
其实当你了解了这两个编码方式后,你就会知道 GBK 是中国标准,UTF8是网络传输标准, Unicode 是全球标准。
我们首先介绍下GBK:(GBK的发展史)
那么我们不得不提的是区位码:
其中前两位为“区”,后两位为“位”,中文汉字的编号区号是从16开始的,位号从1开始。前面的区号有一些符号、数字、字母、注音符号(台)、 制表符 、日文等等。简单来说就是0~1599表示的是除汉字之外的字符编号。1600~9999其中部分代表汉字编号,当然当时的汉字数量应该没有占用完所有的编号。
接下来发展到GB2312:
是基于区位码的,用双字节编码表示中文和中文符号。一般编码方式是: 0xA0+区号,0xA0+位号 。如下表中的 “安”,区位号是1618(十进制),那么“安”字的GB2312 编码 就是 0xA0+16 0xA0+18 也就是 0xB0 0xB2 。根据区位码表,GB2312的汉字编码范围是0xB0A1~0xF7FE
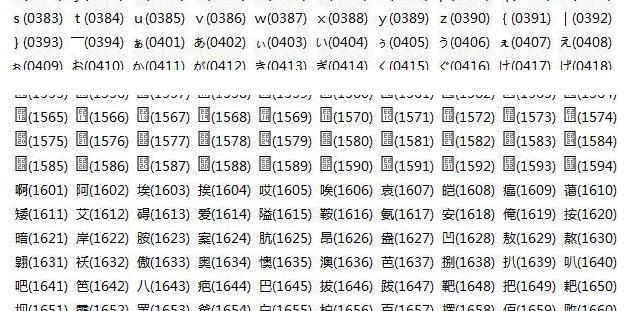
以ASCII编码,也就是说现代的GBK编码是兼容ASCII编码的。比如一个数字2,对应的 二进制 是0x32,而不是 0xA3 0xB2。那么问题来了,0xA3 0xB2 又对应到什么呢?还是2。注意看了,这里的2跟2是不是有点不太一样?!确实是不一样的。这里的 双字节2是 全角 的二, ASCII 的2是半角的二 ,一般输入法里的切换全角半角就是这里不同。

那么其实GBK就是对GB2312的补充,当然以后GB18030是对GBK的补充
同一个编码文件里,怎么区分ASCII和中文编码呢?从ASCII表我们知道标准ASCII只有128个字符,0~127即0x00~0x7F(0111 1111)。所以区分的方法就是,高字节的最高位为0则为ASCII,为1则为中文。
现在我们国家的GBK介绍完了,看下来是不是有点豁然开朗的感觉!其实就是一种一一对应汉字的编号方式,嘿嘿!
那么我们接下来看看全球是怎么编码的呢?其实也是类似,只是这是不只有汉字,有全世界各个国家的字符了。
现行的Unicode编码标准里,绝大多数程序语言只支持双字节,所以Unicode也就是双字节的标准表示全球所有的字符(可以包括65536中字符),
为英文字符也全部使用双字节,存储成本和流量会大大地增加,所以Unicode编码大多数情况并没有被原始地使用,而是被转换编码成UTF8, 这才出现了UTF8.
而Unicode与UTF8之间的转换是通过下面这个表格进行的:
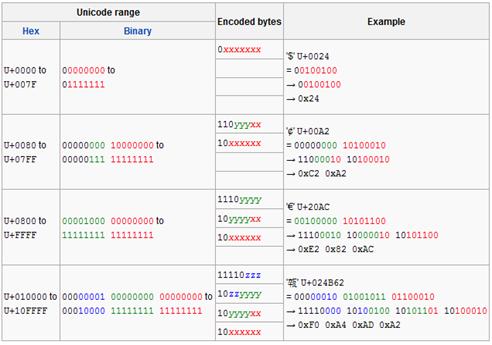
现在还有最后一个问题就是BOM,何为BOM?
所谓BOM头(Byte Order Mark)就是文本文件中开始的几个并不表示任何字符的字节,用二进制编辑器(如bz.exe)就能看到了。
UTF8的BOM头为 0xEF 0xBB 0xBF
Unicode大端模式为 0xFE 0xFF
Unicode小端模式为 0xFF 0xFE
如何区分一个文本是无BOM的UTF8还是GBK?
答案是,只能按大量的编码分析来区分。目前识别准确率很高的有: Notepad++ 等一些常用的IDE,PHP的mb_系列函数,python的chardet库及其它语言衍生版如jchardet,jschardet等



