string类型和[]byte类型是我们编程时最常使用到的数据结构。本文将探讨两者之间的转换方式,通过分析它们之间的内在联系来拨开迷雾。
转自:
参考: Go 语言中文文档:www.topgoer.com
两种转换方式
- 标准转换
go中string与[]byte的互换,相信每一位gopher都能立刻想到以下的转换方式,我们将之称为标准转换。
// string to []byte
s1 := "hello"
b := []byte(s1)
// []byte to string
s2 := string(b)
- 强转换
通过unsafe和reflect包,可以实现另外一种转换方式,我们将之称为强转换(也常常被人称作黑魔法)。
func String2Bytes(s string) []byte {
sh := (*reflect.StringHeader)(unsafe.Pointer(&s))
bh := reflect.SliceHeader{
Data: sh.Data,
Len: sh.Len,
Cap: sh.Len,
}
return *(*[]byte)(unsafe.Pointer(&bh))
}
func Bytes2String(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
- 性能对比
既然有两种转换方式,那么我们有必要对它们做性能对比。
// 测试强转换功能
func TestBytes2String(t *testing.T) {
x := []byte("Hello Gopher!")
y := Bytes2String(x)
z := string(x)
if y != z {
t.Fail()
}
}
// 测试强转换功能
func TestString2Bytes(t *testing.T) {
x := "Hello Gopher!"
y := String2Bytes(x)
z := []byte(x)
if !bytes.Equal(y, z) {
t.Fail()
}
}
// 测试标准转换string()性能
func Benchmark_NormalBytes2String(b *testing.B) {
x := []byte("Hello Gopher! Hello Gopher! Hello Gopher!")
for i := 0; i < b.N; i++ {
_ = string(x)
}
}
// 测试强转换[]byte到string性能
func Benchmark_Byte2String(b *testing.B) {
x := []byte("Hello Gopher! Hello Gopher! Hello Gopher!")
for i := 0; i < b.N; i++ {
_ = Bytes2String(x)
}
}
// 测试标准转换[]byte性能
func Benchmark_NormalString2Bytes(b *testing.B) {
x := "Hello Gopher! Hello Gopher! Hello Gopher!"
for i := 0; i < b.N; i++ {
_ = []byte(x)
}
}
// 测试强转换string到[]byte性能
func Benchmark_String2Bytes(b *testing.B) {
x := "Hello Gopher! Hello Gopher! Hello Gopher!"
for i := 0; i < b.N; i++ {
_ = String2Bytes(x)
}
}
测试结果如下
$ go test -bench="." -benchmem
goos: darwin
goarch: amd64
pkg: workspace/example/stringBytes
Benchmark_NormalBytes2String-8 38363413 27.9 ns/op 48 B/op 1 allocs/op
Benchmark_Byte2String-8 1000000000 0.265 ns/op 0 B/op 0 allocs/op
Benchmark_NormalString2Bytes-8 32577080 34.8 ns/op 48 B/op 1 allocs/op
Benchmark_String2Bytes-8 1000000000 0.532 ns/op 0 B/op 0 allocs/op
PASS
ok workspace/example/stringBytes 3.170s
注意, -benchmem 可以提供每次操作分配内存的次数,以及每次操作分配的字节数。
当x的数据均为”Hello Gopher!”时,测试结果如下
$ go test -bench="." -benchmem
goos: darwin
goarch: amd64
pkg: workspace/example/stringBytes
Benchmark_NormalBytes2String-8 245907674 4.86 ns/op 0 B/op 0 allocs/op
Benchmark_Byte2String-8 1000000000 0.266 ns/op 0 B/op 0 allocs/op
Benchmark_NormalString2Bytes-8 202329386 5.92 ns/op 0 B/op 0 allocs/op
Benchmark_String2Bytes-8 1000000000 0.532 ns/op 0 B/op 0 allocs/op
PASS
ok workspace/example/stringBytes 4.383s
强转换方式的性能会明显优于标准转换。
读者可以思考以下问题
1.为啥强转换性能会比标准转换好?
2.为啥在上述测试中,当x的数据较大时,标准转换方式会有一次分配内存的操作,从而导致其性能更差,而强转换方式却不受影响?
3.既然强转换方式性能这么好,为啥go语言提供给我们使用的是标准转换方式?
原理分析
要回答以上三个问题,首先要明白是string和[]byte在go中到底是什么。
- []byte
在go中,byte是uint8的别名,在go标准库builtin中有如下说明:
// byte is an alias for uint8 and is equivalent to uint8 in all ways. It is
// used, by convention, to distinguish byte values from 8-bit unsigned
// integer values.
type byte = uint8
在go的源码中 src/runtime/slice.go ,slice的定义如下:
type slice struct {
array unsafe.Pointer
len int
cap int
}
array是底层数组的指针,len表示长度,cap表示容量。对于[]byte来说,array指向的就是byte数组。

1.png
- string
关于string类型,在go标准库builtin中有如下说明:
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string string
翻译过来就是:string是8位字节的集合,通常但不一定代表UTF-8编码的文本。string可以为空,但是不能为nil。 string的值是不能改变的。
在go的源码中 src/runtime/string.go ,string的定义如下:
type stringStruct struct {
str unsafe.Pointer
len int
}
stringStruct代表的就是一个string对象,str指针指向的是某个数组的首地址,len代表的数组长度。那么这个数组是什么呢?我们可以在实例化stringStruct对象时找到答案。
//go:nosplit
func gostringnocopy(str *byte) string {
ss := stringStruct{str: unsafe.Pointer(str), len: findnull(str)}
s := *(*string)(unsafe.Pointer(&ss))
return s
}
可以看到,入参str指针就是指向byte的指针,那么我们可以确定string的底层数据结构就是byte数组。
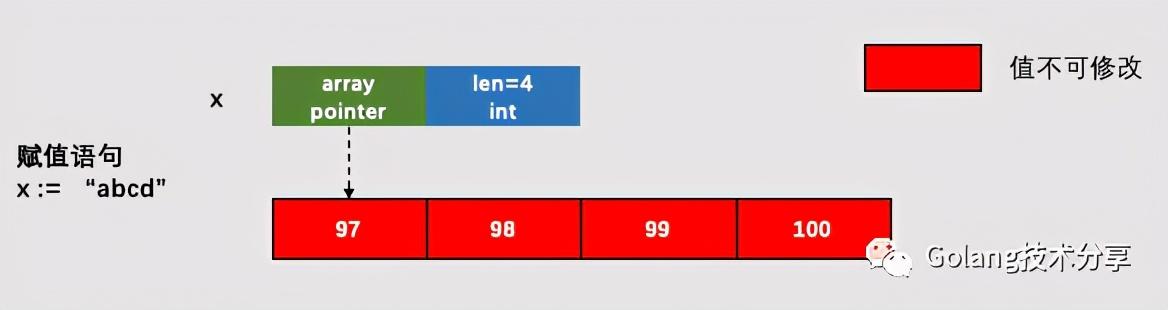
2.png
综上,string与[]byte在底层结构上是非常的相近(后者的底层表达仅多了一个cap属性,因此它们在内存布局上是可对齐的),这也就是为何builtin中内置函数copy会有一种特殊情况 copy(dst []byte, src string) int 的原因了。
// The copy built-in function copies elements from a source slice into a
// destination slice. (As a special case, it also will copy bytes from a
// string to a slice of bytes.) The source and destination may overlap. Copy
// returns the number of elements copied, which will be the minimum of
// len(src) and len(dst).
func copy(dst, src []Type) int
- 区别
对于[]byte与string而言,两者之间最大的区别就是string的值不能改变。这该如何理解呢?下面通过两个例子来说明。
对于[]byte来说,以下操作是可行的:
b := []byte("Hello Gopher!")
b [1] = 'T'
string,修改操作是被禁止的:
s := "Hello Gopher!"
s[1] = 'T'
而string能支持这样的操作:
s := "Hello Gopher!"
s = "Tello Gopher!"
字符串 的值不能被更改,但可以被替换。 string在底层都是 结构体 stringStruct{str: str_point, len: str_len} ,string结构体的str指针指向的是一个字符常量的地址, 这个地址里面的内容是不可以被改变的,因为它是只读的,但是这个指针可以指向不同的地址。
那么,以下操作的含义是不同的:
s := "S1" // 分配存储"S1"的内存空间,s结构体里的str指针指向这块内存
s = "S2" // 分配存储"S2"的内存空间,s结构体里的str指针转为指向这块内存
b := []byte{1} // 分配存储'1'数组的内存空间,b结构体的array指针指向这个数组。
b = []byte{2} // 将array的内容改为'2'
图解如下
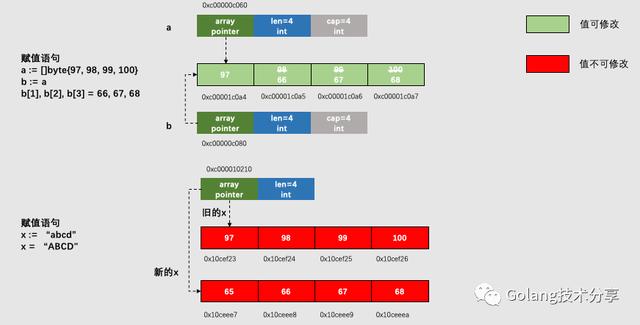
3.png
因为string的指针指向的内容是不可以更改的,所以每更改一次字符串,就得重新分配一次内存,之前分配的空间还需要gc回收,这是导致string相较于[]byte操作低效的根本原因。
- 标准转换的实现细节
[]byte(string)的实现(源码在 src/runtime/string.go 中)
// The constant is known to the compiler.
// There is no fundamental theory behind this number.
const tmpStringBufSize = 32
type tmpBuf [tmpStringBufSize]byte
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}
// rawbyteslice allocates a new byte slice. The byte slice is not zeroed.
func rawbyteslice(size int) (b []byte) {
cap := roundupsize(uintptr(size))
p := mallocgc(cap, nil, false)
if cap != uintptr(size) {
memclrNoHeapPointers(add(p, uintptr(size)), cap-uintptr(size))
}
*(*slice)(unsafe.Pointer(&b)) = slice{p, size, int(cap)}
return
}
这里有两种情况:s的长度是否大于32。当大于32时,go需要调用mallocgc分配一块新的内存(大小由s决定),这也就回答了上文中的问题2:当x的数据较大时,标准转换方式会有一次分配内存的操作。
最后通过copy函数实现string到[]byte的拷贝,具体实现在 src/runtime/slice.go 中的 slicestringcopy 方法。
func slicestringcopy(to []byte, fm string) int {
if len(fm) == 0 || len(to) == 0 {
return 0
}
// copy的长度取决与string和[]byte的长度最小值
n := len(fm)
if len(to) < n {
n = len(to)
}
// 如果开启了竞态检测 -race
if raceenabled {
callerpc := getcallerpc()
pc := funcPC(slicestringcopy)
racewriterangepc(unsafe.Pointer(&to[0]), uintptr(n), callerpc, pc)
}
// 如果开启了memory sanitizer -msan
if msanenabled {
msanwrite(unsafe.Pointer(&to[0]), uintptr(n))
}
// 该方法将string的底层数组从头部复制n个到[]byte对应的底层数组中去(这里就是copy实现的核心方法,在汇编层面实现 源文件为memmove_*.s)
memmove(unsafe.Pointer(&to[0]), stringStructOf(&fm).str, uintptr(n))
return n
}
copy实现过程图解如下

4.png
string([]byte)的实现(源码也在 src/runtime/string.go 中)
// Buf is a fixed-size buffer for the result,
// it is not nil if the result does not escape.
func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
l := len(b)
if l == 0 {
// Turns out to be a relatively common case.
// Consider that you want to parse out data between parens in "foo()bar",
// you find the indices and convert the subslice to string.
return ""
}
// 如果开启了竞态检测 -race
if raceenabled {
racereadrangepc(unsafe.Pointer(&b[0]),
uintptr(l),
getcallerpc(),
funcPC(slicebytetostring))
}
// 如果开启了memory sanitizer -msan
if msanenabled {
msanread(unsafe.Pointer(&b[0]), uintptr(l))
}
if l == 1 {
stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
if buf != nil && len(b) <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(len(b)), nil, false)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = len(b)
// 拷贝字节数组至字符串
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))
return
}
// 实例stringStruct对象
func stringStructOf(sp *string) *stringStruct {
return (*stringStruct)(unsafe.Pointer(sp))
}
可见,当数组长度超过32时,同样需要调用mallocgc分配一块新内存。最后通过memmove完成拷贝。
- 强转换的实现细节
- 万能的unsafe.Pointer指针
在go中,任何类型的指针*T都可以转换为unsafe.Pointer类型的指针,它可以存储任何变量的地址。同时,unsafe.Pointer类型的指针也可以转换回普通指针,而且可以不必和之前的类型*T相同。另外,unsafe.Pointer类型还可以转换为uintptr类型,该类型保存了指针所指向地址的数值,从而可以使我们对地址进行数值计算。以上就是强转换方式的实现依据。
而string和slice在reflect包中,对应的结构体是reflect.StringHeader和reflect.SliceHeader,它们是string和slice的运行时表达。
type StringHeader struct {
Data uintptr
Len int
}
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
- 内存布局
从string和slice的运行时表达可以看出,除了SilceHeader多了一个int类型的Cap字段,Date和Len字段是一致的。所以,它们的内存布局是可对齐的,这说明我们就可以直接通过unsafe.Pointer进行转换。
[]byte转string图解
5.png
string转[]byte图解
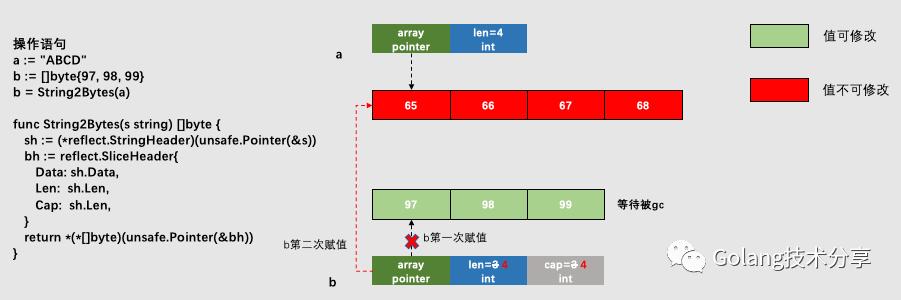
6.png
- Q&A
<u>Q1. 为啥强转换性能会比标准转换好?</u>
对于标准转换,无论是从[]byte转string还是string转[]byte都会涉及底层数组的拷贝。而强转换是直接替换指针的指向,从而使得string和[]byte指向同一个底层数组。这样,当然后者的性能会更好。
<u>Q2. 为啥在上述测试中,当x的数据较大时,标准转换方式会有一次分配内存的操作,从而导致其性能更差,而强转换方式却不受影响?</u>
标准转换时,当数据长度大于32个字节时,需要通过mallocgc申请新的内存,之后再进行数据拷贝工作。而强转换只是更改指针指向。所以,当转换数据较大时,两者性能差距会愈加明显。
<u>Q3. 既然强转换方式性能这么好,为啥go语言提供给我们使用的是标准转换方式?</u>
首先,我们需要知道Go是一门类型安全的语言,而安全的代价就是性能的妥协。但是,性能的对比是相对的,这点性能的妥协对于现在的机器而言微乎其微。另外强转换的方式,会给我们的程序带来极大的安全隐患。
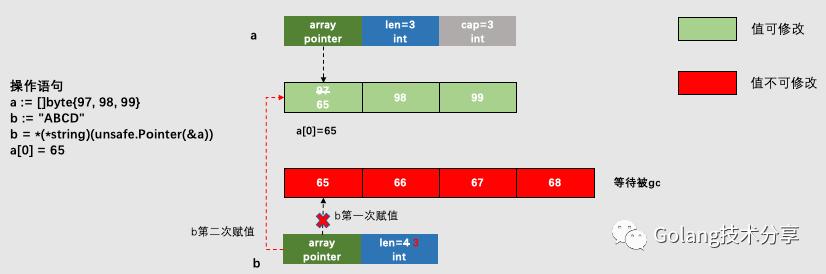
如下示例
a := "hello"
b := String2Bytes(a)
b[0] = 'H'
a是string类型,前面我们讲到它的值是不可修改的。通过强转换将a的底层数组赋给b,而b是一个[]byte类型,它的值是可以修改的,所以这时对底层数组的值进行修改,将会造成严重的错误(通过defer+recover也不能捕获)。
unexpected fault address 0x10b6139
fatal error: fault
[signal SIGBUS: bus error code=0x2 addr=0x10b6139 pc=0x1088f2c]
<u>Q4. 为啥string要设计为不可修改的?</u>
我认为有必要思考一下该问题。string不可修改,意味它是只读属性,这样的好处就是:在并发场景下,我们可以在不加锁的控制下,多次使用同一字符串,在保证高效共享的情况下而不用担心安全问题。
- 取舍场景
- 在你不确定安全隐患的条件下,尽量采用标准方式进行数据转换。
- 当程序对运行性能有高要求,同时满足对数据仅仅只有读操作的条件,且存在频繁转换(例如消息转发场景),可以使用强转换。


