阅读前说明:此篇文章 hash Map的put的方法,由于篇幅会很长,所以大家细细品读,我相信读完此篇文章,你会对HashMap的put方法有一个非常全面的了解,以后面试会非常的清楚该怎么说。下一篇文章我会用一个图解实例来实战讲解。下面所写是我读JDK 源码 的体会,难免不会出现错误的地方,如果有,请留言,我们大家一起探讨。
上几篇文章我们对HashMap的底层数据结构做了详细的说明,从而我们知道了HashMap的底层数据结构是由:数组+链表+ 红黑树 组成的,数组和链表非常的简单,大家都非常的熟悉,我并没有展开去阐述,关于红黑树,我用了两篇文章( 和 )进行了详细的阐述,这篇文章我通过对经常在项目中使用的HashMap中的put源码解析,来揭开HashMap添加元素的面纱。为了便于说明,我们已map.put(“a”,5)为例说明。本篇文章内容较长,请耐心观看,相信对您理解HashMap的put方法会有所帮助。
在HashMap中put方法的源码如下:
public V put(K key, V value) {
return putVal(hash(key), key, value, false , true);
}
这个put方法并没有做任何的操作,直接把任务交给了putVal方法。我们接下来去看putVal方法。首先贴出putVal的声明:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) hash:就是举例中的"a"的hash值 key:就是举例中的"a" value:就是举例中的5 onlyIfAbsent:官方给的解释:@param onlyIfAbsent if true, don't change existing value ,如果为true,将不能改变已经存在的值,举个例子:集合map中已经存在key="a",value=3, 如果onlyIfAbsent=true,在添加key="a",value=5,那么key="a"对应的值不会被改变,还是3。我们经常使用的put方法,此参数的值是false,说明put方法可以覆盖已经存在的值。 evict:参数用于LinkedHashMap中的尾部操作,在HashMap中并没有用到这个参数
接下来我们分析putVal的源码。
第一步:判断是否初始化了底层数组。
if ((tab = table) == null || (n = tab. length ) == 0)
n = (tab = resize()).length;
putVal第一段代码就是上面的代码,它首先将tab=table(这个table就是所说的底层的数组)并判断是否为null,同时判断tab的长度是否为0,只要两者有一个成立,就会进入n=(tab=resize()).length这句代码。在 中我们分析了HashMap的构造方法,并没有一个构造方法对底层的数组进行初始化,所有的构造方法仅仅对加载因子或者扩容的阀门进行了初始化,底层数组初始化的工作放在了第一次调用put的时候,这个知识点大家一定要记住。因为这篇文章是介绍HashMap的put的,关于数组怎样进行初始化或者扩容的,我会有专门一篇文章详细讲解,这里就不再分精力阐述。只需记得put的第一步操作需要判断底层数组是否初始化了,如果没有初始化,就首先调用resize()进行初始化,如果已经初始化了,则继续执行下面的代码。通过这一步后,底层数组就变成了如下图示:

第二步:通过hash算出key应该在数组table的下标
if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); 1:(n-1)&hash:就是获取key应该在数组的下标 2:tab[(n-1)&hash]:就是获取此下标数组的值,然后赋值给p,而p是一个Node,如果p==null,说明此下标还没有任何的值,所以直接把新插入的元素放到此处。 3:tab[i] = newNode(hash, key, value, null):就是把新插入的key,value封装成Node节点,然后放到数组中。
例如,我们map.put(“a”,3)到HashMap中,通过计算应该放到下标为1的地方,如图所示

第三步:判断新插入的key和p.key是否相等
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; 1:其中p=tab[(n-1)&hash] 2:判断新插入的key,和通过key计算的下标对应的key是否相等。
例如,我们map.put(“a”,5)到HashMap中,通过计算应该放到下标1的地方,而此时p=(“a”,3),那么p.hash=hash,p.key=key,所以会执行这一步。如图所示:
第四步:第三步不符合,接下来判断p是否为红黑树,如果是红黑树,那么按照红黑树的方式插入
else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
我们继续进入putTreeVal方法中,看看到底做了什么。
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
//首先获取树的根节点。
TreeNode<K,V> root = (parent != null) ? root() : this;
说明:通过循环,查找新插入的key-value要插入红黑树的哪一个地方,我在分析红黑树
的时候说过,红黑树是一种二叉查找树,任何的左子树的值都比它的父节点的值小,任何的右子树的值都比它的父节点的值大。下面的循环查找就是基于二叉查找的特性来操作的。
其中dir判断要添加到左子树还是右子树。
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
//走到这一步:插入的key的hash值比比较的值小,需要向左子树查找
dir = -1;
else if (ph < h)
//走到这一步:插入的key的hash值比比较的值大,需要向右子树查找
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
//走到这一步:说明key所对应的hash值是相等的,所以需要比较key了,插入的key等于查找的key,说明二叉树上有对应的key,直接返回
return p;
//走到这一步:说明插入的key的hash值和比较的hash值相等,但是key不相等
comparableClassFor(k):判断key是否实现了Comparable接口,如果实现了,则返回它的Class对象,如果没有实现则返回null,这个方法有的同学看不懂,后面我会详细讲解这个方法,让大家彻底理解。如果key实现了Comparable接口,则会接着调compareComparables方法。
compareComparables(kc, k, pk):因为实现了Comparable接口,则通过compareTo方法判断。
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
//走到这一步:说明key没有实现Comparable接口或者实现了Comparable接口,但是通过compareTo方法仍无法比较
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p. right ) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
//走到这一步:已经可以知道是向树的左子树查找,还是向树的右子树查找了
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
//走到这一步:说明已经找到了要插入的位置,其中:
xp:表示要插入的新节点x的父节点。
1)首先把要插入的key-value封装成TreeNode的树的数据结构
2)通过dir判断要x节点是父节点xp的左子树还是右字数,dir<0:说明x是xp的左子树,dir>0:说明x是xp的右子树。
3)然后初始化x的next属性,parent属性,pre属性。
4)插入节点x后,此时的树不一定完全符合红黑树的5个特性,所以需要对树进行修复,通过调用balanceInsertion()方法对红黑树进行修复,后面会对balanceInsertion()方法进行详解,看看大家是否真正理解红黑树的修复了。
5)moveRootToFront方法就是确保修复后的根节点是数组下标的第一个节点。
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
上面我对红黑树的插入做了介绍,现在把欠的两个知识点说了。
第一个知识点:comparableClassFor方法,源码如下:
static Class<?> comparableClassFor(Object x) {
//首先就判断是否实现了Comparable接口,如果没有实现直接返回null
if (x instanceof Comparable) {
//走到这一步:说明key实现了Comparable接口。
1)ParameterizedType:代表的是Comparable接口 泛型 的类型,例如Comparable<String>,则代表是字符串。
Class<?> c; Type[] ts, as; Type t; ParameterizedType p;
if ((c = x.getClass()) == String.class) // bypass checks
//首先判断以下key是否为字符串,我们知道字符串String也实现了Comparable接口
return c;
if ((ts = c.getGenericInterfaces()) != null) {//获取key所实现的接口
for (int i = 0; i < ts.length; ++i) {
1)判断Comparable实现了泛型
2)判断泛型参数要实现Comparable接口
3)判断泛型要等于key的Class类。
if (((t = ts[i]) instanceof ParameterizedType) &&
((p = (ParameterizedType)t).getRawType() ==
Comparable.class) &&
(as = p.getActualTypeArguments()) != null &&
as.length == 1 && as[0] == c) // type arg is c
return c;
}
}
}
return null;
}
举例如下:
public class ComparableClassForTest{
public static void main(String[]args){
System.out.println(comparableClassFor(new A()));
System.out.println(comparableClassFor(new B()));
System.out.println(comparableClassFor(new C()));
System.out.println(comparableClassFor(new D()));
System.out.println(comparableClassFor(new F()));
}
}
class A{}
class B implements Comparable<String>{}
class C implements Comparable<C>{}
class D implements Comparable<C>{}
class F extends C{}
其中comparableClassFor和HashMap中的相同,省略,那么会出现什么结果呢
1:new A():返回null,因为A未实现Comparable接口
2:new B():返回null,因为泛型Object不是B
3:new C():返回C
4:new D():返回null,因为泛型Object不是B
5:new F():返回null,F是C的子类
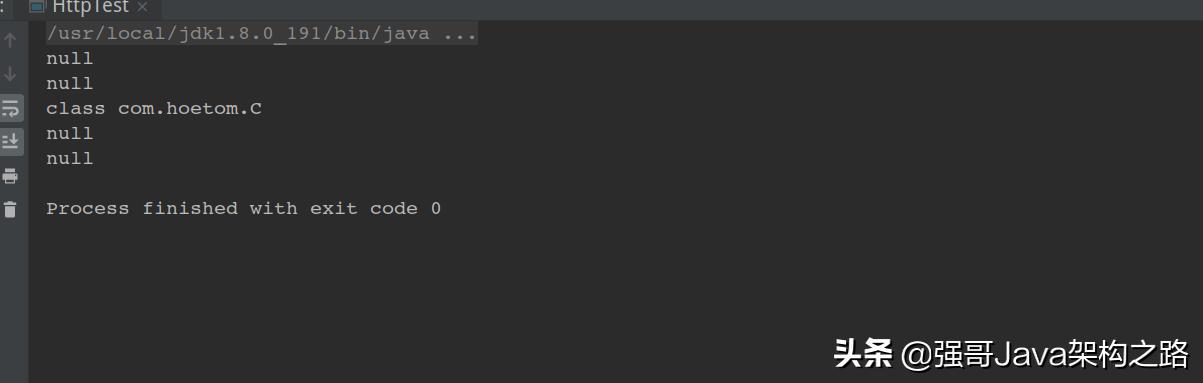
所以综上所属:要使comparableClassFor方法不返回null,必须满足如下:
1:key必须实现Comparable接口 2:Comparable<T>的泛型T.class==key.class
通过上面的学习,相信大家明白了comparableClassFor方法的作用了吧。
第二个知识点:红黑树的修复:balanceInsertion,通过我对红黑树的解析,下面的代码读起来就容易的多了,源码如下:
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
//默认插入红黑树的颜色为红色
x.red = true;
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
if ((xp = x.parent) == null) {
//走到这一步:说明插入x前是一颗空树,符合我们在红黑树这一篇文章所说的情景1,解决方法:只需要更改颜色即可
x.red = false;
return x;
}
else if (!xp.red || (xpp = xp.parent) == null)
//走到这一步:说明节点x的父节点xp的颜色为黑色,此时符合情景2:不违背红黑树的特性,不需要修复。
return root;
if (xp == (xppl = xpp.left)) {
//走到这一步:说明节点x的父节点和叔叔节点都存在,且都为红色,符合情景3:父节点xp和叔叔节点u都存在,且都为红色,解决方案:xp.red=false,u.red=false,xpp.red=true.
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
//走到这一步:说明符合情景4,通过左旋
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
else {
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
如果大家熟悉了红黑树的修复方法,上面的代码很容易读懂,如果不太熟悉,请观看 和 两篇文章
第五步:第三步和第四步都不符合,接下来判断此下标形成的链表结构是否存在此key,如果存在且onlyIfAbsent=false,则直接覆盖,如果不存在,则直接添加到链表
else {
//走到这一步:说明要查找链表了。
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//走到这一步:说明查询到链表的末尾了也没有找到符合的,所以需要新建一个Node,
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//走到这一步:表明链表的长度已经到了阀门,TREEIFY_THRESHOLD=8.为了查找性能,需要把链表转换成红黑树了,treeifyBin()方法就是干这件事的,稍后分析此方法。
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
//走到这一步:说明链表中存在此key,直接跳出循环
break;
//走到这一步:继续查找链表
p = e;
}
}
上面的代码总结如下:
1:从链表头结点开始查找,如果查找到了key则直接跳出循环 2:如果查找到链表的末尾都没有查找到,则将新插入的key-value封装成Node,放到链表的末尾。然后判断链表的长度是否到了红黑树的阀门,如果到了,就需要把链表变成红黑树。
下面我们来分析treeifyBin()方法的源码,如下:
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
//走到这一步:说明当链表长度达到阀门时,它并没有急于把链表直接转换成红黑树,
而是判断以下数组的长度是否小于MIN_TREEIFY_CAPACITY(值为64),如果小于,则进行扩容。
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
//走到这一步:说明就开始链表到红黑树的转化了。
1)首先从链表首部循环到链表尾部,把Node转换成TreeNode。
2)将转换的第一个TreeNode节点tl放到数组的index下标中。然后调用TreeNode的treeify方法将其转换成红黑树。treeify的代码非常的简单,请自行观看。
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
第六步:如果已存在key,则通过参数onlyIfAbsent判断是否覆盖老值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
第七步:判断是否扩容
++modCount; if (++size > threshold) resize();
本篇文章详细介绍了HashMap的put方法,总结如下:
1:首先判断数组是否被初始化,如果没有初始化则调用扩容的方法resize,进行初始化。 2:获取数组下标:index=(n-1)&hash,并赋值p=tab[(n-1)&hash] 3:如果p==null,则说明此下标index还没有任何的值,所以直接把key-value封装成Node放到数组中。 4:如果p!=null,说明此下标index已经有值了,要么是链表,要么是红黑树 4.1:如果是红黑树则直接调用putTreeVal方法,如果红黑树上已经存在key则直接覆盖,如果不存在key则把新节点插入到红黑树,并对红黑树进行修复 4.2:如果是链表,则进行循环链表,如果链表中已经存在key,则这接覆盖,如果不存在,则添加到链表的尾部,然后判断链表是否达到了转变红黑的阀门,如果到了,直接链表到红黑树的转变 4.3:从链表到红黑树的转变,HashMap中会首先判断数组的长度是否大于64,如果小于则调用resize()进行扩容,如果大于则进行链表到红黑树的转变。 5:通过上面的操作,如果HashMap中存在将要插入的key,通过参数onlyIfAbSent判断是否覆盖旧值,如果onlyIfAbSent=true则覆盖,否则则不覆盖 6:如果HashMap中不存在将要插入的key,则插入,插入后需要判断是否需要扩容,如果需要则调用resize()方法进行扩容。
HashMap的put方法就总结完了,下一篇文章,我会用图解实例方法为大家实际操作以下put的流程。对于扩容,我会在下下一篇文章详细分析,请持续关注。


