一、日志采集方案


大致一下分为三种方案来做日志采集:
- 在节点上运行一个 agent 来收集日志
- 在 Pod 中包含一个 sidecar 容器来收集应用日志
- 直接在应用程序中将日志信息推送到采集后端
因为方案一在业界使用更为广泛,所以下面基于方案一来做k8s的日志采集。
二、架构选型
存储层: Elasticsearch 是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。
展示层:Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 允许你通过 web 界面来浏览 Elasticsearch 日志数据。
缓存层: 需要收集大数据量的日志一般使用Redis、kafka做为中间缓存层来缓冲数据。
采集层:
- Fluentd:是一个流行的开源数据收集器, 具有众多插件,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
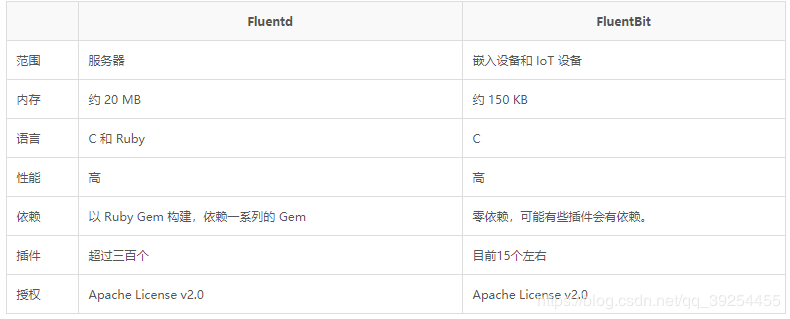
Fluentd-bit: 更适用于嵌入设备等资源受限的场景。占用系统资源较少,在插件可以满足需求的同时,无疑是更好的选择。另外Fluent Bit 提供了输出插件,可以把数据发给 Fluentd,因此他们可以在系统中作为独立服务互相协作。对比如下
 在这里插入图片描述
在这里插入图片描述- Logstash:ES官方推荐,使用它有很多插件,灵活性很高,但由于是java语言编写,占用资源较高,一般作为过滤格式使用,当然也可以单独使用。
- Filebeat: ES官方新一代采集工具,是一个轻量级的日志传输工具,使用Golang语言编写,占用资源低,一般作为采集日志使用,当然也可以单独使用,同样它和Logstash可以互相协作。

详见:详解日志采集工具–Logstash、Filebeat、Fluentd、Logagent对比
相关架构图如下:


本文所使用架构
Fluentd(采集),Elasticsearch (存储),kibana(展示)
三、部署Elasticsearch 集群
使用3个 Elasticsearch Pod 来避免高可用下多节点集群中出现的“脑裂”问题
创建一个名为 logging 的 namespace
$ kubectl create namespace logging1. 创建无头服务
编写elasticsearch-svc.yaml
kind: ServiceapiVersion: v1metadata: name: elasticsearch namespace: logging labels: app: elasticsearchspec: selector: app: elasticsearch clusterIP: None ports: - port: 9200 name: rest - port: 9300 name: inter-node创建服务资源对象
$ kubectl create -f elasticsearch-svc.yaml$ kubectl get svc -n loggingNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEelasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 13d2. 部署StorageClass持久化存储
集群使用NFS 作为后端存储资源,在主节点安装NFS,共享/data/k8s/目录。
$ systemctl stop firewalld.service$ yum -y install nfs-utils rpcbind$ mkdir -p /data/k8s$ chmod 755 /data/k8s$ vim /etc/exports/data/k8s *(rw,sync,no_root_squash)$ systemctl start rpcbind.service$ systemctl start nfs.service创建nfs-client 的自动配置程序Provisioner, nfs-client.yaml
kind: DeploymentapiVersion: extensions/v1beta1metadata: name: nfs-client-provisionerspec: replicas: 1 strategy: type: Recreate template: metadata: labels: app: nfs-client-provisioner spec: serviceAccountName: nfs-client-provisioner containers: - name: nfs-client-provisioner image: quay.io/external_storage/nfs-client-provisioner:latest volumeMounts: - name: nfs-client-root mountPath: /persistentvolumes env: - name: PROVISIONER_NAME value: fuseim.pri/ifs - name: NFS_SERVER value: 172.16.1.100 - name: NFS_PATH value: /data/k8s volumes: - name: nfs-client-root nfs: server: 172.16.1.100 path: /data/k8s创建ServiceAccount,然后绑定集群对应的操作权限:nfs-client-sa.yaml
apiVersion: v1kind: ServiceAccountmetadata: name: nfs-client-provisioner---kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1metadata: name: nfs-client-provisioner-runnerrules: - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["list", "watch", "create", "update", "patch"] - apiGroups: [""] resources: ["endpoints"] verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]---kind: ClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1metadata: name: run-nfs-client-provisionersubjects: - kind: ServiceAccount name: nfs-client-provisioner namespace: defaultroleRef: kind: ClusterRole name: nfs-client-provisioner-runner apiGroup: rbac.authorization.k8s.io创建StorageClass,elasticsearch-storageclass.yaml
apiVersion: storage.k8s.io/v1kind: StorageClassmetadata: name: es-data-dbprovisioner: fuseim.pri/ifs部署服务资源对象
$ kubectl create -f nfs-client.yaml$ kubectl create -f nfs-client-sa.yaml$ kubectl create -f elasticsearch-storageclass.yaml $ kubectl get pods NAME READY STATUS RESTARTS AGEnfs-client-provisioner-5b486d9c65-9fzjz 1/1 Running 9 13d$ kubectl get storageclassNAME PROVISIONER AGEes-data-db fuseim.pri/ifs 13d3. 使用StatefulSet 创建Es Pod
Elasticsearch 需要稳定的存储来保证 Pod 在重新调度或者重启后的数据依然不变,所以我们需要使用 StatefulSet 控制器来管理 Pod。
编写elasticsearch-statefulset.yaml
apiVersion: apps/v1kind: StatefulSet metadata: name: es #定义了名为 es 的 StatefulSet 对象 namespace: loggingspec: serviceName: elasticsearch #和前面创建的 Service 相关联,这可以确保使用以下 DNS 地址访问 StatefulSet 中的每一个 Pod:es-[0,1,2].elasticsearch.logging.svc.cluster.local,其中[0,1,2]对应于已分配的 Pod 序号。 replicas: 3 #3个副本 selector: #设置匹配标签为app=elasticsearch matchLabels: app: elasticsearch template: #定义Pod模板 metadata: labels: app: elasticsearch spec: initContainers: #初始化容器,在主容器执行前运行 - name: increase-vm-max-map #第一个Init容器用来增加操作系统对mmap计数的限制 image: busybox command: ["sysctl", "-w", "vm.max_map_count=262144"] securityContext: privileged: true - name: increase-fd-ulimit #第二个Init容器用来执行ulimit命令,增加打开文件描述符的最大数量 image: busybox command: ["sh", "-c", "ulimit -n 65536"] securityContext: privileged: true containers: - name: elasticsearch image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2 ports: - name: rest containerPort: 9200 - name: inter containerPort: 9300 resources: limits: cpu: 1000m requests: cpu: 1000m volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data env: #声明变量 - name: cluster.name # #Elasticsearch 集群的名称 value: k8s-logs - name: node.name #节点的名称, valueFrom: fieldRef: fieldPath: metadata.name - name: cluster.initial_master_nodes value: "es-0,es-1,es-2" - name: discovery.zen.minimum_master_nodes #将其设置为(N/2) + 1,N是我们的群集中符合主节点的节点的数量。我们有3个 Elasticsearch 节点,因此我们将此值设置为2(向下舍入到最接近的整数)。 value: "2" - name: discovery.seed_hosts #设置在 Elasticsearch 集群中节点相互连接的发现方法。 value: "elasticsearch" - name: ES_JAVA_OPTS #设置为-Xms512m -Xmx512m,告诉JVM使用512 MB的最小和最大堆。您应该根据群集的资源可用性和需求调整这些参数。 value: "-Xms512m -Xmx512m" - name: network.host value: "0.0.0.0" volumeClaimTemplates: #持久化模板 - metadata: name: data labels: app: elasticsearch spec: accessModes: [ "ReadWriteOnce" ] #只能被 mount 到单个节点上进行读写 storageClassName: es-data-db resources: requests: storage: 100Gi创建服务资源对象
$ kubectl create -f elasticsearch-statefulset.yamlstatefulset.apps/es-cluster created$ kubectl get pods -n loggingNAME READY STATUS RESTARTS AGEes-cluster-0 1/1 Running 0 20hes-cluster-1 1/1 Running 0 20hes-cluster-2 1/1 Running 0 20h验证ES服务是否正常
将本地端口9200转发到 Elasticsearch 节点(如es-cluster-0)对应的端口:
$ kubectl port-forward es-cluster-0 9200:9200 --namespace=loggingForwarding from 127.0.0.1:9200 -> 9200Forwarding from [::1]:9200 -> 9200打开另一个终端请求es,出现以下内容则为部署成功。
$ curl http://localhost:9200/_cluster/state?pretty{ "cluster_name" : "k8s-logs", "cluster_uuid" : "z9Hz1q9OS0G6GQBlWkOjuA", "version" : 19, "state_uuid" : "fjeJfNjjRkmFnX_1x_kzpg", "master_node" : "zcRrv4jnTfKFWGGdORpZKg", "blocks" : { }, "nodes" : { "cqZH5iFOTYCKkNHiZK6uoQ" : { "name" : "es-0", "ephemeral_id" : "l3VAgaBYSLeY0wA9_CdWkw", "transport_address" : "192.168.85.195:9300", "attributes" : { "ml.machine_memory" : "8202764288", "ml.max_open_jobs" : "20", "xpack.installed" : "true" } }, "zcRrv4jnTfKFWGGdORpZKg" : { "name" : "es-1", "ephemeral_id" : "LrD2UIReRfuIlGEArmwYuw", "transport_address" : "192.168.148.77:9300", "attributes" : { "ml.machine_memory" : "14543122432-------四、部署Kibana服务
Kibana作为前端展示层应用,不需要存储大量数据,所以我们使用Deployment控制器来管理Kibana的Pod。
编写 kibana.yaml
apiVersion: v1kind: Servicemetadata: name: kibana namespace: logging labels: app: kibanaspec: ports: - port: 5601 type: NodePort selector: app: kibana---apiVersion: apps/v1kind: Deploymentmetadata: name: kibana namespace: logging labels: app: kibanaspec: selector: matchLabels: app: kibana template: metadata: labels: app: kibana spec: containers: - name: kibana image: docker.elastic.co/kibana/kibana:7.6.2 resources: limits: cpu: 1000m requests: cpu: 1000m env: - name: ELASTICSEARCH_HOSTS value: http://elasticsearch:9200 ports: - containerPort: 5601使用 kubectl 工具创建:
$ kubectl create -f kibana.yamlservice/kibana createddeployment.apps/kibana created$ kubectl get pods --namespace=loggingNAME READY STATUS RESTARTS AGEes-0 1/1 Running 0 42hes-1 1/1 Running 1 42hes-2 1/1 Running 0 42hkibana-945bc5c69-gkb58 1/1 Running 1 16h$ kubectl get svc --namespace=loggingNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEelasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 42hkibana NodePort 10.97.4.21 <none> 5601:32230/TCP 16h在浏览器中访问:http://<任意节点IP>:32230

五、部署Fluentd采集插件
由于我们使用的采集方案,只需要在每台节点上部署一个采集器即可,对资源没有过大的消耗,所以选择对插件支持更多,使用更加广泛的Fluentd 来作为日志收集工具。下面我们使用DasemonSet 控制器来部署 Fluentd 应用,以确保在集群中的每个节点上始终运行一个 Fluentd 收集容器。
1. 编写fluentd的ConfigMap文件
编写Fluentd的配置文件:fluentd-configmap.yaml
kind: ConfigMapapiVersion: v1metadata: name: fluentd-config namespace: loggingdata: system.conf: |- <system> root_dir /tmp/fluentd-buffers/ </system> containers.input.conf: |- # 日志源配置 <source> @id fluentd-containers.log # 日志源唯一标识符,后面可以使用该标识符进一步处理 @type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。 path /var/log/containers/*.log # 挂载的服务器Docker容器日志地址 pos_file /var/log/es-containers.log.pos # 检查点 Fluentd重启后会从该文件中的位置恢复日志采集 tag raw.kubernetes.* # 设置日志标签 read_from_head true <parse> # 多行格式化成JSON @type multi_format # 使用 multi-format-parser 解析器插件 <pattern> format json # JSON解析器 time_key time # 指定事件时间的时间字段 time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式 </pattern> <pattern> format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/ time_format %Y-%m-%dT%H:%M:%S.%N%:z </pattern> </parse> </source> <match raw.kubernetes.**> # 匹配tag为raw.kubernetes.**日志信息 @id raw.kubernetes @type detect_exceptions # 使用detect-exceptions插件处理异常栈信息 remove_tag_prefix raw # 移除 raw 前缀 message log stream stream multiline_flush_interval 5 max_bytes 500000 max_lines 1000 </match> <filter **> # 拼接日志 @id filter_concat @type concat # Fluentd Filter 插件,用于连接多个事件中分隔的多行日志。 key message multiline_end_regexp /\n$/ # 以换行符“\n”拼接 separator "" </filter> <filter kubernetes.**> # 添加 Kubernetes metadata 数据 @id filter_kubernetes_metadata @type kubernetes_metadata </filter> <filter kubernetes.**> # 修复ES中的JSON字段 @id filter_parser @type parser # multi-format-parser多格式解析器插件 key_name log # 在要解析的记录中指定字段名称。 reserve_data true # 在解析结果中保留原始键值对。 remove_key_name_field true # key_name 解析成功后删除字段。 <parse> @type multi_format <pattern> format json </pattern> <pattern> format none </pattern> </parse> </filter> <filter kubernetes.**> # 删除一些多余的属性 @type record_transformer remove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash </filter> <filter kubernetes.**> # 只采集具有logging=true标签的Pod日志 @id filter_log @type grep <regexp> key $.kubernetes.labels.logging pattern ^true$ </regexp> </filter> forward.input.conf: |- # 监听配置,一般用于日志聚合用 <source> @id forward @type forward </source> output.conf: |- # 路由配置,将处理后的日志数据发送到ES <match **> # 标识一个目标标签,后面是一个匹配日志源的正则表达式,我们这里想要捕获所有的日志并将它们发送给 Elasticsearch,所以需要配置成** @id elasticsearch # 目标的一个唯一标识符 @type elasticsearch # 支持的输出插件标识符,输出到 Elasticsearch @log_level info # 指定要捕获的日志级别,我们这里配置成 info,表示任何该级别或者该级别以上(INFO、WARNING、ERROR)的日志都将被路由到 Elsasticsearch。 include_tag_key true host elasticsearch # 定义 Elasticsearch 的地址 port 9200 logstash_format true # Fluentd 将会以 logstash 格式来转发结构化的日志数据 logstash_prefix k8s # 设置 index 前缀为 k8s request_timeout 30s <buffer> # Fluentd 允许在目标不可用时进行缓存 @type file path /var/log/fluentd-buffers/kubernetes.system.buffer flush_mode interval retry_type exponential_backoff flush_thread_count 2 flush_interval 5s retry_forever retry_max_interval 30 chunk_limit_size 2M queue_limit_length 8 overflow_action block </buffer> </match>在上面的文件中我们首先定义了日志源,然后经过滤和组装获得我们需要的格式,最后将数据输出到Elasticsearch集群中。
2. 使用Daemonset部署Fluentd Pod
新建一个 fluentd-daemonset.yaml
apiVersion: v1kind: ServiceAccountmetadata: name: fluentd-es namespace: logging labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile---kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcilerules:- apiGroups: - "" resources: - "namespaces" - "pods" verbs: - "get" - "watch" - "list"---kind: ClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcilesubjects:- kind: ServiceAccount name: fluentd-es namespace: logging apiGroup: ""roleRef: kind: ClusterRole name: fluentd-es apiGroup: ""---apiVersion: apps/v1kind: DaemonSetmetadata: name: fluentd-es namespace: logging labels: k8s-app: fluentd-es version: v2.0.4 kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcilespec: selector: matchLabels: k8s-app: fluentd-es version: v2.0.4 template: metadata: labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" version: v2.0.4 annotations: scheduler.alpha.kubernetes.io/critical-pod: '' spec: serviceAccountName: fluentd-es containers: - name: fluentd-es image: cnych/fluentd-elasticsearch:v2.0.4 env: - name: FLUENTD_ARGS value: --no-supervisor -q resources: limits: memory: 500Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: config-volume mountPath: /etc/fluent/config.d nodeSelector: #节点选择 beta.kubernetes.io/fluentd-ds-ready: "true" #节点需有这个标签才会部署收集 tolerations: #添加容忍 - key: node-role.kubernetes.io/master operator: Exists effect: NoSchedule terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: config-volume configMap: name: fluentd-config刚才我们使用ConfigMap对象编写的Fluentd的配置文件,也已经通过volumes 挂载到了Fluentd 容器中。我们也可以通过给节点打标签的方式,灵活控制哪些节点的日志可以被收集。在上面文件中我们定义了nodeSelector字段,来收集集群中含有这个beta.kubernetes.io/fluentd-ds-ready: "true"标签的节点日志。
为需要收集日志的节点添加标签
$ kubectl label nodes k8s-node01 beta.kubernetes.io/fluentd-ds-ready=true$ kubectl label nodes kubesphere beta.kubernetes.io/fluentd-ds-ready=true$ kubectl get nodes --show-labelsNAME STATUS ROLES AGE VERSION LABELSk8s-node01 Ready <none> 200d v1.15.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/fluentd-ds-ready=true,beta.kubernetes.io/os=linux,es=log,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linuxkubesphere Ready master 203d v1.15.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/fluentd-ds-ready=true,beta.kubernetes.io/os=linux,es=log,kubernetes.io/arch=amd64,kubernetes.io/hostname=kubesphere,kubernetes.io/os=linux,node-role.kubernetes.io/master=部署资源对象
$ kubectl create -f fluentd-configmap.yamlconfigmap "fluentd-config" created$ kubectl create -f fluentd-daemonset.yamlserviceaccount "fluentd-es" createdclusterrole.rbac.authorization.k8s.io "fluentd-es" createdclusterrolebinding.rbac.authorization.k8s.io "fluentd-es" createddaemonset.apps "fluentd-es" created$ kubectl get pods -n loggingNAME READY STATUS RESTARTS AGEes-0 1/1 Running 1 2des-1 1/1 Running 1 2des-2 1/1 Running 1 2dfluentd-es-7rf2v 1/1 Running 0 82mfluentd-es-bm974 1/1 Running 0 82mkibana-5b7f674fd8-z6k6h 1/1 Running 1 3h59m$ kubectl get svc -n loggingNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEelasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 18dkibana NodePort 10.111.51.138 <none> 5601:31284/TCP 18d3. 测试应用日志收集
在上面Fluentd的配置文件中,我们指定了只收集具有logging=true标签的Pod日志, 现在我们部署一个简单的测试应用, 新建 dummylogs.yaml文件
apiVersion: apps/v1kind: Deploymentmetadata: name: dummylogsspec: replicas: 3 selector: matchLabels: app: dummylogs template: metadata: labels: app: dummylogs logging: "true" # 要采集日志需要加上该标签 spec: containers: - name: dummy image: cnych/dummylogs:latest args: - msg-processor---apiVersion: apps/v1kind: Deploymentmetadata: name: dummylogs2spec: replicas: 3 selector: matchLabels: app: dummylogs2 template: metadata: labels: app: dummylogs2 logging: "true" # 要采集日志需要加上该标签 spec: containers: - name: dummy image: cnych/dummylogs:latest args: - msg-receiver-api使用 kubectl 工具创建该 Pod:
$ kubectl create -f dummylogs.yaml$ kubectl get pod NAME READY STATUS RESTARTS AGEdummylogs-59677dd44d-44z9c 1/1 Running 21 2d8hdummylogs-59677dd44d-s64rj 1/1 Running 19 2d8hdummylogs2-67498f8b6d-dgz7c 1/1 Running 21 2d8hdummylogs2-67498f8b6d-v6db5 1/1 Running 18 2d8h$ kubectl logs -f dummylogs-59677dd44d-44z9c{"LOGLEVEL":"INFO","serviceName":"msg-processor","serviceEnvironment":"staging","message":"Information event from service msg-processor staging - events received and processed.","eventsNumber":25}{"LOGLEVEL":"INFO","serviceName":"msg-processor","serviceEnvironment":"staging","message":"Information event from service msg-processor staging - events received and processed.","eventsNumber":49}这个 Pod将日志信息打印到 stdout,所以正常来说 Fluentd 会收集到这个日志数据,在 Kibana 中也就可以找到对应的日志数据了,现在我们到kibana上去添加这个索引。

可以使用过滤器筛选一些日志进行分析

六、实现基于日志的报警
在应用层面我们可以使用 Promethus 对应用的各项指标进行监控,但是在业务层面,应用的日志中也会产生一些错误日志,影响业务的正常运行,所以我们还需要对错误日志进行监控报警,可以使用 elastalert 组件来完成这个工作。
ElastAlert支持以下方式报警:
- Command
- JIRA
- OpsGenie
- SNS
- HipChat
- Slack
- Telegram
- Debug
- Stomp
下面我们使用邮件方式报警,编写资源文件elastalert.yaml
apiVersion: v1kind: ConfigMapmetadata: name: elastalert-config namespace: logging labels: app: elastalertdata: elastalert_config: |- # elastalert配置文件 --- rules_folder: /opt/rules # 指定规则的目录 scan_subdirectories: false run_every: # 多久从 ES 中查询一次 minutes: 1 buffer_time: minutes: 15 es_host: elasticsearch es_port: 9200 writeback_index: elastalert use_ssl: False verify_certs: True alert_time_limit: # 失败重试限制 minutes: 2880---apiVersion: v1kind: ConfigMapmetadata: name: elastalert-rules namespace: logging labels: app: elastalertdata: rule_config.yaml: |- # elastalert规则文件 name: dummylogs error # 规则名字,唯一值 es_host: elasticsearch es_port: 9200 type: any # 报警类型 index: k8s-* # es索引 filter: # 过滤 - query: query_string: query: "LOGLEVEL:ERROR" # 报警条件 alert: # 报警类型 - "email" smtp_host: smtp.qq.com smtp_port: 587 smtp_auth_file: /opt/auth/smtp_auth_file.yaml email_reply_to: 123456789@qq.com #发送邮箱 from_addr: 123456789qq.com email: # 接受邮箱 - "xxxxx@163.com"---apiVersion: apps/v1kind: Deploymentmetadata: name: elastalert namespace: logging labels: app: elastalertspec: selector: matchLabels: app: elastalert template: metadata: labels: app: elastalert spec: containers: - name: elastalert image: jertel/elastalert-docker:0.2.4 imagePullPolicy: IfNotPresent volumeMounts: - name: config mountPath: /opt/config - name: rules mountPath: /opt/rules - name: auth mountPath: /opt/auth resources: limits: cpu: 50m memory: 256Mi requests: cpu: 50m memory: 256Mi volumes: - name: auth secret: secretName: smtp-auth - name: rules configMap: name: elastalert-rules - name: config configMap: name: elastalert-config items: - key: elastalert_config path: elastalert_config.yaml使用邮件进行报警的时候,需要指定一个smtp_auth_file 的文件,文件中包含用户名和密码:(smtp_auth_file.yaml)
user: "xxxxx@qq.com" # 发送的邮箱地址password: "exawdasqq12" # 不是qq邮箱的登录密码,是授权码然后使用上面的文件创建一个对应的 Secret 资源对象:
$ kubectl create secret generic smtp-auth --from-file=smtp_auth_file.yaml -n logging创建资源对象
$ kubectl apply -f elastalert.yaml$ kubectl get pods -n logging -l app=elastalertNAME READY STATUS RESTARTS AGEelastalert-ff5f7c9c-4948j 1/1 Running 0 9m17s$ kubectl logs -f elastalert-ff5f7c9c-4948j -n loggingElastic Version: 7.6.2Reading Elastic 6 index mappings:Reading index mapping 'es_mappings/6/silence.json'Reading index mapping 'es_mappings/6/elastalert_status.json'Reading index mapping 'es_mappings/6/elastalert.json'Reading index mapping 'es_mappings/6/past_elastalert.json'Reading index mapping 'es_mappings/6/elastalert_error.json'Index elastalert already exists. Skipping index creation.我们的示例应用会隔一段时间就产生 ERROR 级别的错误日志,所以正常情况下我们就可以收到如下所示的邮件信息了:

上篇文章:k8s七 | 服务守护进程DaemonSet
系列文章:深入理解Kuerneters
参考资料:从Docker到Kubernetes进阶-阳明
关注公众号回复【k8s】关键词获取视频教程及更多资料:

给这篇文章的作者打赏
文章来源:智云一二三科技
文章标题:k8s八 | 基于EFK实现日志管理与日志报警
文章地址:https://www.zhihuclub.com/376.shtml


