前言
假设有一批小文件,每个文件都可以通过 mysql load 的方式导入数据库,请问如何操作可以取得较小的时间和资源消耗?
关于这个需求,我们自然会想到各种并发实现方式,比如多进程和 多线程 。由于众所周知的多进程切换的高昂代价以及在某些场合下需要考虑多进程之间的协调和通信,如果情非得已,恐怕很少会使用到多进程。然而在本文讨论的 python 世界中,多 线程 可能也不是一个好的选择。详见下文论述。
线程模型
我们知道操作系统的任务调度是基于内核调度实体(KSE,Kernel Scheduling Entity),所以线程的实现也是基于内核调度实体,也就是通过跟内核调度实体绑定实现自身的调度。根据线程与内核实体的对应关系上的区别,线程的实现模型大致可以分为两大类:内核级线程和用户级线程。
– 内核级线程模型
线程与内核线程 KSE 是一对一(1 : 1)的映射模型,也就是每一个用户线程绑定一个实际的内核线程,而线程的调度则完全交付给操作系统内核去做,应用程序对线程的创建、终止以及同步都基于内核提供的系统调用来完成,大部分编程语言的线程库 (比如 Java 的 java.lang.Thread、C++ 的 std::thread 等等) 都属于内核级线程模型。这种模型的优势和劣势同样明显:优势是实现简单,直接借助操作系统内核的线程以及调度器,所以 CPU 可以快速切换调度线程,于是多个线程可以同时运行,因此相较于用户级线程模型它真正做到了并行处理;但它的劣势是,由于直接借助了操作系统内核来创建、销毁和以及多个线程之间的上下文切换和调度,因此资源成本大幅上涨,且对性能影响很大。
– 用户级线程模型
线程与内核线程 KSE 是多对一(N : 1)的映射模型,多个用户线程的一般从属于单个进程并且多线程的调度是由用户自己的线程库来完成,线程的创建、销毁以及多线程之间的协调等操作都是由用户自己的线程库来负责而无须借助系统调用来实现。许多语言实现的协程库 基本上都属于这种方式(比如 python 的 gevent)。由于线程调度是在用户层面完成的,避免了系统调用和 CPU 在用户态和内核态之间切换的开销,因此对系统资源的消耗会小很多,然而该模型有个问题:假设在某个用户进程上的某个用户线程因为一个阻塞调用(比如 I/O 阻塞)而被 CPU 给中断(抢占式调度)了,整个进程将被挂起。因此,该模型并不能做到真正意义上的并发。
python 线程
我们广泛使用的 python 是基于 CPython 实现,然而由于 CPython 的内存管理不是线程安全的,于是引入了一个全局解释锁(Global Interpreter Lock)来保障 Python 的线程安全。正是因为 GIL 的存在,每个线程执行前都需要获取锁,从而导致多线程的并发性大大削弱,完全无法发挥多核的优势。同时 python 的线程切换是基于字节码指令的条数,因此对于 I/O 密集型计算密集型任务勉强还有用武之地,然而对于计算密集型任务,多线程切换的开销将使多线程成为鸡肋,执行效率反而不如单线程。以下是一个验证例子:
顺序执行的单线程 (single_thread.py)
#! /usr/bin/python
from threading import Threadimport time
def my_counter():
i = 0
for _ in range(100000000):
i = i + 1
return True
def main():
thread_array = {}
start_time = time.time() for tid in range(2):
t = Thread(target=my_counter)
t.start()
t.join()
end_time = time.time()
print("Total time: {}".format(end_time - start_time))
if __name__ == '__main__':
main() 同时执行的两个并发线程 (multi_thread.py)
#! /usr/bin/python
from threading import Threadimport time
def my_counter():
i = 0
for _ in range(100000000):
i = i + 1
return True
def main():
thread_array = {}
start_time = time.time() for tid in range(2):
t = Thread(target=my_counter)
t.start()
thread_array[tid] = t for i in range(2):
thread_array[i].join()
end_time = time.time()
print("Total time: {}".format(end_time - start_time))
if __name__ == '__main__':
main() 在 mac os,4 核 8G 内存 1.8MHz python3.7 上测试执行,多线程比单线程慢 2 秒!
另外值得一提的是尽管存在 GIL,但 python 多线程仍然不是线程安全的,对于共享状态的场合仍然需要借助锁同步。既然 python 多线程如此之糟,有没有一种线程切换代价更小和占用资源更低的技术呢?下面该轮到协程闪亮登场了!
协程
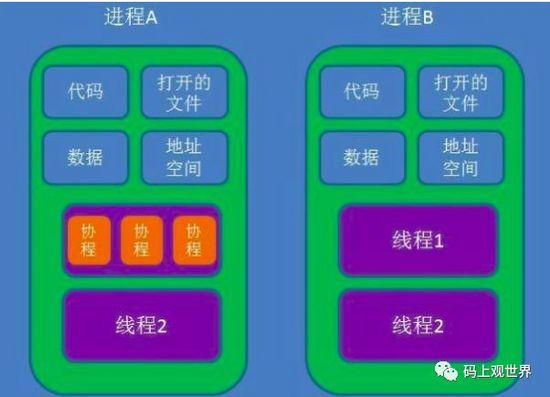
协程(Coroutine)又称微线程,属于用户级线程。上文中提到的 gevent 就是一种协程实现方式,除了 gevent 还有 async IO 。下文详细介绍。上文中,我们介绍了用户级线程就是在一个内核调度实体上映射出来的多个用户线程,用户线程的创建、调度和销毁完全由用户程序控制, 对内核调度透明:内核一旦将 cpu 分配给了线程,该 cpu 的使用权就归该线程所有,线程可以再次按照比如时间片轮转等常规调度算法分配给每个微线程,从而实现更大的并发自由度,但所有的微线程只能在该 cpu 上运行,无法做到并行。为了便于理解,我们这里把协程看作这些映射出来的“微线程”。用户程序控制的协程需要解决线程的挂起和唤醒、现场保护等问题,然而区别于线程的是协程不需要处理锁和同步问题,因为多个协程是在一个用户级线程内进行的,但需要处理因为单个协程阻塞导致整个线程(进程)阻塞的问题。下图展示线程和协程的对照关系:
生成器 – 协程基础
理解协程的挂起和唤醒,不得不提到生成器。生成器也是函数,但跟普通的函数稍有区别,请看下面定义的生成器:
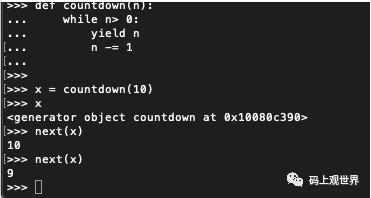
def countdown(n): while n> 0: yield n n -= 1
调用 countdown 并不会执行,如果 print 该函数,会发现返回的是 generator 实例对象。
只有通过 next()函数来执行生成器函数。yield 命令产生了一个值,然后挂起函数,直到下一个 next() 函数。当生成器函数遇到 return 或结束,停止迭代数据。除了 next,还可以使用 send 激活生成器,两者可以交替使用。比如下面生成斐波那契数列的生成器:
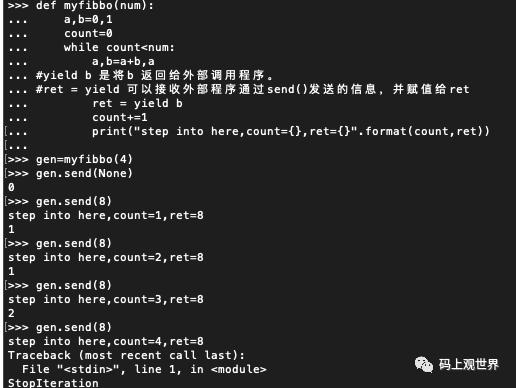
def myfibbo(num):
a,b=0,1
count=0
while count<num:
a,b=a+b,a #yield b 是将b 返回给外部调用程序。
#ret = yield 可以接收外部程序通过send()发送的信息,并赋值给ret
ret = yield b
count+=1
print("step into here,count={},ret={}".format(count,:ret)) 第一次当生成器处于 started 状态时,只能 send(None),否则会报错,当生成器 while 条件不满足退出时,会抛出异常 StopIteration, 如果生成器有返回值,会保存在 exception 的 value 属性中。
生成器首先是个迭代器,因此生成器可以嵌套调用子生成器。
def reader(): # 模拟从文件读取数据的生成器,for表达式可以简写为:yield from range(4) #for i in range(4): # yield i yield from range(4) def reader_wrapper(): yield from reader() wrap = reader_wrapper()for i in wrap: print(i)
在这里 yield from 同时起到了一个提供了一个调用者和子生成器之间的透明的双向通道的作用: 从子生成器获取数据以及向子生成器传送数据。通过上述生成器的例子中,我们已经大体感知到协程的影子了,但还是不够直观,而且不是正在意义上的协程,只是实现的代码执行过程中的挂起,唤醒操作。我们再介绍一个真正的协程实现库 greelet, 知名的网络并发框架如 eventlet,gevent 都是基于它实现的。
greenlet
from greenlet import greenletdef test1(): print(12) gr2.switch() print(34)def test2(): print(56) gr1.switch() print(78) gr1 = greenlet(test1) gr2 = greenlet(test2) gr1.switch()
上例中创建了两个 greenlet 协程对象,gr1 和 gr2,分别对应于函数 test1()和 test2()。从中我们可以看出,使用 switch 方法切换协程,确实比 yield, next/send 组合要直观得多,从输出结果看,greenlet 协程的运行是交叉执行的,(本质是串行的)所以它不是真正意义上的并发,因此也无法发挥 CPU 多核的优势。
创建协程对象的方法其实有两个参数 greenlet(run=None, parent=None)。参数 run 就是其要调用的方法,比如上例中的函数 test1()和 test2();参数 parent 定义了该协程对象的父协程,也就是说,greenlet 协程之间是可以有父子关系的。如果不设或设为空,则其父协程就是程序默认的”main”主协程。这个”main”协程不需要用户创建,它所对应的方法就是主程序,而所有用户创建的协程都是其子孙。大家可以把 greenlet 协程集看作一颗树,树的根节点就是”main”,上例中的 gr1 和 gr2 就是其两个字节点。
在子协程执行完毕后,会自动返回父协程。比如上例中 test1() 函数退出,代码会返回到主程序。
eventlet
eventlet 在 Greenlet 的基础上实现了自己的 GreenThread,实际上就是 greenlet 类的扩展封装,而与 Greenlet 的不同是,Eventlet 实现了自己调度器称为 Hub,Hub 类似于 Tornado 的 IOLoop,是单实例的。在 Hub 中有一个 event loop,根据不同的事件来切换到对应的 GreenThread。同时 eventlet 还实现了一系列的补丁来使 Python 标准库中的 socket 等 module 来支持 GreenThread 的切换。eventlet 的 Hub 可以被定制来实现自己调度过程。
eventlet 使用举例:
import eventletfrom eventlet.green.urllib import request
urls = [ "", "", "",
]def fetch(url):
print("opening", url)
body =request.urlopen(url).read()
print("done with", url) return url, body
pool = eventlet.GreenPool(2)for url, body in pool.imap(fetch, urls):
print("got body from", url, "of length", len(body)) 示例代码中引入 GreenPool 协程池来控制并发度。
gevent
gevent 是基于 libev(Linux 上 epoll,FreeBSD 上 kqueue)和 greenlet 实现的 Python 网络库。libev 是一个事件循环器:向 libev 注册感兴趣的事件,比如 socket 可读事件,libev 会对所注册的事件的源进行管理,并在事件发生时触发相应的程序。也就是说 libev 提供了指定文件描述符事件发生时调用 回调函数 的机制。而 libev 依赖的 epoll 是 Linux 内核为处理大批量文件描述符而作了改进的 poll,是 Linux 下多路复用 IO 接口 select/poll 的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统 CPU 利用率。为了将 python 标准库改造成支持 gevent 的非阻塞库,gevent 使用了 monkey_patch(俗称“猴子补丁”)的办法对大部分标准库包括 socket、ssl、threading 和 select 等模块做了改写。所谓“猴子补丁”就是不改变源代码而对功能进行追加和变更,所以“猴子补丁”并不是 Python 中专有的,一方面它充分利用了动态语言的灵活性,可以对现有的语言 Api 进行追加,替换,修改 Bug,甚至性能优化等,另一方面也给系统维护带来了一些风险。
gevent 使用举例:
from gevent import socket urls = ['www.baidu.com', 'www.example.com', 'www.python.org']jobs = [gevent.spawn(socket.gethostbyname, url) for url in urls] gevent.joinall(jobs, timeout=2) result = [job.value for job in jobs]print(result)
gevent.spawn()方法 spawn 一些 jobs,然后通过 gevent.joinall 将 jobs 加入到微线程执行队列中等待其完成,设置超时为 2 秒。执行后的结果通过检查 gevent.Greenlet.value 值来收集。gevent.socket.gethostbyname() 函数与标准的 socket.gethotbyname() 有相同的接口,但它不会阻塞主线程。
from gevent import monkey;monkey.patch_all()import geventimport requestsimport timeimport pymysqlfrom gevent.pool import Pool def query(sql): db = pymysql.connect(host ='rm-bp1ek8zy4654v7216zo.mysql.rds.aliyuncs.com', user = 'public_admin',passwd= 'xxxxxxyyyyy', db= 'performance_test') cursor = db.cursor() data = cursor.execute(sql) cursor.close() db.close()if __name__ == '__main__': p = Pool(5) sql_list=['select * from seller_payments_report_v2 limit 10' for i in range(50)] p.map(query,sql_list) p.join()
示例代码中,引入了协程池来控制并发,通过 mysql 终端 show processlist;可以看到 gevent 实现了对数据库的并发查询。值得注意的是这里简单的查询没有发生阻塞,但复杂的操作比如 load file 就不一定了。感兴趣的读者可以自行验证。
异步编程框架
上面介绍的 eventlet,gevent 都是从一种同步 IO 模型的角度来实现的,这里介绍一种异步的实现方式。所谓异步 IO,是跟同步 IO 相对的,异步 IO 是计算机操作系统对输入输出的一种处理方式:发起 IO 请求的线程不等 IO 操作完成,就继续执行随后的代码,IO 结果用其他方式 (回调) 通知发起 IO 请求的程序。这样通过异步 IO,应用程序在发起 IO 请求完成之前,不必等待 IO 完成,就可以继续去干其他事情,等待操作系统完成 IO 再通知应用程序去处理。现代操作系统已经将这些 IO 状态包装成基本的事件,如可读事件,可写事件,并且提供应用程序可以接收这些事件的系统模块。比如 select 模块。在 python 中 select 模块就是 selectors,selectors 是对底层 select/poll/epoll/kqueue 的封装。DefaultSelector 类会根据 OS 环境自动选择最佳的模块,最新的 Linux 系统中基本都是基于 epoll 实现。在详细介绍 asyncio 之前,先通过一个网络爬虫的例子,从最基本的 select 模块讲起。
基于 selector 的异步实现
首先我们把要抓取的 url 地址简化为一个 host 主机地址列表:
host_to_access = {'www.baidu.com', 'www.taobao.com', 'www.tencent.com', 'www.toutiao.com', 'www.meituan.com', 'www.tmall.com'} 然后实现一个 Fetcher 类,用于跟一个 url 地址绑定,每个 url 对应一个 Fetcher,用于对 url 的连接和读取响应:
class Fetcher:
def __init__(self,host):
self.response = b'' # Empty array of bytes.
self.host = host
self.sock = None
def fetch(self):
self.sock = socket.socket()
self.sock.setblocking(False) try:
self.sock.connect((self.host, 80)) except BlockingIOError: pass
# Register next callback .
selector.register(self.sock.fileno(),
EVENT_WRITE,
self.connected) def connected(self, key, mask):
selector.unregister(self.sock.fileno())
request='GET / HTTP/1.0\r\nHost: {}\r\n\r\n'.format(self.host)
print('{} connected'.format(self.host))
self.sock.send(request.encode('ascii')) # Register the next callback.
selector.register(key.fd,
EVENT_READ,
self.read_response) def read_response(self, key, mask):
global stopped
chunk = self.sock.recv(4096) # 4k chunk size.
if chunk:
self.response += chunk else:
selector.unregister(key.fd) # Done reading.
host_to_access.remove(self.host) if not host_to_access:
stopped = True
print("key:{},mask:{},read response:{}".format(key,mask,self.response)) Fetcher 使用非阻塞 socket,这样主程序就不需要等待 IO 立即返回,这一点在大量 IO 请求的场景下至关重要。为了让 IO 请求可读可写的时候应用程序能够去处理,我们注册了两个回调函数:connected 和 read_response。前者在建立连接之后,也就是当当前 IO 可写的时候调用;后者在发送请求到服务器之后,服务器有响应内容,客户端当前 IO 请求可读的时候调用。接下来的问题是,客户端同时发起若干个请求,如何知道哪些请求可读可写呢?换句话说客户端如何获取到操作系统的 IO 事件通知呢?这里就需要用到 selectors 模块中的 select 机制了:select 返回当前可读可写的事件列表,如果当前没有事件发生,当前操作将会被阻塞。明显,这里需要一种事件循环方式去轮训检测可读可写的事件,然后调用组册的回调函数,直到所有请求都处理完毕,示例中的 callback 就是应用程序事先注册的回调函数入口:
def loop(): while not stopped: events = selector.select() for event_key, event_mask in events: callback = event_key.data callback(event_key, event_mask)
最后在主程序中依次对每个 url 通过 Fetch 的 fetch 方法触发请求,之后的处理就交给事件循环和回调函数了。
if __name__ == '__main__': for host in host_to_access: fetcher = Fetcher(host) fetcher.fetch() loop()
从上面的例子中我们看到异步 IO 方式跟前文中的同步方式有一个共同点,那就是都在一个线程中并发实现多任务处理的。不同点就是再看不到“猴子补丁”的身影了,从代码安全性上似乎好了不少,但是事实并非如此:在上文中,我们通过 Fetcher 类保存了当前请求的 socket、host 和响应内容。而且这个保存当前应用程序的状态是不得不为的,因为不像同步调用程序那样,接下来要处理的步骤是确定的,异步调用的方式会在 I/O 操作完成之前返回并清除栈帧,然后在未来某个时刻继续未完之事。随着应用程序需要保存的状态逐步增多,维护应用程序的代价也越大。此其一,其二是回调函数缺少上下文,应用程序的维护者很难从问题现象中迅速查询被调用函数从哪里发起,然后又流转到哪里。特别是当回调函数嵌套调用回调函数的时候,这种“堆栈撕裂”的问题将变得更加棘手。那有没有一种更好的方式既保留着回调的优势又能避免它的问题呢?还记得前文中介绍的生成器吗?接下来我们使用生成器来重写上面爬虫的例子。
基于 generator 和 selector 的异步实现
我们在生成器部分的介绍中了解到生成器是可以保存当前状态的,这里通过示例详细展示这个功能点, 首先我们重构 Fetcher 类:
class Fetcher:
def __init__(self,host):
self.response = b'' # Empty array of bytes.
self.host = host def fetch(self):
sock = socket.socket()
sock.setblocking(False) try:
sock.connect((self.host, 80)) except BlockingIOError: pass
f = Future () def on_connected():
f.set_result(None)
print('{} connected'.format(self.host))
selector.register(sock.fileno(), EVENT_WRITE, on_connected) yield f
selector.unregister(sock.fileno())
request='GET / HTTP/1.0\r\nHost: {}\r\n\r\n'.format(self.host)
sock.send(request.encode('ascii')) global stopped while True:
f = Future() def on_readable():
try:
data=sock.recv(4096)
f.set_result(data) except socket.error as e:
print(e)
selector.register(sock.fileno(), EVENT_READ, on_readable)
chunk = yield f
selector.unregister(sock.fileno())
print("host:{},read response:{}".format(self.host,chunk)) if chunk:
self.response += chunk else:
print(self.host+" removed.")
host_to_access.remove(self.host) if not host_to_access:
stopped = True Fetcher 类与上文的实现有几点区别:
1. 不需要保存当前 socket 状态;
2. 回调函数 on_connected 和 on_readable 移到 Fetcher 类里,且不需要参数!
3. 通过引入 yield 不仅保留了回调的异步实现,而且保持了同步实现的简明逻辑。
4. 读取响应内容的完整逻辑被封装进 fetch 方法里。
5. 引入 Future 类,使得程序逻辑按照时间线向未来延伸,通过跟 yield 配合,每次 IO 请求阻塞在 Future 上,同时 fetch 由普通方法变成了一个生成器。
接下来需要解决的问题是,如何唤醒在 Future 处阻塞的请求呢?
我们定义一个 Task 任务类,来驱动整个请求,Task 和 Future 类的实现代码如下:
class Task: def __init__(self, coro): self.coro = coro f = Future() f.set_result(None) self.step(f) def step(self, future): try: # send会进入到coro执行, 即fetch, 直到下次yield # next_future 为yield返回的对象 next_future = self.coro.send(future.result) except StopIteration: return next_future.add_done_callback(self.step) class Future: def __init__(self): self.result = None self._callbacks = [] def add_done_callback(self, fn): self._callbacks.append(fn) def set_result(self, result): self.result = result for fn in self._callbacks: fn(self)
注意 Task 的 step 方法:每次 send 唤起生成器并得到新的生成器,新的生成器绑定的 step 方法将在有事件到来时候被再次执行。循环不断,直到响应内容读取完毕:将第一次通过初始化 Task 调用 step 执行,通过 send(None)方法激活 fetch 生成器,发起 url 连接请求,当连接请求建立后,通过 on_connected 回调方法执行在 Future 中传入的 step 方法发起读请求,再次挂起,当读信号到来时候,再次触发 step 唤醒生成器,并将读取的响应内容传递给 chunk。。。这样一来,生成器和 Task 通过 Futrure 串联起来了。最后该整个流程的关键驱动器事件循环上场了:
def loop(): while not stopped: events = selector.select() for event_key, event_mask in events: callback = event_key.data callback()if __name__ == '__main__': import time start = time.time() for host in host_to_access: fetcher = Fetcher(host) Task(fetcher.fetch()) loop()
从上述示例中,我们看到基于生成器的异步实现,回调函数已经不需要关心是谁触发了事件,而且每个生成器代码中也不需要维护 socket 状态了,整个代码风格非常接近同步代码。是时候为实现这段连接并获取响应的代码代码段正名了 – 协程:即协作式的例程。实际上 python2.5 中也确实有基于生成器的协程实现提案:Coroutines via Enhanced Generators。协程拥有自己的帧栈,每次迭代之间,会暂停执行,继续下次迭代的时候还不会丢失先前的状态。然而美中不足的是基于 yield 实现的协程还是不够优雅,我们再次重构来看看。
基于 yield from 和 selector 的异步实现
通过前面介绍,我们已经知道 yield from 也是 Python 的语法,它可以让嵌套生成器不必通过循环迭代 yield,而是直接 yield from;此外它还打通了生成器和子生成器。直接看代码:下面将请求和读取响应的函数封装如下:
def connect(sock, address):
f = Future()
sock.setblocking(False) try:
sock.connect(address) except BlockingIOError: pass
def on_connected():
f.set_result(None)
print('{} connected'.format(address))
selector.register(sock.fileno(), EVENT_WRITE, on_connected) yield from f
selector.unregister(sock.fileno())def read(sock):
f = Future() def on_readable():
f.set_result(sock.recv(4096))
selector.register(sock.fileno(), EVENT_READ, on_readable)
chunk = yield from f
selector.unregister(sock.fileno()) return chunkdef read_all(sock):
response = []
chunk = yield from read(sock) while chunk:
response.append(chunk)
chunk = yield from read(sock) return b''.join(response) 这样 Fetcher 类的实现变得更加简洁:
class Fetcher:
def __init__(self,host):
self.response = b'' # Empty array of bytes.
self.host = host def fetch(self):
global stopped
sock = socket.socket() yield from connect(sock,(self.host, 80))
request='GET / HTTP/1.0\r\nHost: {}\r\n\r\n'.format(self.host)
sock.send(request.encode('ascii'))
self.response = yield from read_all(sock)
print("{} response:{}".format(self.host,self.response))
host_to_access.remove(self.host) if not host_to_access:
stopped = True 另外值得一提的是,yield from 必须是可迭代对象,而 yield 可以是普通对象,需要需要实现 Future 的 __iter__ 方法:
def __iter__(self): yield self return self.result
从中我们看到用 yield from 改进基于生成器的协程,代码抽象程度更高。很多知名异步编程框架也是基于 yield from。然而本文是不是到此为止了呢?且慢,本文接下来介绍真正的主角 asyncio!
asyncio
上面我们实现的爬虫可以看着简化的 asyncio。实际上 asyncio 是 Python 3.4 试验性引入的异步 I/O 框架,提供了基于协程做异步 I/O 编写单线程并发代码的基础设施。其核心组件有事件循环(Event Loop)、协程 (Coroutine)、任务(Task)、未来对象(Future) 以及其他一些扩充和辅助性质的模块。Python3.5 中新增的 async/await 语法对协程有了明确而显式的支持,称之为原生协程。实际上 async/await 和 yield from 这两种风格的协程底层复用共同的实现,而且相互兼容。
使用 asyncio 须经过一下几个步骤:定义协程函数 ->(封装成 task->)获取事件循环 -> 将 task 放到事件循环中执行。定义好的协程并不能直接使用,需要将其包装成为了一个任务(task 对象),然后放到事件循环中才能被执行。所谓 task 对象是 Future 类的一个子类,保存了协程运行后的状态,用于未来获取协程的结果。在上面的步骤中,之所以在封装 task 这一个步骤上加上括号,是因为我们也可以选择直接将协程放到事件循环中,事件循环会自动帮我们完成这一操作。
任务创建
任务创建有多种方式,第一种方式通过 asyncio 提供的 ensure_future() 函数创建 task,如:
import asyncioimport requestsasync def scan(url):
r = requests.get(url).status_code
print("{}:{}".format(url,r)) return r
task = asyncio.ensure_future(scan('
loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print(task.result()) 第二种,直接通过事件循环的 create_task 方法创建
import asyncioimport requestsasync def scan(url):
r = requests.get(url).status_code
print("{}:{}".format(url,r)) return r
loop = asyncio.get_event_loop()
task = loop.create_task(scan(' # 封装为taskloop.run_until_complete(task)
print(task.result()) 第三种:直接将协程放到事件循环中执行。这种方法并不是说不用将协程封装为 task,而是事件循环内部会自动帮我们完成这一步骤。
import asyncioimport requestsasync def scan(url):
r = requests.get(url).status_code
print("{}:{}".format(url,r)) return r
loop = asyncio.get_event_loop()
loop.run_until_complete(scan(' 无论是上述哪一种方法,最终都需要通过 run_until_complete 方法去执行我们定义好的协程。run_until_complete 是一个阻塞(blocking)调用,直到协程运行结束,它才返回
多协程运行
我们可以将多个协程函数加入事件循环,这时候需要借助 asyncio.gather 函数或者 asyncio.wait 函数。两个函数功能极其相似,不同的是,gather 接受的参数是多个协程,而 wait 接受的是一个协程列表。async.wait 会返回两个值:done 和 pending,done 为已完成的 task,pending 为超时未完成的 task。而 async.gather 只返回已完成 task。比如
import asyncioimport requestsasync def scan(url):
r = requests.get(url).status_code
print("{}:{}".format(url,r)) return r
tasks=[asyncio.ensure_future(scan(urls[i])) for i in range(3)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))for task in tasks:
print('Task Result:', task.result()) 回调函数
import asyncioimport requestsimport functools
urls=["","",""]
total=len(urls)
done=0async def scan(urls):
if len(urls)>0:
url=urls.pop()
r = requests.get(url).status_code return ("{} :{}".format(url,r))def call_back(loop,future):
global done
done=done+1
print('回调函数,协程返回值为:{},Done:{}'.format(future.result(),done)) if done<total:
task = asyncio.ensure_future(scan(urls))
task.add_done_callback(functools.partial(call_back,loop)) else:
loop.stop()async def main(loop):
task = asyncio.ensure_future(scan(urls))
task.add_done_callback(functools.partial(call_back,loop))
loop = asyncio.get_event_loop()
task = asyncio.ensure_future(main(loop))
loop.run_forever() 示例功能为通过回调的方式实现对 url 列表的接龙访问:创建 Task 的同时通过 task.add_done_callback 为 task 任务增加完成回调函数 call_back,在回调函数中,判断 url 是否请求完毕,如果没有请求完毕,继续新建任务,直到所有 url 请求完毕。如果增加首次创建任务的数量,则可以实现类似协程池的功能。
以上便是小编给大家带来的全部内容,转发此文+关注 并私信小编“资料”即可免费领取2020最新python资料和零基础入门教程!
不定期分享干货,欢迎初学和进阶中的小伙伴!


