「入群交流:Go中文网 QQ群:731990104 微信群:274768166 备注:头条 微信公众号:Go语言中文网」
如果要构建包含多个实例或者多个丰富数据模式的 Web 应用程序,本地数据存储可能不适用。但是在寻找真正的快速临时存储或者构建自己的副本的时候,本地存储却是需要了解的一个重要的组成模块。
在这篇文章中,我将展示如何在 Go 中使用 Memcached 协议来构建一个名为 Beano 的本地键 / 值对 数据库服务器 ,并且该数据库可以优雅地热交换其整个数据集。
Go 数据存储类库的简单选择
我已经使用过 SQLite,BerkeleyDB 并了解 InnoDB,但出于种种原因,我从来没有像在数据库服务器上那样花费太多精力。
但当我阅读 LevelDB 的设计文档时,其本地数据存储的设计给我留下了深刻的印象:使用 SST 文件和布隆过滤器来减少磁盘使用情况。该 文档 是非常经典的。
像这样的数据库提供了很少的并发管理 – 实际上也很少有管理工具。数据库位于目录中,并且可以由一个进程访问。
这不是什么新的概念:查询模式是 Key/Value:通过一个 Key 来 GET,PUT 或 DELETE 一个值。有一个迭代器接口并加上某种事务或隔离控制。
我使用的选择标准很简单:
- 性能配置是怎么实现的?基于 BTree 变体的数据库将非常适合读取,LSM 树非常适合写入。
- 数据是如何在磁盘上组织的?单个大文件或文件夹?文件范围锁定,这样 Goroutine 可以协调写入或附加数据的 SST 和 WAL 文件并降低锁定负担
- 是 Native Go 代码吗?更容易理解和贡献(坦率地说,我在测试绑定到 LevelDB 的 signals 时遭遇到了挫折)。
- 是否实现了迭代器?是否可以根据某些规则对 keys 进行排序吗?
- 是否实现了事务?虽然不像 RDBMS 事务那般可以并发的提交或者回滚,但是大多数都提供了简单的实现。事务对隔离很有用。
- 压缩,快照和日志是值得探索的有趣功能。
Beano:诞生于解决遗留问题
我正在处理一组遗留应用程序,这些应用程序每天两次新数据出现时就会出现性能问题。该公司有严格的流程和可用性要求,所有应用程序都是在框架中编写的,而如果这些框架改变了数据库实现,这将会在不到一年的时间内无法完成的。我需要快速修改数据集但是不能更改主数据库架构。
改体系结构中的所有元素都使用服务总线,该服务总线具有基于 Memcached 的 缓存 实现。
我们有一个脚本通过运行预定义的查询并在 Memcached 上设置正确的 keys 来预热缓存,由于数据库延迟很高,如果不小心出现问题会导致很多麻烦。
我构建 Beano 的原因是使用缓存改进应用程序是我们在短时间内可以做的最简单的事情。Memcached 中预加载的数据基本上是主数据库模式的非规范化版本。
但在 Beano 之前我尝试实现一种将预定义数据集加载到 Memcached 并在运行时交换它们的方式,有点类似于在 Redis 使用 select 命令的方式。
我的第一次尝试使用了当时非常新的 Memcached 功能:可插拔后端。我为 Memcached 构建了一个 LevelDB 后端,而在它上面是一个毫无意义的 Redis 后端。
这有效但不是我想要的主要是因为那需要比较高的 C 编程水平。我正在学习 Go,并对使用 Go 来实现部分 Memcached 的功能很感兴趣, 如果能够与本地数据库进行耦合,那就更加有趣,所以我看了一下令我印象深刻的新技术:LevelDB。
在与非原生 LevelDB 包装器,信号问题和线程调试进行一些交互以学习 Memcached 协议之后,我创建了一个数据库服务器,当你在通过 Memcached 客户端或者我提供的抽象进行 REST API 通信的时候,可以动态切换数据库。
Beano 的内部实现

最初 Beano 只有一个我想尝试的原生 Go 实现数据库后端。我重构了服务器代码,通过接口接受可插拔的后端。
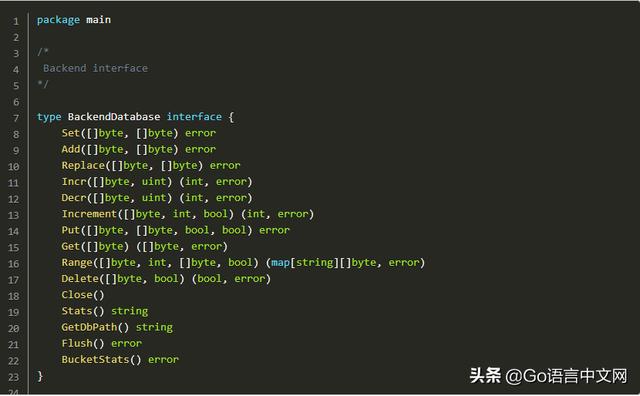
要在新数据存储区后端中实现的所有操作都在 src/backend.go 上定义。这些函数松散地遵循 Memcached 协议。Memcached 协议解析器接受此接口以在后端执行命令。
交换这些后端的过程通过在 src/networking.go 文件中的 messages 的通道进行通信,并与新的和当前活动的连接进行协调。
有一个新的 Memcached 命令,但目前我正在使用 API 路由 /api/v1/switchdb,所以此操作不需要客户端更改。
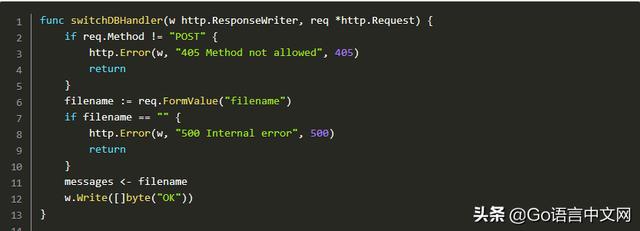
知道后端接口实现的唯一函数是 loadDB,在同一个文件中:

所有后端都由名称标识并接收文件名。有一个内存支持的后端不会使用文件名,但这是通过通道传递的信息,因此它既可以作为更改数据库的信号,也可以作为有效负载的路径。
有一个看门狗 Goroutine 通过通道接收这些消息,并将为新连接准备数据库,并在此之后 accept() 调用(long)协议解析函数的循环:

这就是将网络与后端分开并实现热插拔。协议解析函数知道后端接口,而不是实现细节:
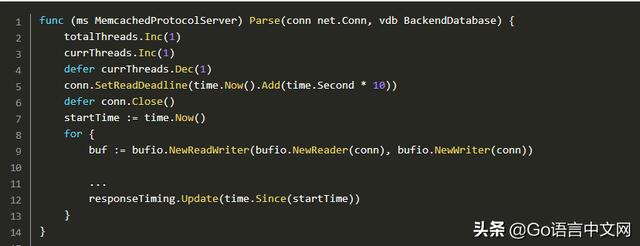
使用该结构,我们可以使用独立 Beano 实例创建一个新数据库,使用预热脚本填充它,通过 rsync 传输或在 S3 上存储以便稍后检索,以便可以安全地交换它们。
数据存储
每个数据库库都有一个围绕事务和迭代器的语义。使用接口隔离它们可以更容易地插入和测试新的后端。
让我们看看 BadgerDB 上的 GET 方法
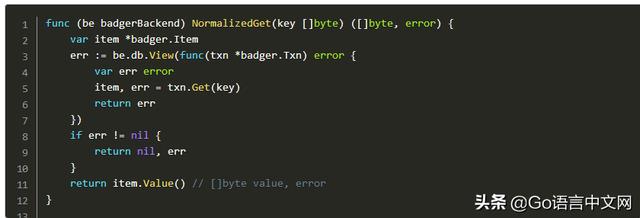
现在通过在 LevelDB 上的 goleveldb ,我使用过的一个库:

有一个关于 levigo 评论,因为在某些时候我使用两个库来提供本机和非本机包装的 LevelDB,并在切换库之前比较性能和安全性。如果找不到 key,某些库将返回空,而 BadgerDB 的其他库将返回详细的错误代码,并且所有库都可以抽象以匹配协议。
BoltDB 在停止并归档后,我保留了实现,以记录这些抽象的可能性。正如我之前提到的,BoltDB 被包装在缓存中,类似于 LevelDB 如何使用名为 bloom filter 的概率数据结构来避免磁盘命中。
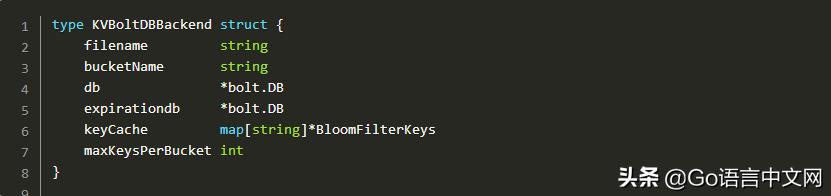
每次 GET 执行时,都必须检查是否获取到了 key。同样的,PUT 和 ADD- 这两个功能也需要使用到 bloom filter。

当启动读取操作时,语句不会直接进入数据库,而是 bf := be.keyCache[be.bucketName].Test(key) 检查 key 是否在某个时间点添加到缓存中。
bloom filter 偏向于误报,但在负数上是可信的,这意味着如果它从未获取过 key,您可以 NOT FOUND 安全返回,而如果它获取到 key 则可能会出现误报结果,这会导致磁盘读取检查并获取。
这有助于运行 LevelDB 和 BoltDB,具有接近的读取性能,同时保持 BoltDB 后端实现的本地细节。
我已经使用了 BoltDB,直到它被归档并在交易时切换到 BadgerDB。我建议使用 BadgerDB,因为可以获得很棒的支持,而且有一个很棒的社区。
结论
我已经展示了一个本地数据存储案例,但有一些更加有趣的应用程序。例如,过滤和检测流上重复数据的连接器,如 segment.io 上的 message de-duplication for kafka ,基于时间序列的软件如 ts-cli 和 Go 中的图形数据库 Dgraph 等。
Beano 的源码位于 github 上 – 欢迎新的想法,问题和 PR。我的计划是寻找新的数据库,并将 Memcached 协议解析出来。
如果您喜欢使用已知协议来执行特定功能,请检查我的 redis 兼容服务器 nazare ,该服务器仅使用 HyperLogLog 实现 PFADD/PFCOUNT。
via:
作者:Gleicon Moraes 译者:lovechuck 校对:polaris1119


