译器(安装包没提供)Supported Compilers are:
-
GCC 4.8 and above
-
Clang 3.4 and above
-
MSVC 2015, 2017
安装略…
第二步:tesseract-OCR初认识
-l lang
使用的语言。如果没有指定,则采用英文。可以指定多种语言,由加号字符分隔。Tesseract使用3个字符的ISO 639-2语言代码。(请参阅语言)
–psm N
将Tesseract设置为只运行布局分析的一个子集并假定某种形式的图像。N的选项是:
-
0 =只有方向和脚本检测( OSD )。
-
1 =使用OSD自动分页。
-
2 =自动分页,但没有OSD或OCR。
-
3 =全自动页面分割,但没有OSD。(默认)
-
4 =假设一列可变大小的文本。
-
5 =假设一个统一的垂直排列文本块。
-
6 =假设一个统一的文本块。
-
7 =将图像作为单个文本行处理。
-
8 =将图像视为一个单词。
-
9 =将图像视为一个圆圈中的单个单词。
-
10 =将图像视为单个字符。
基本的命令行用法:
tesseract imagename outputbase [-l lang ] [–oem ocrenginemode] [–psm pagesegmode] [configfiles…]
第三步:jTessBoxEditor训练字库
之前玩冲顶大会的时候用过tesseract-OCR识别中文,可惜准确率很不理想,如下图:

使用tesseract-OCR识别会得到
tesseract question. jpg result -l chi_sim –psm 6
result.txt
8.手木几生产商诺墓亚最子刀是L又生产{十么为主?
发现错了好多,机、基、初、以都没有识别出来,有的还识别成两个字。这个时候就需要我们来训练中文字库。
准备好要识别的图片question.jpg
第一步:
1、将图片转换成tif格式,用于后面生成box文件。可以通过画图,然后另存为tif即可。tif文面命名格式是有要求的:
lang 语言名(这可自定义,不要与现有的相同 eng、chi_sim等)
fontname 字体(就是字体名字,比如normal、italic、bold)
num 序号
把question.jpg用自带的画图另存为hojun.normal.exp0.jpg和hojun.normal.exp0.tif(注意,重命名改后缀不行),放在E:TessBox下
接着打开cmd进入到该文件下,输入以下命令:
[lang].[fontname].exp[num].tif
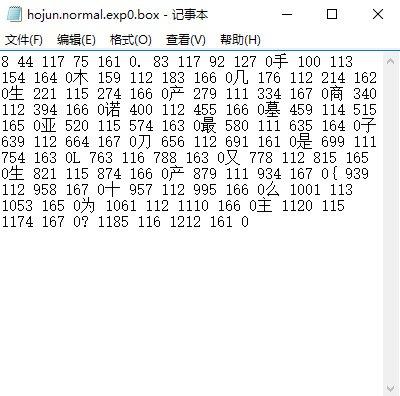
会得到hojun.normal.exp0.box文件,右键使用记事本打开效果如下图
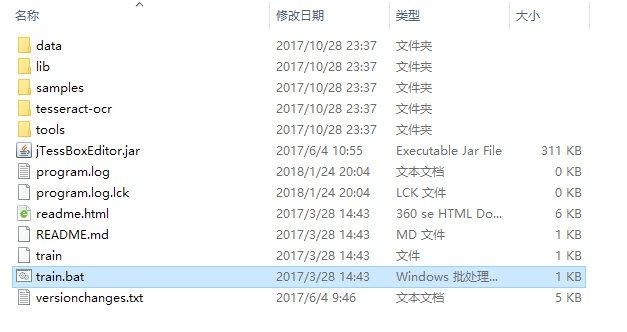
打开jTessBoxEditor目录,双击train.bat打开(可能要等待5-6秒,耐心等待程序响应)
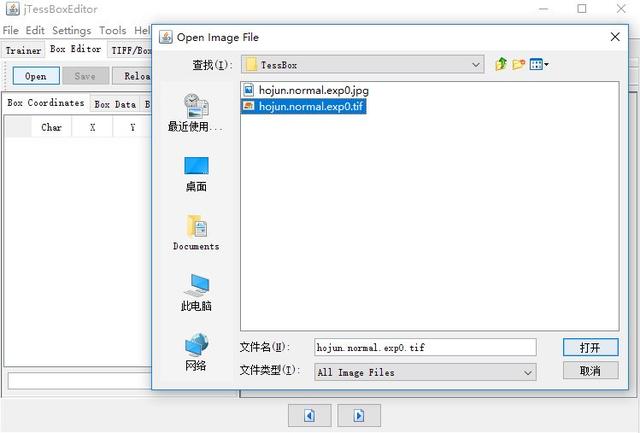
打开软件后点击Box Editor->Open->选择对应的tif文件打开
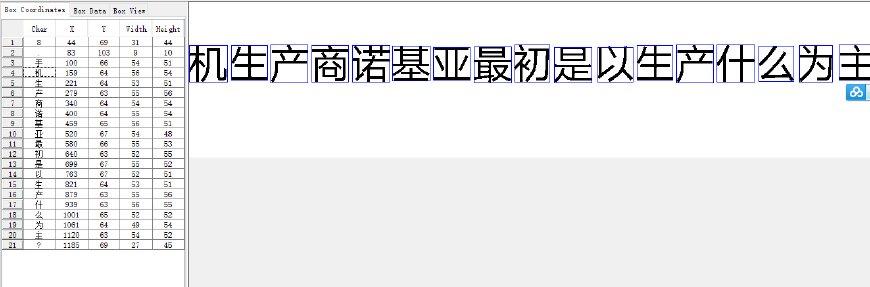
得到如下效果

如果右边字体没有框框,左边没有内容是因为 java 8没安装好,或者安装了两个java版本,使用的是其他java版本
可以在控制台输入
来查看java版本。如果使用其他版本的,一般在环境变量Path里面把java8的路径写在最前面就行。
接下来就是调整了。删删改改如下:
然后点击save保存即可。
接着在E:TessBox下新建一个font_properties文件,注意没有后缀
里面内容写入normal 0 0 0 0 0 表示默认普通字体
再接着新建一个txt文件,里面内容写入
echo Run Tesseract for Training..
tesseract.exe hojun.normal.exp0.tif hojun.normal.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe hojun.normal.exp0.box
shapeclustering -F font_properties -U unicharset hojun.normal.exp0.tr
mftraining -F font_properties -U unicharset -O unicharset hojun.normal.exp0.tr
echo Clustering..
cntraining.exe hojun.normal.exp0.tr
echoRename Files..
rename normproto hojun.normproto
rename inttemp hojun.inttemp
rename pffmtable hojun.pffmtable
rename shapetable hojun.shapetable
echo Create Tessdata..
combine_tessdata.exe hojun.
echo. & pause
保存,修改文件名为Train.bat。(为了偷懒,你也可以在命令里一句一句命令的敲)
双击批处理文件生成!
成功结果如下
把hojun.traineddata复制到C:Program Files (x86)Tesseract-OCRtessdata下
试着识别
tesseract hojun.normal.exp0.jpg result -l hojun –psm 6
得到正确的结果

参考:
训练Tesseract
Tesseract-OCR的简单使用与训练
Tesseract-OCR识别中文与训练字库实例
JAVA_HOME无效,java版本保持不变的问题解决


