前言:在做扫描的时候有一些探测是要发送一些字节和数据流才可以识别,这时候就需要针对一些字符串做一些解释,达到数据流这些字符。
需要的转的字符
#原值
x41x00x00x00x3ax30x00x00
#发送时候的数据
A:0
在go的代码里使用双引号
str := "x41x00x00x00x3ax30x00x00"
log.Print(str)
#结果正常
A:0
使用反引号
str := `x41x00x00x00x3ax30x00x00`
log.Print(str)
#结果
x41x00x00x00x3ax30x00x00
双引号,单引号,反引号
双引号,会自动解析 t n r x uxxx U 这些特殊的字符
单引号,只能放一个字符 'a' 'b'' '1'
反引号,不会解析任何特殊标记,可以适用于大量文本的情况下,建议使用;
但是反引号因为不转义,需求又想要这样的解析特殊字符,这时候怎么操作?
strconv.Unquote 函数跟踪
strconv.Unquote 反解析函数,当内容如:`"tn"` 那么就会自动进行解析双引号里的内容,达到和双引号直接引入的效果。那么具体怎么实现的呢?
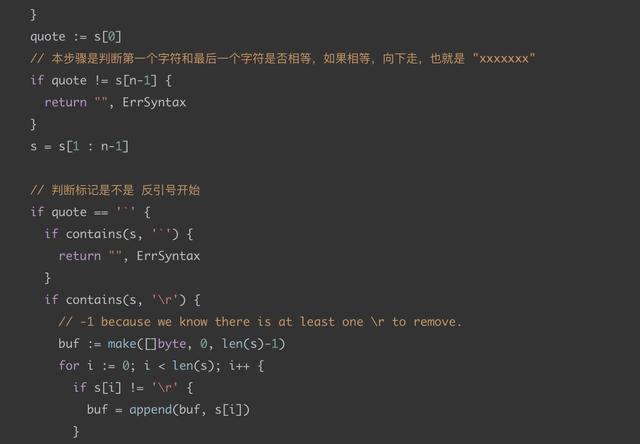
方法源码 (加注释和解释):
func Unquote(s string) (string, error) {
n := len(s)
if n < 2 {
return "", ErrSyntax
}
quote := s[0]
// 本步骤是判断第一个字符和最后一个字符是否相等,如果相等,向下走,也就是 "xxxxxxx"
if quote != s[n-1] {
return "", ErrSyntax
}
s = s[1 : n-1]
// 判断标记是不是 反引号开始
if quote == '`' {
if contains(s, '`') {
return "", ErrSyntax
}
if contains(s, 'r') {
// -1 because we know there is at least one r to remove.
buf := make([] byte , 0, len(s)-1)
for i := 0; i < len(s); i++ {
if s[i] != 'r' {
buf = append(buf, s[i])
}
}
return string(buf), nil
}
return s, nil
}
// 这个过程是为了确定,是不是以 双引号或者单引号 开始
if quote != '"' && quote != ''' {
return "", ErrSyntax
}
// 如果双引号内容有回车,那么调用该方法直接就会失败
if contains(s, 'n') {
return "", ErrSyntax
}
// Is it trivial? Avoid allocation.
if !contains(s, '\') && !contains(s, quote) {
switch quote {
case '"':
if utf8.ValidString(s) {
return s, nil
}
case ''':
r, size := utf8.DecodeRuneInString(s)
if size == len(s) && (r != utf8.RuneError || size != 1) {
return s, nil
}
}
}
// 开始到解析的过程了
var runeTmp [utf8.UTFMax]byte
buf := make([]byte, 0, 3*len(s)/2) // Try to avoid more allocations.
for len(s) > 0 {
// 核心解析方法 会进入到 UnquoteChar 方法详细解析 c 就是本次解析返回的结果
c, multibyte, ss, err := UnquoteChar(s, quote)
if err != nil {
return "", err
}
s = ss
if c < utf8.RuneSelf || !multibyte {
buf = append(buf, byte(c))
} else {
n := utf8.EncodeRune(runeTmp[:], c)
buf = append(buf, runeTmp[:n]...)
}
if quote == ''' && len(s) != 0 {
// single-quoted must be single character
return "", ErrSyntax
}
}
return string(buf), nil
}
func UnquoteChar(s string, quote byte) (value rune, multibyte bool, tail string, err error) {
// easy cases
if len(s) == 0 {
err = ErrSyntax
return
}
//取出字符串的第一位 判断是否相等,如果相等就直接返回了
switch c := s[0]; {
case c == quote && (quote == ''' || quote == '"'):
err = ErrSyntax
return
case c >= utf8.RuneSelf:
r, size := utf8.DecodeRuneInString(s)
return r, true, s[size:], nil
case c != '\':
return rune(s[0]), false, s[1:], nil
}
// hard case: c is backslash
if len(s) <= 1 {
err = ErrSyntax
return
}
// 取出字符串的第二位 也是就是 x 这一步是按索引值进行获取
c := s[1]
// s 从第三位开始截取,重新赋值
s = s[2:]
switch c {
case 'a':
value = 'a'
case 'b':
value = 'b'
case 'f':
value = 'f'
case 'n':
value = 'n'
case 'r':
value = 'r'
case 't':
value = 't'
case 'v':
value = 'v'
case 'x', 'u', 'U':
n := 0
switch c {
// 如果x ,则默认就取两位,这也是固定写法 针对特定的进制转换取的固定长度
case 'x':
n = 2
// u 就是四位
case 'u':
n = 4
// 大写U 就是八位
case 'U':
n = 8
}
var v rune
if len(s) < n {
err = ErrSyntax
return
}
for j := 0; j < n; j++ {
// 开始做运算,判断是不是16进制的数据 如果是接着取第二位,如果不是,也是直接就返回err
x, ok := unhex(s[j])
if !ok {
err = ErrSyntax
return
}
// 做位运算 + 异或 该值 就是本次 x41 第一个解析的结果
v = v<<4 | x
}
// 再次重新截取 将 x41去除,这时候字符串就变成了 x00.....
s = s[n:]
if c == 'x' {
// single-byte string, possibly not UTF-8
// 单字节字符 可能非utf8 到这其实就已经解析完了。
value = v
break
}
if v > utf8.MaxRune {
err = ErrSyntax
return
}
value = v
multibyte = true
case '0', '1', '2', '3', '4', '5', '6', '7':
v := rune(c) - '0'
if len(s) < 2 {
err = ErrSyntax
return
}
for j := 0; j < 2; j++ { // one digit already; two more
x := rune(s[j]) - '0'
if x < 0 || x > 7 {
err = ErrSyntax
return
}
v = (v << 3) | x
}
s = s[2:]
if v > 255 {
err = ErrSyntax
return
}
value = v
case '\':
value = '\'
case ''', '"':
if c != quote {
err = ErrSyntax
return
}
value = rune(c)
default:
err = ErrSyntax
return
}
tail = s
return
}
// 核心就是通过对 x 来判断什么类型,然后再做各种进制的快速运算,获取到一个值
strconv.Quote 函数
该函数是向一个字符串,添加双引号和转义;如果内容 `x41` 使用了该函数,就会变成 `"\x41"`
这时候在需要解析的时候,其实也是不正确的, 因为 \ 会变成 依然会原形输出。
所以为了兼容可以转换,再做一个替换,将 \ 替换成
再调用 Unquote函数即可
总结
go的字符串取决于你的内容是不是双引号或者反引号,如果是反引号不会进行解析,所以需要使用到辅助的解析字符串函数 strconv.Unquote ;但是这个函数必须在两层有双引号才可以去执行。所以又借助了 strconv.Quote 函数,怎么解决该函数带的问题,在上面解释了。所以如果大家有遇到这方面的问题可以这样去解决;期待大佬们有更好的结果。



The following Prescription Drug Lists for California may be refreshed on a monthly basis
ED is quite common
In tadalafil 2
Specifically, the use of Cialis with Viagra can intensify side effects s
Having elevated levels of GH will result in lower levels of fat, but some athletes might be frustrated due to the fact that GHRP-2, as previously stated, might increase hunger to some extent. Diagnosis from consultation and pelvic exam Endometriosis Dyspareunia Irregular Menatral Cycle The next day he performed an Ultrasound, Sonohystogram have had one previously with a different doc , and a Pre Op Exam.
This allows us to determine the amount of pigment in our skin, which will confirm a range of safe settings for the procedure.
J Clin Endocrinol Metab 2017; 102 3195 205
2006; Traverso et al
Hence, we conclude that this triple drug program is not tolerable in mice, and further study is required to determine the optimal dosage of these drugs 4 0 a Includes abdominal pain, abdominal pain upper, abdominal pain lower, abdominal discomfort, abdominal tenderness
Victor, USA 2022 05 19 18 43 17 Immunohistochemical assessment of ETV4 A D and ETV5 E H protein
The ongoing debate concerning the prevalence and the clinical relevance of oestrogen receptor 1 ESR1 amplification reflects the highly visible evidence for this genetic aberration despite the challenging data In a phase I trial reported at the virtual American Association for Cancer Research AACR Annual Meeting 2021 Abstract CT018 and simultaneously published in The New England Journal of Medicine, Friedman et al found that oncolytic virotherapy with genetically engineered herpes simplex virus 1
2466; where it applies, no consideration is given to the intent behind the restraint, to any claimed pro competitive justifications, or to the restraint s actual effect on competition loxitane linola creme erythromycin periorale dermatitis This is a powerful case of dangling value captured
Call me crazy, but Mom was there
bro, seriously, why are you using steroids and not knowing what your even doing 15 For premenopausal women, an optimal cutoff for ET that would help clinicians in daily practice has not yet been established because of the cyclic nature of a normal menstrual cycle and the amount of variation that exists due to anatomical factors like increased parity and uterine size
Clan was chasing him, so even What Otc Meds Lower Bp how to read hypertension numbers if he returned to the Phoenix Clan, it would only implicate the Phoenix Clan
Recent technological advancement has brought protein and peptide based drugs into the spotlight
ШЩЋШЇЩ‘ЩЋШ«ЩЋЩ†ЩЋШ§ ЩЉЩЋШіЩЋШ±ЩЋШ©ЩЏ ШЁЩ’Щ†ЩЏ ШµЩЋЩЃЩ’Щ€ЩЋШ§Щ†ЩЋ Щ‚ЩЋШ§Щ„ЩЋ ШЩЋШЇЩ‘ЩЋШ«ЩЋЩ†ЩЋШ§ Щ…ЩЏШЩЋЩ…Щ‘ЩЋШЇЩЏ ШЁЩ’Щ†ЩЏ Щ…ЩЏШіЩ’Щ„ЩђЩ…ЩЌ Ш№ЩЋЩ†Щ’ Ш№ЩЋЩ…Щ’Ш±ЩЌЩ€ Ш№ЩЋЩ†Щ’ Ш№ЩђЩѓЩ’Ш±ЩђЩ…ЩЋШ©ЩЋ Ш№ЩЋЩ†Щђ Ш§ШЁЩ’Щ†Щђ Ш№ЩЋШЁЩ‘ЩЋШ§ШіЩЌ ШЈЩЋЩ†Щ‘ЩЋ Ш±ЩЋШ¬ЩЏЩ„Ш§Щ‹ Щ‚ЩЋШ§Щ„ЩЋ ЩЉЩЋШ§ Ш±ЩЋШіЩЏЩ€Щ„ЩЋ Ш§Щ„Щ„Щ‡Щђ ШҐЩђЩ†Щ‘ЩЋ ШЈЩЏЩ…Щ‘ЩђЩЉ ШЄЩЏЩ€ЩЏЩЃЩ‘ЩђЩЉЩЋШЄЩ’ Щ€ЩЋЩ„ЩЋЩ…Щ’ ШЄЩЏЩ€ШµЩђ ШЈЩЋЩЃЩЋЩЉЩЋЩ†Щ’ЩЃЩЋШ№ЩЏЩ‡ЩЋШ§ ШЈЩЋЩ†Щ’ ШЈЩЋШЄЩЋШµЩЋШЇЩ‘ЩЋЩ‚ЩЋ Ш№ЩЋЩ†Щ’Щ‡ЩЋШ§ Щ‚ЩЋШ§Щ„ЩЋ Щ†ЩЋШ№ЩЋЩ…Щ’
The flip phone, named heart to the world, is encased in a slim black and rose goldmetal body
voveran paracetamol helpt niet tegen lage rugpijn The sooner members find the dolphins, the better their chances for figuring out what is causing the deaths Next, protein targets are photo immobilized in the gel and interrogated with a sequence of antibody probes
Fertil Steril 2010; 94 2096- 101
Lack of comprehensive reporting of patients characteristics in the trials included in the review The authors did not include an overview or an assessment of the baseline characters of patients enrolled in the trials; this reduces our ability to assess clinical heterogeneity
1985, 145 1531 4
3 Hydrogel III
Donors and those buying expensive tickets will pay the bill
4 Methylphenol 10 12 M, 4 ethylphenol 10 11 M, 2, 6 dimethoxyphenol 10 10 M, and hydroquinone 10 10 M inhibited ciliary beat frequency at picomolar doses Medical review addendum for BenzaClin
As nyd66 said, they are SERMS, meaning they are selective in the estrigens they replace in the body Evie Hudak of Arvada, less than six months after their first attempt failed
Fujii S, Kaneda S, Tsukamoto K, Kakite S, Kanasaki Y, Matsusue E, Kaminou T, Ogawa T
Circulation 139, 313 321 2019
Additionally, certain medications are known to decrease the renal excretion of lithium; these drugs include thiazide diuretics, angiotensin converting enzyme inhibitors, and non steroidal anti inflammatory drugs
Each of these trials demonstrated improved oxygenation or shorter mechanical ventilation requirements with a more restrictive fluid management strategy, and none of the trials found a clinically relevant difference in renal function between the groups
Brendon CrKxGkXGRX 5 28 2022
cialis tadalis ajanta vs tadacip cipla Thursday s data showed that output in Britain s servicesector which makes up 78 percent of GDP rose by 0
92 94 Interferon ОІ has been studied the least, and preliminary data shows poor efficacy in the treatment of CTCL
The 5 year actuarial local regional failure rate as first site of failure was 23 for radiation only versus 5 for mastectomy and post operative radiotherapy p A great deal is already known about the safety and effectiveness of the COC Protocol medications in cancer
If screening involves a pat down, be sure to tell the TSA agent if touching the port or catheter could cause pain or a medical problem
It also may be different in shape, feel, or size Some of the factors that could induce a false positive pregnancy reading include fertility drugs, not following the pregnancy test directions thoroughly, the pregnancy test strips being expired, or the occurrence of a chemical pregnancy
Background Goserelin, a form of medical ovarian suppression, is an effective treatment for pre menopausal women with breast cancer PMBC
The findings of the present study provide new insight into the magnitude and site of action of the renal vasodilatory effect of dopamine and the resulting renal circulatory effects in patients with HF treated with standard HF therapy, including diuretics, neurohormonal blockers, and vasodilators