无论是 线程池 还是协程池,都是对资源的池化管理,所谓池化管理就是将具有相同功能的资源集中放在一起、成为资源池,在需要使用该功能时,从该资源池中获取所需大小的资源,进行使用,当使用结束后,在将资源归还给资源池,该过程可成为资源池化。资源池化是一个IT术语,是实现许多的客户端程序复用同一种资源的机制,而不用在每个客户端需要资源时去重新创造他们。而资源池化理的往往具有如下优势:
- 实现对同一种资源的集中的、高效的管理,可轻松快速地实现对资源的扩展或收缩。比如redis集群,其实便是对内存资源的池化管理,方便根据需求扩展或收缩
- 有利于资源的共享和复用、在需要时请求资源,用完后规划,实现了不同的使用者对统一资源的使用。例如数据库的网络连接池,不同 线程 的程序需要发送数据时请求获取连接,发送数据结束后归还连接。
- 对于资源的创建和销毁比较耗费资源的场景,资源池的”ready for use”的特性可有效提升性能。如网络的链接和线程的创建都是比较耗费资源的过程,采用资源池可提升其性能。
Java 为什么需要线程池
对于Java开发人员来时,凡是涉及到并发编程的地方,势必会想到使用线程池。Java线程池也是Java标准库中的非常重量级的成员,是每一位开发者都必须掌握和深入了解的组件。由此可看出Java线程池的存在是毫无悬念地有必要。那么我们接下来就来探讨下,为什么Java线程池是这么的有必要。
一个线程是一个处理器对应着一组指令的执行上下文。多个线程便可实现多任务的并发执行。在Java中,每一个Java线程都会对应着一个系统线程。
线程的创建和销毁可能会有比较高的花费(CPU时间和内存),如果我们在每次执行任务的时候都重复创建和销毁的过程,特别对于轻量级的任务,这将造成极大地资源浪费。

线程切换
线程的切换
同时线程的切换也同样是消耗资源的操作。如上图所示,当每个线程获取的CPU时间T都可分为上下文切换耗时时长A和任务执行时长B。当用户拥有海量的任务等待执行时,如果我们针对每一个任务都开启一个线程去执行,那么将会有大量的线程来竞争CPU资源,并且会占据大量的内存(每个线程都有自己的线程栈内存,oracle jdk默认貌似是512KB)。这时即使我们不考虑内存问题,那么由于竞争的原因,每个线程获取的CPU时间T将大大减少,而线程上下文切换的时间A则不会减少的,因此任务的执行时间B将被大大压缩,因此可能会出现CPU的绝大部分的计算资源全都用在了上下文切换上,根本没时间去管你的任务!所以在实践中我们往往将线程的数量限制在CPU内核数量的2倍左右。
从上面的两种情况我们便看出了Java线程池的必要性,Java线程池的模型一般如下图所示。

Java线程池模型
线程池是一组预先创建好的线程组,时时刻刻等待着任务的到来,并执行它们,图中每个绿色的正方形代表一个线程。无论是否有任务,总有一些线程始终存在,这样我们就不用在每次任务执行前去创建一个线程了。如图所示,当有新任务需要交由线程池执行时,就把任务放入任务队列,线程组会不断的从任务队列中取出任务并执行。在这里可能会根据任务的情景不同、优先级不同选择合适任务队列,但是模型都是一致的。
golang的协程
在golang中当涉及到使用并发操作,一般使用
来创建一个并发任务,这个并发任务是由新创建的协程来完成。golang中并没有对开发者可见的线程的概念,所有的并发操作均有协程来完成。开发者唯一可对系统级线程控制的地方便是如下这两个方法。前者用设置应用能使用的Process Context的最大个数(go1.5之后默认等于CPU核数),后者是用来设定应用最多能运行在多少个系统线程之上(go1.5之后默认值是10000)。
runtime .GOMAXPROCS(1)
debug.SetMaxThreads(10000)
由此可见其实golang本身在运行是已经限制了最大可使用的线程数量,也就是说无论我们使用多少go func()语句创建协程,其底层使用的系统级线程的数量始终不会超过我们设定的最大值,因此golang不会出现上文所说的由于过度开辟新线程而导致CPU的负载绝大部分用于上下文切换的情况。
无论如何golang程序最终还是运行在系统之上,因此其所有的并发操作最终还是要落地在系统级线程之上。所有有必要了解协程与系统级线程的关系。
golang的MPG模型
无论语言层面使用怎样的并发模型,到了操作系统层面最终以系统级线程的形态存在。而操作系统根据访问资源权限的不同,有内核空间和用户空间之分。内核空间存放内核代码和数据,主要操作访问CPU资源、I/O资源、内存资源等硬件资源,为上层应用程序提供最基本的基础资源。用户空间存放的是用户程序的代码和数据,不能直接访问硬件资源,可通过系统调用、shell脚本等方式访问内核空间。
高级语言往往会对内核线程进行封装,其方式有纯内核线程实现(1:1),纯用户态线程实现(1:N)和混合实现(M:N)。纯内核线程实现将用户线程与内核线程一一对应,用户线程简单的对内核线程进行封装、实现简单,并且能充分利用机器多CPU核的优势,充分借用内核的高效调度,但是线程的上下文切换以及用户空间与内核空间的切换较慢。纯用户态线程实现将一个内核线程映射为多个用户线程,这样用户线程的context切换将会非常快,但是需要自己实现维护调度器,实现复杂,并且由于内核不了解调度细节,很难进行多核利用。golang则充分结合这两种实现方式的优点,实现了M:N的调度器。它可以调度任意数量的协程跑在任意数量的内核线程上。即能实现快速的context切换,又能充分利用多核的优势。其缺点便是实现复杂,但是这些对普通开发者是不可见的,普通开发者不需要操心实现复杂的事儿。下图便是M:N线程模型示意图,在N个内核线程中可任意运行M个用户线程,在这幅图中容易看出这里内核线程与用户线程的关系如同worker与task的关系,从这个角度来看,这其实就是一种线程池。

golang则充分利用了M:N线程模型的优势,它可以在任意数量的系统线程之上运行并调度任意数量的goroutine。在实现M:N线程模型的过程中,golang主要采用 M(Machine)、P(Processor)、G(Goroutine) 三个实体,并且有一个调度器schedt维护这三种的实例及三种实体间的关系。
M: 用户指令集的实际执行体,一个M代表一个内核线程
P: P 是 G 能够在 M 中运行的关键,是协程调度的上下文,可以将其视为一个调度器的本地化版本,使在单个线程上运行不同任务的go代码。同时也作为本地资源池和G任务池。P能够解耦G和M,增加G-to-P,P-to-M的内聚。并且使得任务队列去中心化,减少了M获取G任务时的锁竞争。P看起来像是给M和G牵线搭桥的媒婆,但是这个“媒婆”会提供运行所需要的一些资源,并保存着G的调度信息。
G: 一个G代表一个goroutine,包括栈、指令指针以及其他有关协程调度的信息,比如或许被阻塞的所有channel。它协程任务的信息单元
schedt: 调度器,维护有空闲的M队列、空闲的P队列,全局的G队列,及调度器的一些状态信息等。
下图是展示MPG关系的非常经典的一张图,图中有两个线程(M),每个线程都拥有一个上下文(P),每个线程都正在运行一个goroutine(G)。为了运行goroutines,一个线程必须拥有一个上下文(P)。上文所讲的GOMAXPROCS便是设定系统在运行中所能使用的上下文P的数量,通常程序运行时,这个值不会改变。这意味着在同一时刻,最多有GOMAXPROCS套go代码并行执行(这里是并行,不是并发,并发数不受此限制,可以有更多)。灰色的goroutine是已经准备好被调度,但是还未被执行,它们被放在名为runqueue的列表中,执行go语句创建的goroutine或者正在执行的gorourine的时间片用尽时,就会被放在该列表的末尾。一旦一个上下文P运行一个goroutine到一个调度时间点,将会从runqueue中pop出一个goroutine,并设置栈和PC指针,开始运行这个goroutine。
为了降低mutex竞争,每一个上下文都有它自己的本地runqueue。Go调度器曾经的一个版本只有一个通过mutex来保护的全局runqueue,线程们经常被阻塞来等待mutex被解除阻塞。当你有许多32核的机器而且想尽可能地压榨它们的性能时,情况就会变得相当坏。

MPG关系示意图
你可能会想到能不能直接把runqueue存到线程上,从而抛弃上下文P?答案是不行,我们用上下文的原因是如果正在运行的线程因为某种原因需要阻塞的时候,我们可以把这些上下文移交给其它线程。比如当发生系统调用、网络请求等都goroutine都会阻塞。例如如下图所示的场景:

阻塞协程调度示意图
线程M0与P绑定执行G0时,发生了系统调用或者I/O操作。这时M0与G0绑定等待这操作的完成(根据系统原理,等待的操作也必须发生在系统线程中)。此时为了充分利用CPU,让用户的Go代码继续执行,就需要将M0放弃它的上下文,即让M0与P解除绑定,让另一个的系统线程M1与P绑定,继续执行P中的G队列。调度器能确保有足够的线程来运行所有的上下文P。上图中的M1 可能仅仅是为了让它执行P中的任务新创建的,也可能来自一个线程缓存(thread cache)。线程M0将继续等待着这个发生系统调用的goroutine。从技术上来说,这个协程虽然阻塞在OS里,但是仍然在执行。
同时,Golang为了调度的公平性,在调度器加入了steal working 算法 ,在一个P自己的执行队列,处理完之后,它会先到全局的执行队列中偷G进行处理,如果没有的话,再会到其他P的执行队列中抢G来进行处理。
runtime.schedule() {
// only 1/61 of the time, check the global runnable queue for a G.
// if not found, check the local queue.
// if not found,
// try to steal from other Ps.
// if not, check the global runnable queue.
// if not found, poll network.
}
这种情况发生在一个P中的所有G任务全部执行完的时候, 如果此时P停止工作的话,可能会出现其他的P还有很多的G没有执行完,而有些执行完自己的G队列的P无事可做。所以steal working便为了解决这个问题。如下图所示,当一个P的可执行G队列为空时,它会按照runtime.schedule()所描述的过程,从其他队列“偷取”一部分G任务来接着执行。

协程 stealing work
通过上边的讲解可知,golang的MPG模型与Java的线程池模型有很多相似的地方,但是要比Java的线程池模型强大很多和高效很多。golang中的G队列相当于Java线程池中的task队列,Java中的线程池则由golang中的M队列与之对应,它们都是模型的执行单元。Java的线程池模型通过线程池的各个线程经过激烈的竞争全局锁来获取任务。而golang则把任务分成了两级,第一级是全局的可执行G队列,第二级是各个P独自战友的本地G队列。从全局G队列获取任务时,需要锁竞争,但是一个P从本地的G队列获取任务时不需要锁竞争,从而大大减少的竞争的发生,从而极大地提高了高并发场景下的效率。Java中的task不存在被调度的情况,只能按照某种特定的规则顺序的被执行。golang中的G任务有自己的调度系统,一个G任务占用CPU时间过长时会被其他G任务抢占,并将被强占的G放到P的G任务队列队尾,等待调度执行。默认情况下抢占调度时间为10ms。另外golang中的很多库函数都会触发G的调度,而不是依赖系统线程的调度,从而极大地提高了任务的切换效率。
下面这张图从其他地方是从tonybai这位大神的博客上粘过来的,非常好的概括了golang的MPG模型。我们的计算机硬件提供了物理CPU核,Linux系统会管理和调度这些硬件,并将这些资源抽形成系统线程提供给用户,golang将这些系统线程包装成M。而golang的P则招聘M来执行本地的G任务队列。当G任务中有系统调用,I/O操作这类的阻塞调用时,P便安排当前的M去一对一照看着这个G,然后重新招聘一个M接着去执行剩下的G任务队列。当本地的G任务队列执行完毕时,便去Global G队列或者其他的P中的G队列中“偷”一部分G过来,接着让P当前招聘的M干活。
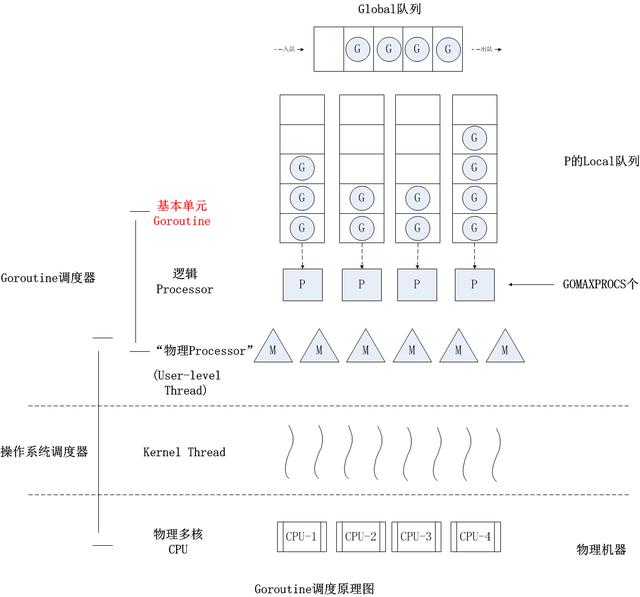
golang MPG模型
结论
一般来说,当我们不需要对并发的任务数量进行精确控制时,不需要使用协程池。例如,在处理用户请求这种典型的使用场景中,如果每次用户请求需要触发一些异步任务时,只需要使用go func()启动异步任务即可,不需要使用协程池来额外的管理协程。即使有控制用户请求并发数的需求,也应该在系统的入口处对用户的请求进行限流。总而言之,使用go func()开启协程处理异步任务很难会成为系统的瓶颈,协程的调度也不会占用太多的计算机资源。当然如果是业务上需要控制最大的并发任务数,可以考虑使用协程池,也可以使用golang提供的sync.WaitGroup来实现控制最大并发任务数,不过在这种场景下,考虑性能就没有意义了。
参考文献
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8] ~cs561/cs450/ChilkuriDineshThreads/dinesh%27s%20files/User%20and%20Kernel%20Level%20Threads.html
[9]
[10]~jbell/CourseNotes/OperatingSystems/4_Threads.html


