LeadTools为.NET(C# & VB.NET)、C/C++、Java和Web开发者提供了快速且精确度高的 OCR SDK技术。利用LeadTools高级OCR工具包,可以快速的开发健壮的、可扩展的、高性能识别的文档处理应用程序,这些应用程序可提取出扫描文件中的文本,将图像转化为文本搜索格式,如PDF、PDF/A、DOC、DOCX、XML、XPS等。LeadTools广泛支持40余种字符集,编程者通过提供多语言的解决方案扩展用户群,包括英语、西班牙语、法语、德语、日语、中文、阿拉伯语等。
本文主要为大家介绍在OCR文档中如何处理和识别页面以及创建具体应用程序的步骤。
本文概述:
- OCR知识简介
- 创建“使用OCR识别英文”应用程序的具体步骤
OCR知识简介
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。
OCR的识别过程为:图像输入、预处理;二值化;噪声去除;倾斜校正;版面分析;字符切割;字符识别;版面恢复;后处理,校对。
创建“使用OCR识别英文”应用程序的具体步骤
根据以下步骤,您可以轻松创建一个使用OCR识别英文的应用程序。
1. 打开Visual Studio .NET。
2. 点击 文件->新建->项目…。
3. 打开新建项目对话框后,在模板中选择“Visual C#”或“Visual Basic”,随后选择“Windows窗体应用程序”。在名称栏中输入项目名称“OcrTutorial”,并使用“浏览”按钮选择您工程的存储路径,点击“确定”。
4. 在“解决方案资源管理器”中,右击“引用”,选择“添加引用”。在“引用管理器”中,浏览选择Leadtools For .NET文件夹” LEADTOOLS_INSTALLDIRBinDotNetWin32”,选择以下的DLL:
- Leadtools.dll
- Leadtools.Codecs.dll
- Leadtools.Forms.dll
- Leadtools.Forms.DocumentWriters.dll
- Leadtools.Forms.Ocr.dll
- Leadtools.Forms.Ocr.Advantage.dll
- Leadtools.Codecs.Bmp.dll
- Leadtools.Codecs.Cmp.dll
- Leadtools.Codecs.Tif.dll
- Leadtools.Codecs.Fax.dll
注意:添加 Leadtools.Codecs.*.dll 引用后,可使用BMP、JPG、CMP、TIF和FAX图像文件格式。如果您想使用更多的文件格式,可添加相关文件格式的codec DLL至应用程序。
5. 将Form1切换至代码视图,将以下代码添加至using 部分:
using Leadtools;
using Leadtools.Codecs;
using Leadtools.Forms;
using Leadtools.Forms.DocumentWriters;
using Leadtools.Forms.Ocr;
using Leadtools.ImageProcessing;
6. 将以下私有变量添加至Form1类:
private IOcrEngine _ocrEngine;
private IOcrDocument _ocrDocument;
7. 将以下代码添加至Form1的构造函数:
public Form1
{
InitializeComponent;
//解锁OCR功能,用您的密钥替换此处
string MY_LICENSE_FILE = "d:\temp\TestLic.lic";
string MY_DEVELOPER_KEY = "xyz123abc";
RasterSupport.SetLicense(MY_LICENSE_FILE, MY_DEVELOPER_KEY);
//初始化OCR引擎
_ocrEngine = OcrEngineManager.CreateEngine(OcrEngineType.Advantage, false);
}
8. 拖拽5个button控件至Form1。Button的名称默认为“button1,button2…”,根据以下表格修改相应的Text属性:
| Name | Text |
|---|---|
| button1 | 启动OCR引擎 |
| button2 | 添加页面 |
| button3 | 删除页面 |
| button4 | 识别文档(英文)并保存为pdf |
| button5 | 关闭OCR引擎 |
如下图:

9. 将以下代码添加至button1(启动OCR引擎)按钮的Click句柄中,启动OCR引擎:
private void button1_Click(object sender, EventArgs e)
{
//启动OCR引擎
_ocrEngine.Startup(null, null, null, @"C:LEADTOOLS 18BinCommonOcrAdvantageRuntime");
//创建文档
_ocrDocument = _ocrEngine.DocumentManager.CreateDocument;
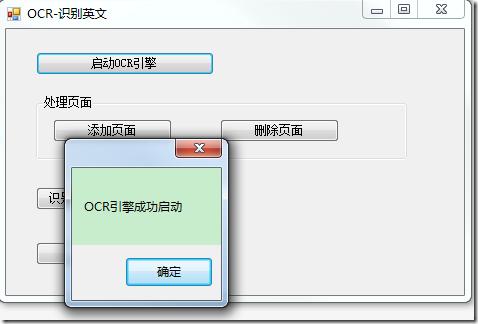
MessageBox.Show("OCR引擎成功启动");
}
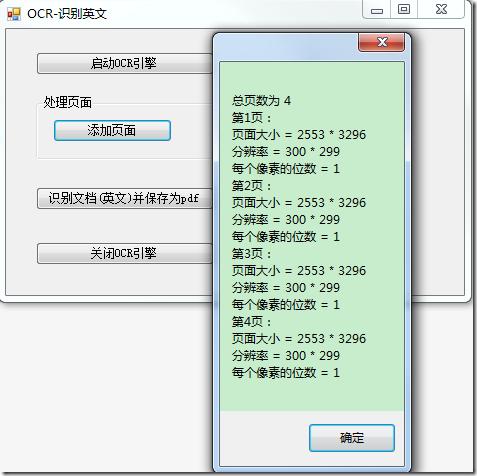
10. 将以下代码添加至button2(添加页面)的Click句柄中,将多页的图像文件添加至OCR文档:
string tifFileName = Path.Combine(Application.StartupPath, @"......PicOcr.tif");
//将4个单页的图像Ocr1.tif、Ocr2.tif、Ocr3.tif、Ocr4.tif合并为Ocr.tif
if (File.Exists(tifFileName))
File.Delete(tifFileName);
using (RasterCodecs codecs = new RasterCodecs)
{
for (int i = 0; i
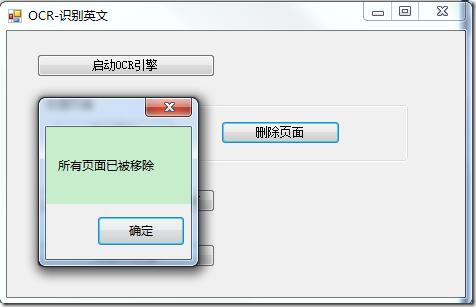
11. 将以下代码添加至button3(删除页面)的Click句柄,从OCR文档中移走了所有的页面:
private void button3_Click(object sender, EventArgs e)
{
//从OCR文档中移除所有添加的页面
_ocrDocument.Pages.Clear;
MessageBox.Show("所有页面已被移除");
}
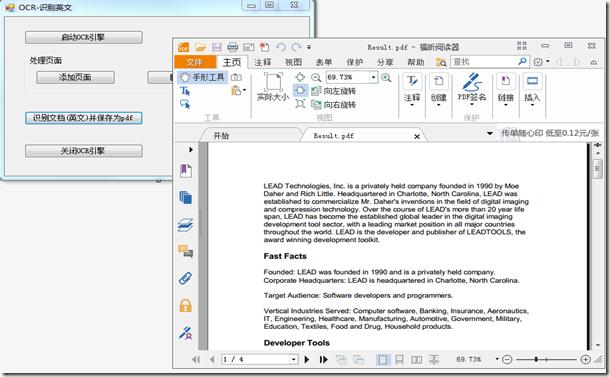
12. 将以下代码添加至button4(识别文档(英文)并保存为pdf)的Click句柄,识别文档中的英文字符,并将识别的结果保存为pdf文档:
// 识别所有页面
// 注意,我们不需要调用AutoZone,引擎会检查页面是否被分区,若无,则会自动分区
_ocrDocument.Pages.Recognize(null);
// 将结果保存为PDF文件
string pdfFileName = Path.Combine(Application.StartupPath, @"......PicResult.pdf");
_ocrDocument.Save(pdfFileName, DocumentFormat.Pdf, null);
// 显示我们刚刚保存的PDF文件
System.Diagnostics.Process.Start(pdfFileName);
13. 将以下代码添加至button5按钮的Click句柄,关闭OCR引擎:
// 释放此文档
_ocrDocument.Dispose;
// 关闭OCR引擎
_ocrEngine.Shutdown;
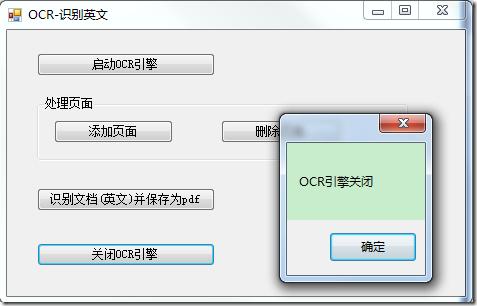
MessageBox.Show("OCR引擎关闭");
此段代码会将最终的识别结果保存为PDF文件。若您想将图像的文字保存为文本搜索格式,可依照以下步骤:启动OCR引擎->添加页面->识别文档(英文)并保存为pdf->删除页面->关闭OCR引擎。
14. 编译、运行程序。结果如下图:
DEMO下载:
OcrTutorial.rar
文章转自:葡萄城控件产品博客,
本文提供的Demo可以高效准确的识别出文档中的英文,为了运行此demo,欢迎。
如需帮助,请联系在线客服!
有用(0)没用(0)
慧都控件|提供软件技术整体解决方案
扫码关注微信
云集全球三千余款优秀控件、软件产品,提供行业领先的咨询、培训与开发服务
微信ID:EVGET_Huidu
企业QQ:800018081|电话:023-66090381


