上一篇文章《 》我们学习了Go语言基础的一些变量和条件控制语句,结构体等。
这一篇主要学习一下Go语言中的字符串和指针。
一 字符串
字符串是每一门编程语言学习中必不可少部分。
在Python中,字符串可以用单引号包起来,也可以用双引号包起来,多行字符串可以使用三个单引号或三个双引号包起来。看下面的代码:
s = "hello"
s = 'hello'
s = '''I am the first line.
I am the second line.
I am the third line.'''
println(s)
在Go语言中,单行字符串只能用双引号包起来(单引号包起来的只能是单个字符),多行字符串用反引号包起来。看下面的代码:
a := "string"
// b := 'string' // 此行编译错误,单引号包含的只能是单个字符
s := `I am the first line.
I am the second line.
I am the third line.`
fmt.Println(s)
编码
Python中默认的 字符编码 是 Unicode ,有必要先来了解一下Unicode字符:
Unicode字符编码是国际组织指定的一种编码标准,可以用来表示任意字符。Unicode编码是一种编码标准,但并没有规定字符如何存储。以汉字“汉”为例,它的 Unicode 码点是 0x6c49,对应的二进制数是 110110001001001,二进制数有 15 位,这也就说明了它至少需要 2 个字节来表示。可以想象,在 Unicode 字典中往后的字符可能就需要 3 个字节或者 4 个字节,甚至更多字节来表示了。
这就导致了一些问题,计算机怎么知道这个 2 个字节表示的是一个字符,而不是分别表示两个字符呢?这里我们可能会想到,那就取个最大的,假如 Unicode 中最大的字符用 4 字节就可以表示了,那么我们就将所有的字符都用 4 个字节来表示,不够的就往前面补 0。这样确实可以解决编码问题,但是却造成了空间的极大浪费,如果是一个英文文档,那文件大小就大出了 3 倍,这显然是无法接受的。
这个时候就出现了UTF-8可变长编码。UTF-8对于不同的字符存储需要,可以使用不同的字节长度来存储。比如,ASCII码的码值范围为0~127,只需要一个字节来存储即可,对于中文,绝大多数中文字都是3个字节即可存储。这样,就不用每个字符都使用4个字节来存储,极大的节省了空间。
Go语言的默认字符编码是UTF-8。字符串底层使用字节数组来存储,那么我们就可以使用len()函数来获取字符串的长度了。同时,Go语言可以使用[]byte(s)把字符串轻松的转换成字节切片。
底层使用字节数组来存储,因此字符串可以使用和切片类似的很多操作,比如:
s := "Hello, 世界"
bytes := []byte(s)
fmt.Println(bytes) // 输出:[72 101 108 108 111 44 32 228 184 150 231 149 140]
for i := 0; i < len(s);i++ {
fmt.Printf("%d %c\n", i, s[i])
}
for循环里那行输出的是:

等一下,最后输出的从第7行到第12行有一些奇怪的字符。这是因为,“世界”中的每个字符在UTF-8编码下占3个字节,只取出每个字符的其中一个字节来输出,当然会是乱码。“Hello, 世界”这个字符串在底层是这样存储的:

如果我们想输出字符串的每个字符,该怎么办?
可以使用rune类型,把字符串转换成rune切片:
s := "Hello, 世界"
r := []rune(s)
fmt.Println(r) // 输出:[72 101 108 108 111 44 32 19990 30028]
for i := 0; i < len(r);i++ {
fmt.Printf("%d %c\n", i, r[i])
}
// 输出:
0 H
1 e
2 l
3 l
4 o
5 ,
6
7 世
8 界
或者直接使用range来循环字符串:
s := "Hello, 世界"
for i, c := range s {
fmt.Printf("%d %c\n", i, c)
}
// 输出:
0 H
1 e
2 l
3 l
4 o
5 ,
6
7 世
10 界
range会自动把字符串的字符按照UTF-8解码出来,这样循环字符串得到的字符就是一个完整的UTF-8字符了,而不是字符中的一个字节。
rune类型
在Go语言中,rune类型就是int的别名。看看官方解释:
// rune is an alias for int32 and is equivalent to int32 in all ways. It is
// used, by convention, to distinguish character values from integer values.
//int32的别名,几乎在所有方面等同于int32
//它用来区分字符值和整数值
type rune = int32
rune是用来区分字符值和整数值的。怎么区分?对于整数,直接使用int类型就好了。对于字符呢?我们上面说到,Go语言中字符都是使用UTF-8编码存储的,从1个到4个字节不等。那么每一个UTF-8字符,最多也就使用4个字节(32比特),也就是int32的长度,那么我们就可以使用int32类型来表示任意UTF-8字符的值。因此,我们得到rune类型的字符值之后,直接把这个值当成字符输出,就可以得到我们想要的字符了,而不是乱码了。有了这个结论,我们就可以知道,rune在处理中文时特别有用。
字符串方法
Go语言strings模块中内置了非常多的字符串方法。
Compare(a, b string) int
// Compare returns an integer comparing two strings lexicographically.
// The result will be 0 if a==b, -1 if a < b, and +1 if a > b.
//
// Compare is included only for symmetry with package bytes.
// It is usually clearer and always faster to use the built-in
// string comparison operators ==, <, >, and so on.
func Compare(a, b string) int {...}
字符串比较方法,传入a、b参数,返回比较结果。如果a小于b,则返回-1;如果a等于b,返回0;如果a大于b,返回1。Compare函数会按照字符的字典顺序比较字符串,见下图:
s1 := "abc"
s2 := "bac"
fmt.Println(strings.Compare(s1, s2)) // 输出-1
但是,官方并不建议使用Compare函数来比较字符串,看Compare源码中的结束,比较字符串可以直接使用大于、小于、等于号进行比较,并不需要使用Compare函数。
Index(s, substr string) int
子串查找/定位。如果s中包含substr这个子串,函数会返回substr在s中第一次出现的位置;如果不包含,会返回-1。看一下源码解释:
// Index returns the index of the first instance of substr in s, or -1 if substr is not present in s.
func Index(s, substr string) int {...}
使用案例:
s := "I am 中国人"
s1 := "国"
fmt.Println(strings.Index(s, s1)) // 输出:8
为什么输出是8而不是5呢?这是因为中Index函数返回的是子串所在的字节数位置。“I am ”占了5个字节,“中”占了3个字节,因此“国”所在的起始位置就是8。
IndexAny(s, chars string) int
在s中查找chars中的任意字符,如果找到了就返回其位置,没找到就返回-1。
看一下源码解释:
// IndexAny returns the index of the first instance of any Unicode code point
// from chars in s, or -1 if no Unicode code point from chars is present in s.
func IndexAny(s, chars string) int {...}
注意,这是在s中查找chars里的任意 Unicode 字符,不是Unicode字符则会找不到。见下面的例子:
s := "中国人"
s1 := s[3:4]
s2 := s[3:6]
fmt.Println(s1) // 输出:�
fmt.Println(s2) // 输出:国
fmt.Println(strings.IndexAny(s, s1)) // 输出:-1
fmt.Println(strings.IndexAny(s, s2)) // 输出:3
LastIndex(s, substr string) int
和Index相反,LastIndex函数在s中查找substr最后一次出现的位置,没找到则返回-1。看一下官方解释:
// LastIndex returns the index of the last instance of substr in s, or -1 if substr is not present in s.
func LastIndex(s, substr string) int {...}
使用案例:
s := "中国 国人"
s2 := s[3:6]
fmt.Println(s2) // 输出:国
fmt.Println(strings.LastIndex(s, s2)) // 输出:7
Join(elems []string, sep string) string
把切片字符串elems用sep字符串连接起来,在处理文件路径时会非常有用。看一下官方解释:
// Join concatenates the elements of its first argument to create a single string. The separator
// string sep is placed between elements in the resulting string.
func Join(elems []string, sep string) string {...}
典型使用案例:
s := []string{"a", "b", "c"}
s1 := "/"
fmt.Println(strings.Join(s, s1)) // 输出:a/b/c
HasPrefix(s, prefix string) bool
这个函数和 Java 中字符串的startsWith方法一样,看看字符串s是不是以字符串prefix开头的。看一下源码和官方解释:
// HasPrefix tests whether the string s begins with prefix.
func HasPrefix(s, prefix string) bool {
return len(s) >= len(prefix) && s[0:len(prefix)] == prefix
}
典型使用案例:
s := "中国"
s1 := "中"
s2 := "国"
fmt.Println(strings.HasPrefix(s, s1)) // 输出:true
fmt.Println(strings.HasPrefix(s, s2)) // 输出:false
HasSuffix(s, suffix string) bool
这个函数和Java中字符串的endsWith方法一样,看看字符串s是不是以字符串suffix结尾的。看一下源码和官方解释:
// HasSuffix tests whether the string s ends with suffix.
func HasSuffix(s, suffix string) bool {
return len(s) >= len(suffix) && s[len(s)-len(suffix):] == suffix
}
典型使用案例:
s := "中国"
s1 := "中"
s2 := "国"
fmt.Println(strings.HasSuffix(s, s1)) // 输出:false
fmt.Println(strings.HasSuffix(s, s2)) // 输出:true
Trim (s string, cutset string) string
移除处于s两端的cutset中包含的任意字符:
s := "中国中国中国"
fmt.Println(strings.Trim(s, "国")) // 输出:中国中国中
fmt.Println(strings.Trim(s, "中国")) // 输出:(空)
我们知道,在Web项目中处理用户输入时,经常需要处理掉用户输入的空白字符,如果想移除字符串两边的空白字符呢?我们试试:
s := " 中国中国中国 "
fmt.Println(strings.Trim(s, "")) // 输出: 中国中国中国
fmt.Println(strings.Trim(s, " ")) // 输出: 中国中国中国
怎么好像没啥作用?其实,移除两边的空白字符应该使用TrimSpace函数。
TrimSpace(s string) string
去除s两端的空白字符(包括空格、回车、换行、制表符)。
// TrimSpace returns a slice of the string s, with all leading
// and trailing white space removed, as defined by Unicode.
func TrimSpace(s string) string {...}
看一下使用案例:
s := " 中国中国中国 "
fmt.Println(strings.TrimSpace(s)) // 输出:中国中国中国
Split(s, sep string) []string
用sep来分割字符串s,返回分割后的字符串切片。如果s中不包含sep并且sep不为空,则返回的切片结果中只会有一个元素,那就是s本身;如果sep为空,那么会把字符串s的每个UTF-8字符都切分开,放入切片结果中返回。来看一下官方解释:
// Split slices s into all substrings separated by sep and returns a slice of
// the substrings between those separators.
//
// If s does not contain sep and sep is not empty, Split returns a
// slice of length 1 whose only element is s.
//
// If sep is empty, Split splits after each UTF-8 sequence. If both s
// and sep are empty, Split returns an empty slice.
//
// It is equivalent to SplitN with a count of -1.
func Split(s, sep string) []string {...}
看一下典型使用案例:
s := "中国中国中国"
fmt.Println(strings.Split(s, "")) // 输出:[中 国 中 国 中 国]
fmt.Println(strings.Split(s, "2")) // 输出:[中国中国中国]
那么,我如果只想分割2次呢?可以使用SplitN函数:
s := "中国中国中国"
fmt.Println(strings.SplitN(s, "", 2)) // 输出:[中 国中国中国]
fmt.Println(strings.SplitN(s, "2", 2)) // 输出:[中国中国中国]
还记得Java的split函数中还可以按照正则表达式来分割字符串,但是在Go语言中字符串函数却不行。这需要用到Go语言中的正则表达式。在接下来的文章中会重点讲这一块。
二 指针
Go语言和Java、Python显著不同的一点就是指针。如果你是从Java和Python转过来的,学起来会费力些,如果你是C++工作者,学起来会非常爽。
Go语言中指针和C++中指针一样操作,通过取地址符就可以取到变量的地址,赋给一个指针变量。
s := "中国中国中国"
p := &s
fmt.Println(p) // 输出:0xc0000381f0
fmt.Println(*p) // 输出:中国中国中国
p里面存放的是s的地址,直接输出p会看到一串16进制的字符串,*p才是指针p所指向的内容。
Go语言中指针的二进制类型是int类型,看一下源码:
// uintptr is an integer type that is large enough to hold the bit pattern of
// any pointer.
type uintptr uintptr
一个int类型的变量能够寻址到计算机的任意位置,因此int类型用来用来存放变量地址绰绰有余。
函数参数指针
指针在函数传参时会非常有用。Go语言在调用函数时,会把函数的参数复制一份传递过去。如果函数参数是值类型,这时,在函数内部修改参数就不会反映到函数外部了。见下面的例子:
func modifyArray(a [3]int) [3]int{ // 数组是值类型,传递给函数时,会复制一份传过去。
a[1] = 0
return a
}
func main() {
s := [3]int{1, 2, 3}
modifyArray(s)
fmt.Println(s) // 输出:[1 2 3]
}
Go语言中,数组是值类型,在调用函数的时候,会把数组拷贝一份传递给函数modifyArray,这样在modifyArray内部修改就不会反映到函数外面去了。

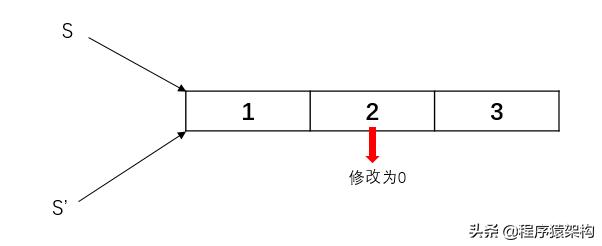
那么怎么让它在函数内部能修改呢?把函数参数改成数组指针类型就可以了(或者可以使用切片类型,在后续文章会详解切片)。
func modifyArray(a *[3]int) *[3]int{ // 数组是值类型,传递给函数时,会复制一份传过去。
a[1] = 0
return a
}
func main() {
s := [3]int{1, 2, 3}
modifyArray(&s)
fmt.Println(s)
}
由于调用函数会导致函数参数复制一份,如果函数参数非常大,复制成本会很高,导致性能下降,这时候指针参数就非常有用了。指针中存放的是参数的地址,传递参数时直接复制一份指针就可以了。
结构体指针方法
指针在结构体的方法中也很有用。先来看一下下面的例子:
type rect struct {
width, height int
}
func (r rect) modifyWidth(){ // rect实现了area方法
r.width = 3
}
func (r *rect) modifyWidthPointer(){ // rect实现了perim方法,则rect实现了geometry接口
r.width = 3
}
func main() {
var rec = rect{
width: 0,
height: 0,
}
rec.modifyWidth()
fmt.Println(rec) // 输出:{0 0}
rec.modifyWidthPointer()
fmt.Println(rec) // 输出:{3 0}
}
可以看到,把指针作为方法接收者,则可以在方法中任意修改接收者的属性并这种修改反映到方法外面。而使用非指针接收者的方法却修改不了。这是因为,非指针接收者在调用方法modifyWidth时,把本身的值赋值了一份。
下一篇文章我们讲一下函数和接口,讲一下怎么用Go语言实现Java中最常见的多态。


