通道
Go语言可以有效地利用多核CPU,并发性能好,这正是由于goroutine和通道还有GPM模型的原因。
我们知道, Python 语言由于全局锁GIL,单个Python应用的多线程代码没办法有效利用多核CPU,只能写多进程来利用多核CPU。如果用标准库的multiprocessing会对监控和管理造成不少的挑战。部署Python应用的时候通常是每个CPU核部署一个应用,这样会浪费不少资源。Go语言的goroutine和GPM模型性能远远超越Python的并发模型。先来看看通道和goroutine。
Go语言中通道类型是chan关键字,通过make来创建。可以创建带缓冲的通道和无缓冲的通道。
创建通道
unbuffered := make(chan int) // 无缓冲的整型通道
buffered := make(chan string, 10) // 有缓冲的字符型通道
缓冲通道和无缓冲通道有什么区别?
无缓冲通道没有容量,我们想要往通道中发送数据,那么一定要有另一个操作在往这个通道取数据,否则,发送数据的那段代码也会被阻塞。
缓冲通道只是有一段容量可以缓冲一下,当缓冲区未满时,往通道中发送数据不会阻塞当前操作;当缓冲区满了时往通道中发送数据,会想无缓冲通道那样阻塞。
发送数据
buffered <- "Gopher" // 通过通道发送一个字符串
接收数据
received := <- buffered // 通过通道接收一个字符串
<- unbuffered // 接收并丢弃字符串,如果unbuffered通道里没数据,则会一直阻塞直到有数据放入
receiver, ok := <- buffered
if !ok {
xxx // 通道被关闭等问题
}
关闭通道
通常来说,我们往通道里发送完数据后,我们应该关闭通道(一般来说由生产者来关闭通道),这就相当于告诉消费者,我的数据发送完了,你取完了数据之后就离开吧。
我们应该在所有数据都放入通道后再关闭通道,否则,如果先关闭通道,再往里放数据的话会产生panic。看下面的例子:
close (buffered)
go func() {
for {
j, more := <-jobs // 如果通道已被关闭,并且数据已全被取走,则more为false
if more {
fmt.Println("received job", j)
} else {
fmt.Println("received all jobs")
done <- true
return
}
}
}()
for post := 1; post <= taskLoad; post++ {
tasks <- fmt.Sprintf("Task : %d", post)
}
// 当所有工作都处理完时关闭通道,以便所有goroutine退出
close(tasks)
通道可以用来实现同步功能:
func worker(done chan bool) {
fmt.Print("working...")
time.Sleep(time.Second)
fmt.Println("done")
done <- true
close(done)
}
func main() {
done := make(chan bool)
go worker(done)
<-done // 阻塞,直到通道中有数据
}
单向通道
默认地,我们使用make(ch chan int)创建的通道都是双向通道,我们可以往里面发送数据也可以从里面读取数据。我们也可以在定义通道的地方指明通道的方向,看下面的例子:
func ping(pings chan<- string, msg string) {
// pings单向通道,函数中只能往pings发送数据
pings <- msg
}
func pong(pings <-chan string, pongs ch an<- string) {
// pings单向通道,函数中只能从pings接收数据
// pongs单向通道,函数中只能往pongs发送数据
msg := <-pings
pongs <- msg
}
声明单向通道最大的好处就是可以限制程序的行为。比如我们在定义接口给其他人调用时,我们就可以指明通道为单向通道,接口使用者只能往通道发送数据或者只能从通道读取数据。
生产者消费者问题
生产者只往通道里面发送数据,发送完后关闭通道。消费者只从通道里面读取数据。这可比 Java 中使用wait/notify来实现生产者消费者方便多了。
func producer(ch chan<- int) {
for i := 1; i <= 10; i++ {
ch <- i
}
close(ch)
}
func consumer(ch <-chan int) {
for i := range ch {
fmt.Println("consumed something: ", i)
}
}
func main() {
ch := make(chan int)
go producer(ch)
go consumer(ch)
time.Sleep(time.Second)
}
goroutine
Go语言中的goroutine,一般也称作协程,不由OS调度,而是用户层自行释放CPU,从而在执行体之间切换调度运行。Go语言在底层进行协助实现。涉及系统调用的地方由Go标准库协助释放CPU。总之,协程运行不通过OS进行切换,由Go语言自行切换,系统运行开支大大降低。一个进程内部可以运行多个 线程 ,而每个线程又可以运行很多协程。线程要负责对协程进行调度。当一个协程睡眠时,它将线程的运行权让给其它的协程来运行。同一个线程内部最多只会有一个协程正在运行。
创建Goroutine
创建goroutine很方便,创建个匿名函数并调用,然后在前面加上go关键字就可以了。
go func(msg string) {
fmt.Println(msg)
}("going")
还可以把函数赋给一个变量,然后创建goroutine运行:
var myFunc = func(msg string) {
fmt.Println(msg)
}
go myFunc("going")
主协程和子协程
Go语言所有代码都运行在协程中,由Go运行时进行调度,其中main函数所在的协程叫做主协程,其余的协程叫做子协程。
func main() {
for i := 0; i < 5; i++ {
go func(i int) {
fmt.Print(i, " ")
}(i)
}
time.Sleep(time.Second)
}
// 输出:0 4 3 1 2
当主协程执行完而子协程未执行完时,所有子协程会随着主协程的结束而退出运行。上面的代码输出“0 4 3 1 2 ”,这是因为创建完协程后放入运行时队列到真正运行有个过程,哪个协程先被放入运行时队列,哪个就能先执行。
线程的调度是由操作系统负责的,调度算法运行在内核态,而协程的调用是由 Go 语言的运行时负责的,调度算法运行在用户态。这就使得Go语言的协程比Java的线程更加轻量级。单一的Java应用创建几十上百个线程并运行就已经非常消耗内存和CPU资源了,而单一的Go应用可以创建上千万的goroutine还正常地运行。
GPM
先回顾一下Java中线程和操作系统内核线程的对应关系。Java中线程模型如下:
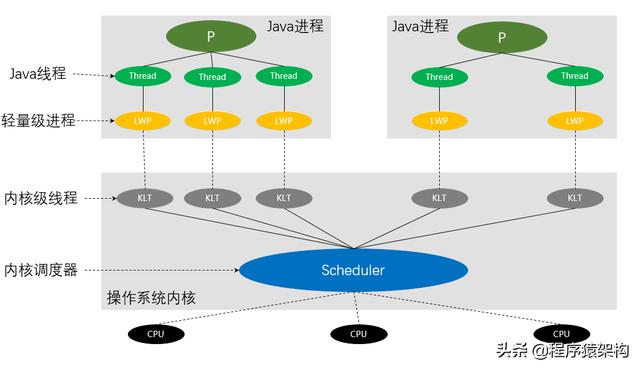
Java线程的实现方式是通过操作系统提供的高级编程接口——LWP(轻量级进程)来对应到内核线程上的,一个Java线程对应到一个LWP,对应到一个KLT(内核线程)。当Java线程阻塞,需要调度时,由内核调度器来进行切换,把当前KLT-LWP对应的Java线程切换到另一个Java线程,这种切换操作在内核态中进行,这种切换是很耗时的(相对CPU来说)。Java的一个线程对应到一个内核线程,一般创建Java线程占用的内存都大于1M。
Go语言使用了用户级线程的实现方式,Go语言中的goroutine可以理解为用户态的线程,调度切换goroutine直接在用户态进行,不用切换到内核态。
Go 调度器模型我们通常叫做GPM 模型,包括 4 个重要结构:
- G:Goroutine,每个 Goroutine 对应一个 G 结构体,我们使用go关键字创建goroutine,并非就一定创建了G结构体的实例,只有当没有可用的G时,才会创建G来装载我们创建的goroutine,否则,会复用现有可用的G来装载goroutine。G 存储 Goroutine 的运行堆栈、状态以及任务函数,可重用。G 并非执行体,每个 G 需要绑定到 P 才能被调度执行。
- P: Processor,表示逻辑处理器,对 G 来说,P 相当于 CPU 核心,G 只有绑定到 P 才能被调度。对 M 来说,P 提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等。P 的数量决定了系统内最大可并行的 G 的数量(前提:物理 CPU 核数 >= P 的数量)。P 的数量由用户设置的 GOMAXPROCS 决定,但是不论 GOMAXPROCS 设置为多大,P 的数量最大为 256。
- M: Machine,OS 内核线程抽象,代表着真正执行计算的资源,在绑定有效的 P 后,进入 schedule 循环;而 schedule 循环的机制大致是从 Global 队列、P 的 Local 队列以及 wait 队列中获取。M 的数量是不定的,由 Go Runtime 调整,为了防止创建过多 OS 线程导致系统调度不过来,目前默认最大限制为 10000 个。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。
- Sched:Go 调度器,它维护有存储 M 和 G 的队列以及调度器的一些状态信息等。
GPM和Sched的关系如下:
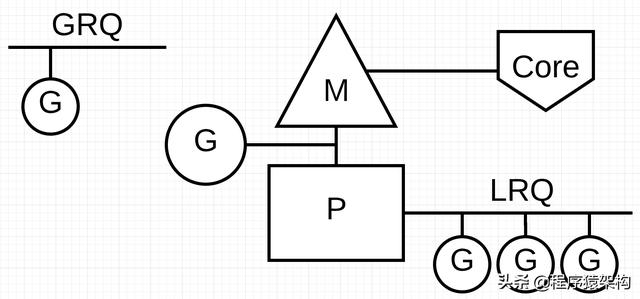
Go语言调度器Sched拥有全局运行队列(GPQ)和P的本地运行队列(LRQ)。GRQ中维护着可以运行但是没有绑定到P的所有goroutine,LRQ中维护着绑定到P的可运行的所有goroutine。可以看到,上图中有一个绑定到P的goroutine正在M上运行,M对应到操作系统内核线程。
当正在M上运行的G在某些情况阻塞时,Sched可以直接把P上其他可运行的G调度进来,这种调度操作在用户态进行,十分轻量级。而且,Go语言中创建的goroutine只需要大约占用2KB的内存,比Java中线程占用空间小多了。因此,Go语言程序可以轻松hold住百万goroutine的调度运行。
GPM源码和Sched源码如下,从源码中,我们更能清楚GPM之间的关系:
G
G中会保存goroutine运行函数,goroutine的id,还有被绑定运行的M的指针:
struct G {
uintptr stackguard; // 分段栈的可用空间下界
uintptr stackbase; // 分段栈的栈基址
Gobuf sched; //进程切换时,利用sched域来保存上下文
uintptr stack0;
FuncVal* fnstart; // goroutine运行的函数
void * param; // 用于传递参数,睡眠时其它goroutine设置param,唤醒时此goroutine可以获取
int16 status; // 状态Gidle,Grunnable,Grunning,Gsyscall,Gwaiting,Gdead
int64 goid; // goroutine的id号
G* schedlink;
M* m; // for debuggers, but offset not hard-coded
M* lockedm; // G被锁定只能在这个m上运行
uintptr gopc; // 创建这个goroutine的go表达式的pc
...
};
P
P中含有本地运行队列LRQ,P当前的状态:
struct P {
Lock;
uint32 status; // Pidle或Prunning等
P* link;
uint32 schedtick; // 每次调度时将它加一
M* m; // 链接到它关联的M (nil if idle)
MCache* mcache;
G* runq[256];
int32 runqhead;
int32 runqtail;
// Available G's (status == Gdead)
G* gfree;
int32 gfreecnt;
byte pad[64];
};
M
M中包含了绑定到M的P的指针,正在M上运行的G的指针,M的状态等等:
struct M {
G* g0; // 带有调度栈的goroutine
G* gsignal; // signal-handling G 处理信号的goroutine
void (*mstartfn)(void);
G* curg; // M中当前运行的goroutine
P* p; // 关联P以执行Go代码 (如果没有执行Go代码则P为nil)
P* nextp;
int32 id;
int32 mallocing; //状态
int32 throwing;
int32 gcing;
int32 locks;
int32 helpgc; //不为0表示此m在做帮忙gc。helpgc等于n只是一个编号
bool blockingsyscall;
bool spinning;
Note park;
M* alllink; // 这个域用于链接allm
M* schedlink;
MCache *mcache;
G* lockedg;
M* nextwaitm; // next M waiting for lock
GCStats gcstats;
...
};
Sched
Sched包含当前空闲的Md指针,当前空闲的P的指针,全局运行队列GRQ等等:
struct Sched {
Lock;
uint64 goidgen;
M* midle; // idle m's waiting for work
int32 nmidle; // number of idle m's waiting for work
int32 nmidlelocked; // number of locked m's waiting for work
int3 mcount; // number of m's that have been created
int32 maxmcount; // maximum number of m's allowed (or die)
P* pidle; // idle P's
uint32 npidle; //idle P的数量
uint32 nmspinning;
// Global runnable queue.
G* runqhead;
G* runqtail;
int32 runqsize;
// Global cache of dead G's.
Lock gflock;
G* gfree;
int32 stopwait;
Note stopnote;
uint32 sysmonwait;
Note sysmonnote;
uint64 lastpoll;
int32 profilehz; // cpu profiling rate
}


