Swoole 简介
Swoole:面向生产环境的 PHP 异步网络通信引擎
Swoole协程简介
笔者会持续分享架构设计,编程语言理论,面试题分享,互联网轶事等领域优质文章,对这些感兴趣欢迎关注笔者,没有错。
Swoole4为PHP语言提供了强大的CSP协程编程模式,用户可以通过go函数创建一个协程,以达到并发执行的效果,如下面代码所示:
<?php
//Co::sleep()是Swoole提供的API,并不会阻塞当前进程,只会阻塞协程触发协程切换。
go(function (){
Co::sleep(1);
echo “a”;
});
go(function (){
Co::sleep(2);
echo “b”;
});
echo “c”;
//输出结果:cab
//程序总执行时间2秒
其实在Swoole4之前就实现了多协程编程模式,在协程创建、切换以及结束的时候,相应的操作php栈即可(创建、切换以及回收php栈)。
此时的协程实现无法完美的支持php语法,其根本原因在于没有保存c栈信息。(vm内部或者某些扩展提供的API是通过c函数实现的,调用这些函数时如果发生协程切换,c栈该如何处理?)
Swoole4新增了c栈的管理,在协程创建、切换以及结束的同时会伴随着c栈的创建、切换以及回收。
Swoole4协程实现方案如下图所示:
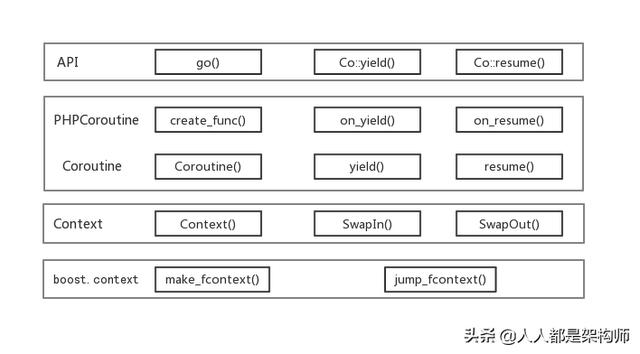
其中:
- API层是提供给用户使用的协程相关函数,比如go()函数用于创建协程;Co::yield()使得当前协程让出CPU;Co::resume()可恢复某个协程执行;
- Swoole4协程需要同时管理c栈与php栈,Coroutine用于管理c栈,PHPCoroutine用于管理php栈;其中Coroutine(),yield(),resume()实现了c栈的创建以及换入换出;create_func(),on_yield(),on_resume()实现了php栈的创建以及换入换出;
- Swoole4在管理c栈时,用到了 boost.context库,make_fcontext()和jump_fcontext()函数均使用汇编语言编写,实现了c栈上下文的创建以及切换;
- Swoole4对boost.context进行了简单封装,即Context层,Context(),SwapIn()以及SwapOut()
对应c栈的创建以及换入换出。
深入理解C栈
函数是对代码的封装,对外暴露的只是一组指定的参数和一个可选的返回值;假设函数P调用函数Q,Q执行后返回函数P,实现该函数调用需要考虑以下三点:
- 指令跳转:进入函数Q的时候, 程序计数器 必须被设置为Q的代码的起始地址;在返回时,程序计数器需要设置为P中调用Q后面那条指令的地址;
- 数据传递:P能够向Q提供一个或多个参数,Q能够向P返回一个值;
- 内存分配与释放:Q开始执行时,可能需要为局部变量分配内存空间,而在返回前,又需要释放这些内存空间;
大多数语言的函数调用都采用了栈结构实现,函数的调用与返回即对应的是一系列的入栈与出栈操作,我们通常称之为函数栈帧(stack frame)。示意图如下:
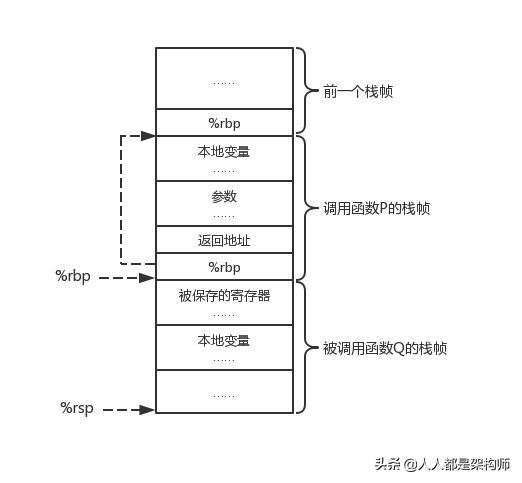
上面提到的程序计数器即寄存器%rip,另外还有两个寄存器需要重点关注:%rbp指向栈帧底部,%rsp指向栈帧顶部。
下面将通过具体的代码事例,为读者讲解函数栈帧。c代码与汇编代码如下:
int add(int x, int y)
{
int a, b;
a = 10;
b = 5;
return x+y;
}
int main()
{
int sum = add(1,2);
}
main:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp
movl $2, %esi
movl $1, %edi
call add
movl %eax, -4(%rbp)
leave
ret
add:
pushq %rbp
movq %rsp, %rbp
movl %edi, -20(%rbp)
movl %esi, -24(%rbp)
movl $10, -4(%rbp)
movl $5, -8(%rbp)
movl -24(%rbp), %eax
movl -20(%rbp), %edx
addl %edx, %eax
popq %rbp
ret
分析汇编代码:
- main函数与add函数入口,首先将寄存器%rbp压入栈中用于保存其值,其次移动%rbp指向当前栈顶部(此时%rbp,%rsp都指向栈顶,开始新的函数栈帧);
- main函数”subq $16, %rsp”,是为main函数栈帧预留16个字节的内存空间;
- 调用add函数时,第一个参数和第二个参数分别保存在寄存器%edi和%esi,返回值保存在寄存器%eax;
- call指令用于函数调用,实现了两个功能:寄存器%rip压入栈中,跳转到新的代码位置;
- ret指令用于函数返回,弹出栈顶内容到寄存器%rip,依次实现代码跳转;
- leave指令等同于两条指令:movq %rsp,%rbp和popq %rbp,用于释放main函数栈帧,恢复前一个函数栈帧;
- 注意add函数栈帧,并没有为其分配空间,寄存器%rsp和%rbp都指向栈帧底部;根本因为是add函数没有调用其他函数。
- 该程序的栈结构示意图如下:
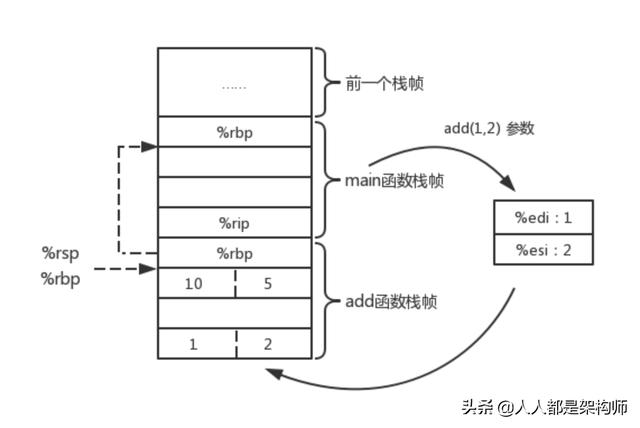
问题:观察上面的汇编代码,输入参数分别使用的是寄存器%edi和%esi,返回值使用的是寄存器%eax,输入输出参数不应该保存在栈上吗?寄存器比内存访问要快的多,现代处理器寄存器数目也比较多,因此倾向于将参数优先保存在寄存器。比如%rdi, %rsi, %rdx, %rcx, %r8d, %r9d 六个寄存器用于存储函数调用时的前6个参数,那么当输入参数数目超过6个时,如何处理?这些输入参数只能存储在栈上了。
(%rdi等表示64位寄存器,%edi等表示32位寄存器)
//add函数需要9个参数 add(1,2,3,4,5,6,7,8,9); //参数7,8,9存储在栈上 movl $9, 16(%rsp) movl $8, 8(%rsp) movl $7, (%rsp) movl $6, %r9d movl $5, %r8d movl $4, %ecx movl $3, %edx movl $2, %esi movl $1, %edi
Swoole C栈管理
通过学习c栈基本知识,我们知道最主要有三个寄存器:%rip程序计数器指向下一条需要执行的指令,%rbp指向函数栈帧底部,%rsp指向函数栈帧顶部。这三个寄存器可以确定一个c栈执行上下文,c栈的管理其实就是这些寄存器的管理。
第一节我们提到Swoole在管理c栈时,用到了 boost.context库,其中make_fcontext()和jump_fcontext()函数均使用汇编语言编写,实现了c栈执行上下文的创建以及切换;函声明命如下:
fcontext_t make_fcontext( void *sp, size_t size, void (*fn)(intptr_t));
intptr_t jump_fcontext(fcontext_t *ofc, fcontext_t nfc, intptr_t vp, bool preserve_fpu = false);
make_fcontext函数用于创建一个执行上下文,其中参数sp指向内存最高地址处(在堆中分配一块内存作为该执行上下文的c栈),参数size为栈大小,参数fn是一个 函数指针 ,指向该执行上下文的入口函数;代码主要逻辑如下:
/*%rdi表示第一个参数sp,指向栈顶*/movq %rdi, %rax //保证%rax指向的地址按照16字节对齐 andq $-16, %rax //将%rax向低地址处偏移0x48字节 leaq -0x48(%rax), %rax /* %rdx表示第三个参数fn,保存在%rax偏移0x38位置处 */movq %rdx, 0x38(%rax) stmxcsr (%rax) fnstcw 0x4(%rax) leaq finish(%rip), %rcx movq %rcx, 0x40(%rax) //返回值保存在%rax寄存器 ret
make_fcontext函数创建的执行上下文示意图如下(可以看到预留了若干字节用于保存上下文信息):

Swoole协程实现的Context层封装了上下文的创建,创建上下文函数实现如下:
Context::Context(size_t stack_size, coroutine_func_t fn, void* private_data) :
fn_(fn), stack_size_(stack_size), private_data_(private_data)
{
stack_ = (char*) sw_malloc(stack_size_);
void* sp = (void*) ((char*) stack_ + stack_size_);
ctx_ = make_fcontext(sp, stack_size_, (void (*)(intptr_t))&context_func);
}
可以看到c栈执行上下文是通过sw_malloc函数在堆上分配的一块内存,默认大小为2M字节;参数sp指向的是内存最高地址处;执行上下文的入口函数为Context::context_func()。
jump_fcontext函数用于切换c栈上下文:1)函数会将当前上下文(寄存器)保存在当前栈顶(push),同时将%rsp寄存器内容保存在ofc地址;2)函数从nfc地址处恢复%rsp寄存器内容,同时从栈顶恢复上下文信息(pop)。代码主要逻辑如下:
//-------------------保存当前c栈上下文------------------- pushq %rbp /* save RBP */pushq %rbx /* save RBX */pushq %r15 /* save R15 */pushq %r14 /* save R14 */pushq %r13 /* save R13 */pushq %r12 /* save R12 */leaq -0x8(%rsp), %rsp stmxcsr (%rsp) fnstcw 0x4(%rsp) //%rdi表示第一个参数,即ofc,保存%rsp到ofc地址处 movq %rsp, (%rdi) //-------------------从nfc中恢复上下文------------------- //%rsi表示第二个参数,即nfc,从nfc地址处恢复%rsp movq %rsi, %rsp ldmxcsr (%rsp) fldcw 0x4(%rsp) leaq 0x8(%rsp), %rsp popq %r12 /* restrore R12 */popq %r13 /* restrore R13 */popq %r14 /* restrore R14 */popq %r15 /* restrore R15 */popq %rbx /* restrore RBX */popq %rbp /* restrore RBP *///这里弹出的其实是之前保存的%rip popq %r8 //%rdx表示第三个参数,%rax用于存储函数返回值; movq %rdx, %rax //%rdi用于存储第一个参数 movq %rdx, %rdi //跳转到%r8指向的地址 jmp *%r8
观察jump_fcontext函数的汇编代码,可以看到保存上下文与恢复上下文的代码基本是对称的。恢复上下文时”popq %r8″用于弹出上一次保存的程序计数器%rip的内容,然而并没有看到保存寄存器%rip的代码。这是因为调用jump_fcontext函数时,底层call指令已经将%rip入栈了。
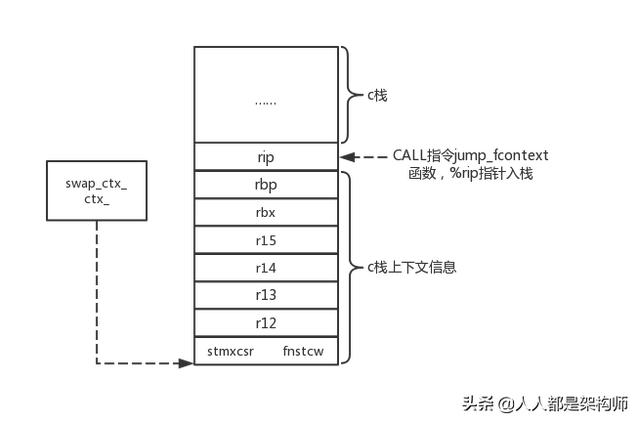
Swoole协程实现的Context层封装了上下文的换入换出,可以在上下文swap_ctx_和ctx_之间随时换入换出,代码实现如下:
bool Context::SwapIn()
{
jump_fcontext(&swap_ctx_, ctx_, (intptr_t) this, true);
return true;
}
bool Context::SwapOut()
{
jump_fcontext(&ctx_, swap_ctx_, (intptr_t) this, true);
return true;
}
上下文示意图如下所示:
Swoole PHP栈管理
php代码在执行时,同样存在函数栈帧的分配与回收。php将此抽象为两个结构,php栈zend_vm_stack,与执行数据(函数栈帧)zend_execute_data。
php栈结构与c栈结构基本类似,定义如下:
struct _zend_vm_stack {
zval *top;
zval *end;
zend_vm_stack prev;
};
其中top字段指向栈顶位置,end字段指向栈底位置;prev指向上一个栈,形成链表,当栈空间不够时,可以进行扩容。php虚拟机申请栈空间时默认大小为256K,Swoole创建栈空间时默认大小为8K。
执行数据结构体,我们需要重点关注这几个字段:当前函数编译后的指令集(opline指向指令集数组中的某一个元素,虚拟机只需要遍历该数组并执行所有指令即可),函数返回值,以及调用该函数的执行数据;结构定义如下:
struct _zend_execute_data {
//当前执行指令
const zend_op *opline;
zend_execute_data *call;
//函数返回值
zval *return_value;
zend_function *func;
zval This; /* this + call_info + num_args */ //调用当前函数的栈帧
zend_execute_data *prev_execute_data;
//符号表
zend_array *symbol_table;
#if ZEND_EX_USE_RUN_TIME_CACHE
void **run_time_cache;
#endif
#if ZEND_EX_USE_LITERALS
//常量数组
zval *literals;
#endif
};
php栈初始化函数为zend_vm_stack_init;当执行用户函数调用时,虚拟机通过函数zend_vm_stack_push_call_frame在php栈上分配新的执行数据,并执行该函数代码;函数执行完成后,释放该执行数据。代码逻辑如下:
ZEND_API void zend_execute(zend_op_array *op_array, zval *return_value)
{
//分配新的执行数据
execute_data = zend_vm_stack_push_call_frame(ZEND_CALL_TOP_CODE | ZEND_CALL_HAS_SYMBOL_TABLE,
(zend_function*)op_array, 0, zend_get_called_scope(EG(current_execute_data)), zend_get_this_object(EG(current_execute_data)));
//设置prev
execute_data->prev_execute_data = EG(current_execute_data);
//初始化当前执行数据,op_array即为当前函数编译得到的指令集
i_init_execute_data(execute_data, op_array, return_value);
//执行函数代码
zend_execute_ex(execute_data);
//释放执行数据
zend_vm_stack_free_call_frame(execute_data);
}
php栈帧结构示意图如下:
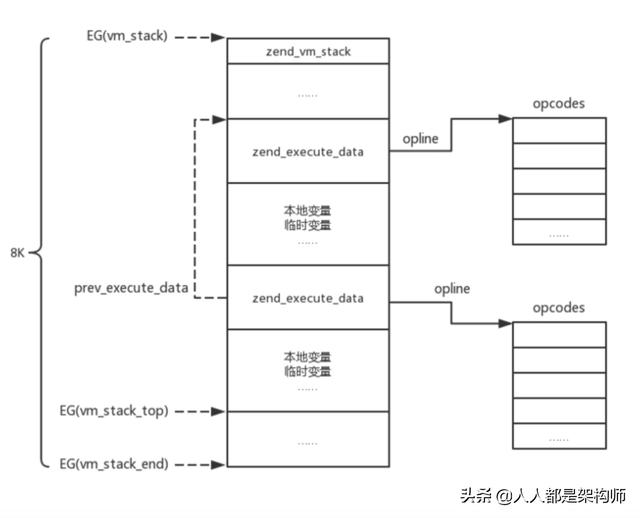
Swoole协程实现,需要自己管理php栈,在发生协程创建以及切换时,对应的创建新的php栈,切换php栈,同时保存和恢复php栈上下文信息。这里涉及到一个很重要的结构体php_coro_task:
struct php_coro_task
{
zval *vm_stack_top;
zval *vm_stack_end;
zend_vm_stack vm_stack;
zend_execute_data *execute_data;
};
这里列出了php_coro_task结构体的若干关键字段,这些字段用于保存和恢复php上下文信息。
协程创建时,底层通过函数PHPCoroutine::create_func实现了php栈的创建:
void PHPCoroutine::create_func(void *arg)
{
//创建并初始化php栈
vm_stack_init();
call = (zend_execute_data *) (EG(vm_stack_top));
//为结构php_coro_task分配空间
task = (php_coro_task *) EG(vm_stack_top);
EG(vm_stack_top) = (zval *) ((char *) call + PHP_CORO_TASK_SLOT * sizeof(zval));
//创建新的执行数据结构
call = zend_vm_stack_push_call_frame(
ZEND_CALL_TOP_FUNCTION | ZEND_CALL_ALLOCATED,
func, argc, fci_cache.called_scope, fci_cache.object
);
}
从代码中可以看到结构php_coro_task是直接存储在php栈的底部。
当通过yield函数让出CPU时,底层会调用函数PHPCoroutine::on_yield切换php栈:
void PHPCoroutine::on_yield(void *arg)
{
php_coro_task *task = (php_coro_task *) arg;
php_coro_task *origin_task = get_origin_task(task);
//保存当前php栈上下文信息到php_coro_task结构
save_task(task);
//从php_coro_task结构中恢复php栈上下文信息
restore_task(origin_task);
}
Swoole协程实现
前面我们简单介绍了Swoole协程的实现方案,以及Swoole对c栈与php栈的管理,接下来将结合前面的知识,系统性的介绍Swoole协程的实现原理。
swoole协程数据模型
话不多说,先看一张图:

- 每个协程都需要管理自己的c栈与php栈;
- Context封装了c栈的管理操作;ctx_字段保存的是寄存器%rsp的内容(指向c栈栈顶位置);swap_ctx_字段保存的是将被换出的协程寄存器%rsp内容(即,将被换出的协程的c栈栈顶位置);SwapIn()对应协程换入操作;SwapOut()对应协程换出操作;
- 参考jump_fcontext实现,协程在换出时,会将寄存器%rip,%rbp等暂存在c栈栈顶;协程在换入时,相应的会从栈顶恢复这些寄存器的内容;
- Coroutine管理着协程所有内容;cid字段表示当前协程的ID;task字段指向当前协程的php_coro_task结构,该结构中保存的是当前协程的php栈信息(vm_stack_top,execute_data等);ctx字段指向的是当前协程的Context对象;origin字段指向的是另一个协程Coroutine对象;yield()和resume()对应的是协程的换出换入操作;
- 注意到php_coro_task结构的co字段指向其对应的协程对象Coroutine;
- Coroutine还有一些静态属性,静态属性的属于类属性,所有协程共享的;last_cid字段存储的是当前最大的协程ID,创建协程时可用于生成协程ID;current字段指向的是当前正在运行的协程Coroutine对象;on_yield和on_resume是两个函数指针,用于实现php栈的切换操作,实际指向的是方法PHPCoroutine::on_yield和PHPCoroutine::on_resume;
swoole协程实现
协程创建
Swoole创建协程可以使用go()函数,底层实现对应的是PHP_FUNCTION(swoole_coroutine_create),其函数实现如下:
PHP_FUNCTION(swoole_coroutine_create)
{
……
long cid = PHPCoroutine::create(&fci_cache, fci.param_count, fci.params);
}
long PHPCoroutine::create(zend_fcall_info_cache *fci_cache, uint32_t argc, zval *argv)
{
……
save_task(get_task());
return Coroutine::create(create_func, (void*) &php_coro_args);
}
class Coroutine
{
public:
static inline long create(coroutine_func_t fn, void* args = nullptr)
{
return (new Coroutine(fn, args))->run();
}
}
- 注意Coroutine::create函数第一个参数伟create_func,该函数后续用于创建php栈,并开始协程代码的执行;
- 可以看到PHPCoroutine::create在调用Coroutine::create创建创建协程之前,保存了当前php栈信息到php_coro_task结构中。
- 注意主程序的php栈是虚拟机创建的,结构与上面画的协程php栈不同,主程序的php_coro_task结构并没有存储在php栈上,而是一个静态变量PHPCoroutine::main_task,从get_task方法可以看出,主程序中get_current_task()返回的是null,因此最后获得的php_coro_task结构是PHPCoroutine::main_task。
class PHPCoroutine
{
public:
static inline php_coro_task* get_task()
{
php_coro_task *task = (php_coro_task *) Coroutine::get_current_task();
return task ? task : &main_task;
}
}
- 在Coroutine的构造函数中完成了协程对象Coroutine的创建与初始化,以及Context对象的创建与初始化(创建了c栈);run()函数执行了协程的换入,从而开始协程的运行;
//全局协程map
std::unordered_map<long, Coroutine*> Coroutine::coroutines;
class Coroutine
{
protected:
Coroutine(coroutine_func_t fn, void *private_data) :
ctx(stack_size, fn, private_data)
{
cid = ++last_cid;
coroutines[cid] = this;
}
inline long run()
{
long cid = this->cid;
origin = current;
current = this;
ctx.SwapIn();
if (ctx.end)
{
close();
}
return cid;
}
}
- 可以看到创建协程对象Coroutine时,通过last_cid来计算当前协程的ID,同时将该协程对象加入到全局map中;代码ctx(stack_size, fn, private_data)创建并初始化了Context对象;
- run()函数将该协程换入执行时,赋值origin为当前协程(主程序中current为null),同时设置current为当前协程对象Coroutine;调用SwapIn()函数完成协程的换入执行;最后如果协程执行完毕,则关闭并释放该协程对象Coroutine;
- 初始化Context对象时,可以看到其构造函数Context::Context(size_t stack_size, coroutine_func_t fn, void* private_data),其中参数fn为协程入口函数(PHPCoroutine::create_func),可以看到其赋值给ontext对象的字段fn_,但是在创建c栈上下文时,其传入的入口函数为context_func;
Context::Context(size_t stack_size, coroutine_func_t fn, void* private_data) :
fn_(fn), stack_size_(stack_size), private_data_(private_data)
{
……
ctx_ = make_fcontext(sp, stack_size_, (void (*)(intptr_t))&context_func);
}
- 函数context_func内部其实调用的就是方法PHPCoroutine::create_func;当协程执行结束时,会标记end字段为true,同时将该协程换出;
void Context::context_func(void *arg)
{
Context *_this = (Context *) arg;
_this->fn_(_this->private_data_);
_this->end = true;
_this->SwapOut();
}
问题:参数arg为什么是Context对象呢,是如何传递的呢?这就涉及到jump_fcontext汇编实现,以及jump_fcontext的调用了
jump_fcontext(&swap_ctx_, ctx_, (intptr_t) this, true); jump_fcontext: movq %rdx, %rdi
调用jump_fcontext函数时,第三个参数传递的是this,即当前Context对象;而函数jump_fcontext汇编实现时,将第三个参数的内容拷贝到%rdi寄存器中,当协程换入执行函数context_func时,寄存器%rdi存储的就是第一个参数,即Context对象。
- 方法PHPCoroutine::create_func就是创建并初始化php栈,执行协程代码;这里不做过多介绍。
问题:Coroutine的静态属性on_yield和on_resume时什么时候赋值的?
在Swoole模块初始化时,会调用函数swoole_coroutine_util_init(该函数同时声明了”Co”等短名称),该函数进一步的调用PHPCoroutine::init()方法,该方法完成了静态属性的赋值操作。
void PHPCoroutine::init()
{
Coroutine::set_on_yield(on_yield);
Coroutine::set_on_resume(on_resume);
Coroutine::set_on_close(on_close);
}
协程切换
用户可以通过Co::yield()和Co::resume()实现协程的让出和恢复,
Co::yield()的底层实现函数为PHP_METHOD(swoole_coroutine_util, yield),Co::resume()的底层实现函数为PHP_METHOD(swoole_coroutine_util, resume)。本节将为读者讲述协程切换的实现原理。
static unordered_map<int, Coroutine *> user_yield_coros;
static PHP_METHOD(swoole_coroutine_util, yield)
{
Coroutine* co = Coroutine::get_current_safe();
user_yield_coros[co->get_cid()] = co;
co->yield();
RETURN_TRUE;
}
static PHP_METHOD(swoole_coroutine_util, resume)
{
……
auto coroutine_iterator = user_yield_coros.find(cid);
if (coroutine_iterator == user_yield_coros.end())
{
swoole_php_fatal_error(E_WARNING, "you can not resume the coroutine which is in IO operation");
RETURN_FALSE;
}
user_yield_coros.erase(cid);
co->resume();
}
- 调用Co::resume()恢复某个协程之前,该协程必然已经调用Co::yield()让出CPU;因此在Co::yield()时,会将该协程对象添加到全局map中;Co::resume()时做相应校验,如果校验通过则恢复协程,并从map种删除该协程对象;
- co->yield()实现了协程的让出操作;1)设置协程状态为SW_CORO_WAITING;2)回调on_yield方法,即PHPCoroutine::on_yield,保存当前协程(task代表协程)的php栈上下文,恢复另一个协程的php栈上下文(origin代表另一个协程对象);3)设置当前协程对象为origin;4)换出该协程;
void Coroutine::yield()
{
state = SW_CORO_WAITING;
if (on_yield)
{
on_yield(task);
}
current = origin;
ctx.SwapOut();
}
- co->resume()实现了协程的恢复操作:1)设置协程状态为SW_CORO_RUNNING;2)回调on_resume方法,即PHPCoroutine::on_resume,保存当前协程(current协程)的php栈上下文,恢复另一个协程(task代表协程)的php栈上下文;3)设置origin为当前协程对象,current为即将要换入的协程对象;4)换入协程;
void Coroutine::resume()
{
state = SW_CORO_RUNNING;
if (on_resume)
{
on_resume(task);
}
origin = current;
current = this;
ctx.SwapIn();
if (ctx.end)
{
close();
}
}
- Swoole协程有四种状态:初始化,运行中,等待运行,运行结束;定义如下:
typedef enum
{
SW_CORO_INIT = 0,
SW_CORO_WAITING,
SW_CORO_RUNNING,
SW_CORO_END,
} sw_coro_state;
- 协程之间可以通过Coroutine对象的origin字段形成一个类似链表的结构;Co::yield()换出当前协程时,会换入origin协程;在A协程种调用Co::resume()恢复B协程时,会换出A协程,换入B协程,同时标记A协程为B的origin协程;
协程切换过程比较简单,这里不做过多详述。
协程调度
当我们调用Co::sleep()让协程休眠时,会换出当前协程;或者调用Coroutine Socket ->recv()从socket接收数据,但socket数据还没有准备好时,会阻塞当前协程,从而使得协程换出。那么问题来了,什么时候再换入执行这个协程呢?
socket读写实现
Swoole的socket读写使用的成熟的IO多路复用模型:epoll/kqueue/select/poll等,并且将其封装在结构体_swReactor中,其定义如下:
struct _swReactor
{
//超时时间
int32_t timeout_msec;
//fd的读写事件处理函数
swReactor_handle handle[SW_MAX_FDTYPE];
swReactor_handle write_handle[SW_MAX_FDTYPE];
swReactor_handle error_handle[SW_MAX_FDTYPE];
//fd事件的注册修改删除以及wait
//函数指针,(以epoll为例)指向的是epoll_ctl、epoll_wait
int (*add)(swReactor *, int fd, int fdtype);
int (*set)(swReactor *, int fd, int fdtype);
int (*del)(swReactor *, int fd);
int (*wait)(swReactor *, struct timeval *);
void (*free)(swReactor *);
//超时回调函数,结束、开始回调函数
void (*onTimeout)(swReactor *);
void (*onFinish)(swReactor *);
void (*onBegin)(swReactor *);
}
在调用函数PHPCoroutine::create创建协程时,会校验是否已经初始化_swReactor对象,如果没有则会调用php_swoole_reactor_init函数创建并初始化main_reactor对象;
void php_swoole_reactor_init()
{
if (SwooleG.main_reactor == NULL)
{
SwooleG.main_reactor = (swReactor *) sw_malloc(sizeof(swReactor));
if (swReactor_create(SwooleG.main_reactor, SW_REACTOR_MAXEVENTS) < 0)
{
}
……
php_swoole_register_shutdown_function_prepend("swoole_event_wait");
}
}
我们以epoll为例,main_reactor各回调函数如下:
reactor->onFinish = swReactor_onFinish; reactor->onTimeout = swReactor_onTimeout; reactor->add = swReactorEpoll_add; reactor->set = swReactorEpoll_set; reactor->del = swReactorEpoll_del; reactor->wait = swReactorEpoll_wait; reactor->free = swReactorEpoll_free;
注意:这里注册了一个函数swoole_event_wait,在生命周期register_shutdown阶段会执行该函数,开始Swoole的事件循环,阻挡了php生命周期的结束。
类Socket封装了socket读写相关的所有操作以及数据结构,其定义如下:
class Socket
{
public:
swConnection *socket = nullptr;
//读写函数
ssize_t recv(void *__buf, size_t __n);
ssize_t send(const void *__buf, size_t __n);
……
private:
swReactor *reactor = nullptr;
Coroutine *read_co = nullptr;
Coroutine *write_co = nullptr;
//连接超时时间,接收数据、发送数据超时时间
double connect_timeout = default_connect_timeout;
double read_timeout = default_read_timeout;
double write_timeout = default_write_timeout;
}
- socket字段类型为swConnection,代表传输层连接;
- reactor字段指向结构体swReactor对象,用于fd事件的注册、修改、删除以及wait;
- 当调用recv()函数接收数据,阻塞了该协程时,read_co字段指向该协程对象Coroutine;
- 当调用send()函数接收数据,阻塞了该协程时,write_co字段指向该协程对象Coroutine;
- 类Socket初始化函数为Socket::init_sock:
void Socket::init_sock(int _fd)
{
reactor = SwooleG.main_reactor;
//设置协程类型fd(SW_FD_CORO_SOCKET)的读写事件处理函数
if (!swReactor_handle_isset(reactor, SW_FD_CORO_SOCKET))
{
reactor->setHandle(reactor, SW_FD_CORO_SOCKET | SW_EVENT_READ, readable_event_callback);
reactor->setHandle(reactor, SW_FD_CORO_SOCKET | SW_EVENT_WRITE, writable_event_callback);
reactor->setHandle(reactor, SW_FD_CORO_SOCKET | SW_EVENT_ERROR, error_event_callback);
}
}
当我们调用CoroutineSocket->recv接收数据时,底层实现如下:
Socket::timeout_setter ts(sock->socket, timeout, SW_TIMEOUT_READ); ssize_t bytes = all ? sock->socket->recv_all(ZSTR_VAL(buf), length) : sock->socket->recv(ZSTR_VAL(buf), length);
类timeout_setter会设置socket的接收数据超时时间read_timeout为timeout。
函数socket->recv_all会循环读取数据,直到读取到指定长度的数据,或者底层返回等待标识阻塞当前协程:
ssize_t Socket::recv_all(void *__buf, size_t __n)
{
timer_controller timer(&read_timer, read_timeout, this, timer_callback);
while (true)
{
do {
retval = swConnection_recv(socket, (char *) __buf + total_bytes, __n - total_bytes, 0);
} while (retval < 0 && swConnection_error(errno) == SW_WAIT && timer.start() && wait_event(SW_EVENT_READ));
if (unlikely(retval <= 0))
{
break;
}
total_bytes += retval;
if ((size_t) total_bytes == __n)
{
break;
}
}
}
- 函数首先创建timer_controller对象,设置其超时时间为read_timeout,以及超时回调函数为timer_callback;
- while (true)死循环读取fd数据,当读取数据量等于__n时,读取操作结束,break该循环;如果读取操作swConnection_recv返回值小于0,并且错误标识为SW_WAIT,说明需要等待数据到来,此时阻塞当前协程等待数据到来(函数wait_event会换出当前协程),阻塞超时时间为read_timeout(函数timer.start()用于设置超时时间)。
class timer_controller
{
public:
bool start()
{
if (timeout > 0)
{
*timer_pp = swTimer_add(&SwooleG.timer, (long) (timeout * 1000), 0, data, callback);
}
}
}
- 函数swTimer_add用于添加一个定时器;Swoole底层定时任务是通过最小堆实现的,堆顶元素的超时时间最近;结构体_swTimer维护着Swoole内部所有的定时任务:
struct _swTimer
{
swHeap *heap; //最小堆
swHashMap *map; //map,定时器ID作为key
//最早的定时任务触发时间
long _next_msec;
//函数指针,指向swReactorTimer_set
int (*set)(swTimer *timer, long exec_msec);
//函数指针,指向swReactorTimer_free
void (*free)(swTimer *timer);
};
- 当调用swTimer_add向_swTimer结构中添加定时任务时,需要更新_swTimer中最早的定时任务触发时间_next_msec,同时更新main_reactor对象的超时时间:
if (timer->_next_msec < 0 || timer->_next_msec > _msec)
{
timer->set(timer, _msec);
timer->_next_msec = _msec;
}
static int swReactorTimer_set(swTimer *timer, long exec_msec)
{
SwooleG.main_reactor->timeout_msec = exec_msec;
return SW_OK;
}
- 函数wait_event负责将当前协程换出,直到注册的事件发生
bool Socket::wait_event(const enum swEvent_type event, const void **__buf, size_t __n)
{
if (unlikely(!add_event(event)))
{
return false;
}
if (likely(event == SW_EVENT_READ))
{
read_co = co;
read_co->yield();
read_co = nullptr;
}
else // if (event == SW_EVENT_WRITE)
{
write_co = co;
write_co->yield();
write_co = nullptr;
}
}
- 函数add_event用于添加事件,底层调用reactor->add添加fd的监听事件;
- read_co = co或者write_co = co,用于记录当前哪个协程阻塞在该socket对象上,当该socket对象的读写事件被触发时,可以恢复该协程执行;
- 函数yield()将该协程换出;
上面提到,创建协程时,注册了一个函数swoole_event_wait,在生命周期register_shutdown阶段会执行该函数,开始Swoole的事件循环,阻挡了php生命周期的结束。函数swoole_event_wait底层就是调用main_reactor->wait等待fd读写事件的产生;我们以epoll为例讲述事件循环的逻辑:
static int swReactorEpoll_wait(swReactor *reactor, struct timeval *timeo)
{
while (reactor->running > 0)
{
n = epoll_wait(epoll_fd, events, max_event_num, swReactor_get_timeout_msec(reactor));
if (n == 0)
{
if (reactor->onTimeout != NULL)
{
reactor->onTimeout(reactor);
}
SW_REACTOR_CONTINUE;
}
for (i = 0; i < n; i++)
{
if ((events[i].events & EPOLLIN) && !event.socket->removed)
{
handle = swReactor_getHandle(reactor, SW_EVENT_READ, event.type);
ret = handle(reactor, &event);
}
if ((events[i].events & EPOLLOUT) && !event.socket->removed)
{
handle = swReactor_getHandle(reactor, SW_EVENT_WRITE, event.type);
ret = handle(reactor, &event);
}
}
}
}
- swReactorEpoll_wait是对函数epoll_wait的封装;当有读写事件发生时,执行相应的handle,根据上面的讲解我们知道读写事件的handle分别为readable_event_callback和writable_event_callback;
int Socket::readable_event_callback(swReactor *reactor, swEvent *event)
{
Socket *socket = (Socket *) event->socket->object;
socket->read_co->resume();
}
- 可以看到函数readable_event_callback只是简单的恢复read_co协程即可;
- 当epoll_wait发生超时,最终调用的是函数swReactor_onTimeout,该函数会从Swoole维护的一系列定时任务swTimer中查找已经超时的定时任务,同时执行其callback回调;
while ((tmp = swHeap_top(timer->heap)))
{
tnode = tmp->data;
if (tnode->exec_msec > now_msec || tnode->round == timer->round)
{
break;
}
timer->_current_id = tnode->id;
if (!tnode->remove)
{
tnode->callback(timer, tnode);
}
……
}
//该定时任务没有超时,需要更新需要更新_swTimer中最早的定时任务触发时间_next_msec
long next_msec = tnode->exec_msec - now_msec;
if (next_msec <= 0)
{
next_msec = 1;
}
//同时更新main_reactor对象的超时时间,实现函数为swReactorTimer_set
timer->set(timer, next_msec);
- 该callback回调函数即为上面设置的timer_callback:
void Socket::timer_callback(swTimer *timer, swTimer_node *tnode)
{
Socket *socket = (Socket *) tnode->data;
socket->set_err(ETIMEDOUT);
if (likely(tnode == socket->read_timer))
{
socket->read_timer = nullptr;
socket->read_co->resume();
}
else if (tnode == socket->write_timer)
{
socket->write_timer = nullptr;
socket->write_co->resume();
}
}
- 同样的,timer_callback函数只是简单的恢复read_co或者write_co协程即可
sleep实现
Co::sleep()的实现函数为PHP_METHOD(swoole_coroutine_util, sleep),该函数通过调用Coroutine::sleep实现了协程休眠的功能:
int Coroutine::sleep(double sec)
{
Coroutine* co = Coroutine::get_current_safe();
if (swTimer_add(&SwooleG.timer, (long) (sec * 1000), 0, co, sleep_timeout) == NULL)
{
return -1;
}
co->yield();
return 0;
}
可以看到,与socket读写事件超时处理相同,sleep内部实现时通过swTimer_add添加定时任务,同时换出当前协程实现的。该定时任务会导致main_reactor对象的超时时间的改变,即修改了epoll_wait的超时时间。
sleep的超时处理函数为sleep_timeout,只需要换入该阻塞协程对象即可,实现如下:
static void sleep_timeout(swTimer *timer, swTimer_node *tnode)
{
((Coroutine *) tnode->data)->resume();
}
文章转载来自李乐,这篇对swoole的研究文章写的很深入,欢迎阅读。
你的转发+关注就是对笔者分享最大的支持,欢迎关注笔者,更多优质文章精彩奉献。


