
- QueryEscape(): Encode URL query string.
- PathEscape(): Encode URL path segment .
什么是URI
从最新的URI RFC 3986可以看出,URI提供了一种简单、可以扩展的方式来定位一个资源,URL是URI的一个子集,必然也遵循URI标准,未来所有标准应该使用URI来替代URL和 URN ,从历史中各个URX的出现和发展看,当前URI是一个综合了历史上各个规范的通用规范。
A Uniform Resource Identifier (URI) provides a simple and extensible means for identifying a resource. The term “Uniform Resource Locator” (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism(e.g., its network “location”). The term “Uniform Resource Name” (URN) has been used historically to refer to both URIs under the “urn” scheme [RFC2141], which are required to remain globally unique and persistent even when the resource ceases to exist or becomes unavailable, and to any other URI with the properties of a name. Future specifications and related documentation should use the general term “URI” rather than the more restrictive terms “URL” and “URN” [RFC3305].
URI结构
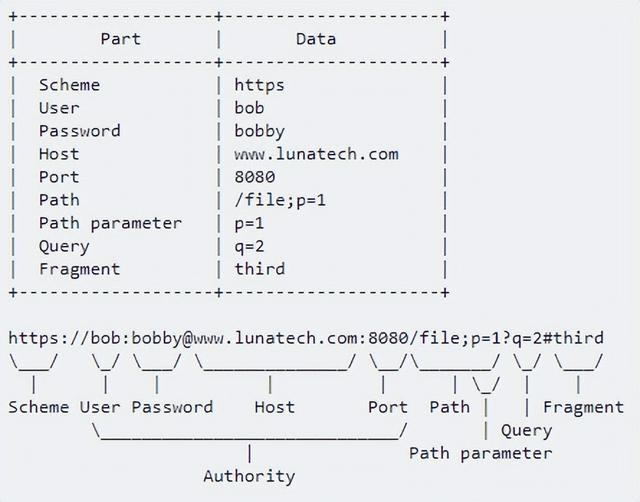
URI字符类型
保留字符和非保留字符
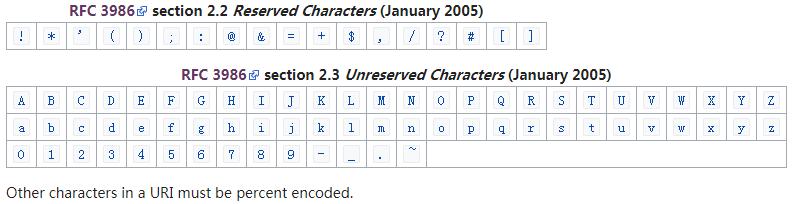
保留字的编码(%+ ascii 十六进制)

- 非保留字符无需转义,保留原样
- 保留字符需要根据不同的上下文位置进行转义,换句话说就是在不同的URI结构部分中,保留字的是否需要转义不太一样,但不论是否有特殊意义,都转义也没错,如果不知道是否需要转义,那就都转义吧
- 如果不是保留字也不是非保留字,则必须编码,需要先将字符转为 utf -8字节序列,然后每个字节转为:%+字节的十六进制表示
特殊的application/x-www-form-urlencoded
在Form请求中有两种数据格式:application/x-www-form-urlencoded和multipart/form-data,通常默认是前者,后者通常用于文件上传
application/x-www-form-urlencoded遵循的是 html 和xform标准,虽然也在不断进化,比如,用+代替了%20,但依然比较古老
要注意的地方在于:GET和POST的区分,当用GET请求时,form数据会变成URI的query部分,遵循URI标准,但用POST的时候遵循的是html和xform标准
这个地方有点坑,好在目前大多数语言和浏览器都能很好地处理这种情况,一般不会遇到问题,而且现在越来越多的人开始用application/ json 作为请求头,用来告诉服务端消息主体是序列化后的 JSON 字符串,x-www-form-urlencoded用得也越来越少了
常见问题
1. 空格在URI中到底用”+” 还是 “%20” ?
在URI的path部分,空格需要转成%20,而在query部分,空格需要转成+号
2. escape or encodeURI
escape:
- 不对 ASCII 字母、数字进行编码
- 不对 *@-_+./ 进行编码
- 其他所有的字符都会被转义序列替换
encodeURI:
- 不对 ASCII 字母和数字进行编码
- 不对 -_.!~*'();/?:@&=+$,# 这20个ASCII 标点符号进行编码
- 其他所有的字符都会被转义序列替换
encodeURI遵循3896标准
go lang实现
在go中有两个函数用于url编码:Values.Encode() 和 PathEscape()
- QueryEscape(): Encode URL query string.
- PathEscape(): Encode URL path segment.
type encoding int
const (
encodePath encoding = 1 + iota
encodePathSegment
encodeHost
encodeZone
encodeUserPassword
encodeQueryComponent
encodeFragment
)
// Encode encodes the values into ``URL encoded'' form
// ("bar=baz&foo=quux") sorted by key.
func (v Values) Encode() string {
if v == nil {
return ""
}
var buf strings.Builder
keys := make([]string, 0, len(v))
for k := range v {
keys = append(keys, k)
}
sort.Strings(keys)
for _, k := range keys {
vs := v[k]
keyEscaped := QueryEscape(k)
for _, v := range vs {
if buf.Len() > 0 {
buf.Write byte ('&')
}
buf.WriteString(key escape d)
buf.WriteByte('=')
buf.WriteString(QueryEscape(v))
}
}
return buf.String()
}
// QueryEscape escapes the string so it can be safely placed
// inside a URL query.
func QueryEscape(s string) string {
return escape(s, encodeQueryComponent)
}
// PathEscape escapes the string so it can be safely placed
// inside a URL path segment.
func PathEscape(s string) string {
return escape(s, encodePathSegment)
} 根据上述代码分析可以看到,最后都调用了escape函数,但参数略有区分:Values.Encode 用了encodeQueryComponent,而PathEscape用了encodePathSegment,用于区分不同的模式
下面看escape函数:
func escape(s string, mode encoding) string {
spaceCount, hexCount := 0, 0
for i := 0; i < len(s); i++ {
c := s[i]
if shouldEscape(c, mode) {
if c == ' ' && mode == encodeQueryComponent {
spaceCount++
} else {
hexCount++
}
}
}
if spaceCount == 0 && hexCount == 0 {
return s
}
var buf [64]byte
var t []byte
required := len(s) + 2*hexCount
if required <= len(buf) {
t = buf[:required]
} else {
t = make([]byte, required)
}
if hexCount == 0 {
copy(t, s)
for i := 0; i < len(s); i++ {
if s[i] == ' ' {
t[i] = '+'
}
}
return string(t)
}
j := 0
for i := 0; i < len(s); i++ {
switch c := s[i]; {
case c == ' ' && mode == encodeQueryComponent:
t[j] = '+'
j++
case shouldEscape(c, mode):
t[j] = '%'
t[j+1] = "0123456789ABCDEF"[c>>4]
t[j+2] = "0123456789ABCDEF"[c&15]
j += 3
default:
t[j] = s[i]
j++
}
}
return string(t)
} escape函数中调用了shouldEscape,这个函数返回 bool ,从名字上看应该是用来判断是否需要转义的,先不看它的实现,我们先看下escape的逻辑:
spaceCount, hexCount 分别用来记录空格数和需要转义的字符数
shouldEscape:true && mode==encodeQueryComponent时,需要把空格转为+
shouldEscape:true && mode!=encodeQueryComponent时,需要把空格转为%20
下面我们看shouldEscape函数:
// Return true if the specified character should be escaped when
// appearing in a URL string, according to RFC 3986.
//
// Please be informed that for now shouldEscape does not check all
// reserved characters correctly. See golang.org/issue/5684.
func shouldEscape(c byte, mode encoding) bool {
// §2.3 Unreserved characters (alphanum)
if 'A' <= c && c <= 'Z' || 'a' <= c && c <= 'z' || '0' <= c && c <= '9' {
return false
}
if mode == encodeHost || mode == encodeZone {
// §3.2.2 Host allows
//sub-delims = "!" / "$" / "&" / "'" / "(" / ")" / "*" / "+" / "," / ";" / "="
// as part of reg-name.
// We add : because we include :port as part of host.
// We add [ ] because we include [ipv6]:port as part of host.
// We add < > because they're the only characters left that
// we could possibly allow, and Parse will reject them if we
// escape them (because hosts can't use %-encoding for
// ASCII bytes).
switch c {
case '!', '$', '&', '\'', '(', ')', '*', '+', ',', ';', '=', ':', '[', ']', '<', '>', '"':
return false
}
}
switch c {
case '-', '_', '.', '~': // §2.3 Unreserved characters (mark)
return false
case '$', '&', '+', ',', '/', ':', ';', '=', '?', '@': // §2.2 Reserved characters (reserved)
// Different sections of the URL allow a few of
// the reserved characters to appear unescaped.
switch mode {
case encodePath: // §3.3
// The RFC allows : @ & = + $ but saves / ; , for assigning
// meaning to individual path segments. This package
// only manipulates the path as a whole, so we allow those
// last three as well. That leaves only ? to escape.
return c == '?'
case encodePathSegment: // §3.3
// The RFC allows : @ & = + $ but saves / ; , for assigning
// meaning to individual path segments.
return c == '/' || c == ';' || c == ',' || c == '?'
case encodeUserPassword: // §3.2.1
// The RFC allows ';', ':', '&', '=', '+', '$', and ',' in
// userinfo, so we must escape only '@', '/', and '?'.
// The parsing of userinfo treats ':' as special so we must escape
// that too.
return c == '@' || c == '/' || c == '?' || c == ':'
case encodeQueryComponent: // §3.4
// The RFC reserves (so we must escape) everything.
return true
case encodeFragment: // §4.1
// The RFC text is silent but the grammar allows
// everything, so escape nothing.
return false
}
}
if mode == encodeFragment {
// RFC 3986 §2.2 allows not escaping sub-delims. A subset of sub-delims are
// included in reserved from RFC 2396 §2.2. The remaining sub-delims do not
// need to be escaped. To minimize potential breakage, we apply two restrictions:
// (1) we always escape sub-delims outside of the fragment, and (2) we always
// escape single quote to avoid breaking callers that had previously assumed that
// single quotes would be escaped. See issue #19917.
switch c {
case '!', '(', ')', '*':
return false
}
}
// Everything else must be escaped.
return true
} shouldEscape函数很清晰,和URI标准一致,URI不同的部分需要转义的字符不一样。


