概述
JAVA中的数组,在添加或者删除元素的时候,都会复制一个新数组,比较耗内存。但是数组的遍历则是非常高效的。链表则是相反,遍历慢( 需要遍历数组,一直找到值相等的元素才算找到 ),而添加和删除元素代价低。
有没有办法结合两者的特点,做到寻找元素快,插入元素或者删除元素代价低呢?答案是利用 哈利表 。
hash Map put操作
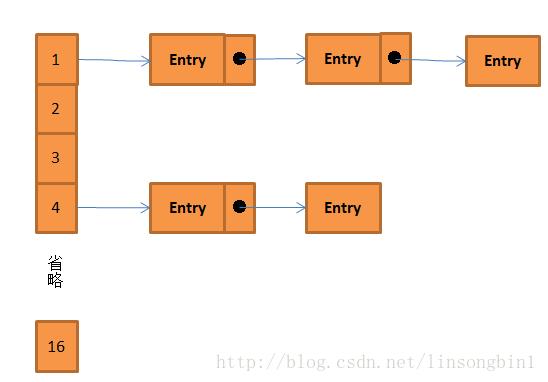
当使用HashMap的put方法的时候,有两个问题要解决:
1、长度为16的数组中,元素存储在哪个位置
2、如果key出现hash冲突,如何解决
第一个问题 ,HashMap 是使用下面的算法来计算元素的存放位置的。
int hash = hash(key); int i = indexFor(hash, table.length);
首先先hash,之后结合数组的长度进行一个 & 操作得到得到数组的下标。
第二个问题 则利用Entry类的 next 变量来实现链表,把最新的元素放到链表头,旧的数据则被最新的元素的next变量引用着。
举个例子,假设元素Entry<“1″,”1”>通过hash算法算出存到下标为0的位置上,后面又添加一个Entry<“2″,”2”>,
假设Entry<“2″,”2”>通过hash算法算出也需要存到下标为0的数组中,那么此时链表是下面这个样子的:
也即是说,当key出现hash冲突的时候, 链表中的第一个元素都是后面最新添加进来的那个,之前的则被next变量引用着 。虽然这里是插入的动作,但是由于使用了链表,所以无需像数组的插入那样,进行数组拷贝。
HashMap get操作
这个操作的原理就比较简单,只需要根据key的 hashcode 算出元素在数组中的下标,之后遍历Entry对象链表,直到找到元素为止。
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
这里有两个注意点:
1、这里利用key的hashcode方法和equals方法,所以在使用HashMap的时候,如果使用对象作为key,最好覆写key的hashcode和equals方法
不然可能出put到HashMap的时候,成功了,但是get的时候却没有找到数据
2、如果key hash冲突太多,会造成链表过长,在链表中查找元素的时候,会比较慢
hash冲突后优化方案
如果出现了大量hash冲突,那么遍历链表的时候,会比较慢。JDK 1.8里面,当链表的长度大于 阀值 (默认为8)的时候,会使用 红黑树 来存储数据,以便加快key的查询速度。
总结
HashMap使用了 数组+链表 的方案,做到了读取快,插入快的目的,但是HashMap还是一些使用上的问题的:
1、线程不安全
2、当容量不够时,会进行rehash的流程,非常耗资源
如果大家喜欢这篇文章的话,希望大家能够收藏,转发 谢谢!更多相关资讯可以关注西安华美校区,免费获得java零基础教程!额外附送excel教程!


