
1.问题现象(2021-01-11)
1月11日下午,线上网关服务api-gateway(golangServer)偶现报 panic 异常,日志如下:
2021/01/11 14:44:23 [ERROR] <middlerwares.go:41> [Recovery]#panic# recovered:POST /user/getUserDeviceList HTTP/1.0
Host: xxx.xxx.xxx.net
Connection: close
Accept-Encoding: gzip
Connection: close
Content-Length: 185
Content-Type: application/x-www-form-urlencoded
User-Agent: beegoServer
X-Forwarded-For: 10.xx.xx.140
X-Real-Ip: 10.xx.xx.140
write tcp 127.0.0.1 :8878->127.0.0.1:52942: write: broken pipe
goroutine 1930665817 [running]:
runtime/debug.Stack(0x0, 0xc4258b43c0, 0x11a)
/home/go/src/runtime/debug/stack.go:24 +0xa7
server/httpserver/ middleware .IntercepteHnadler.func1.1(0xc420dc46e0, 0xc420bbe720, 0x24)
/home/api-gateway/src/server/httpserver/middleware/middlerwares.go:41 +0xbb
panic(0xb07500, 0xc42588d310)
/home/go/src/runtime/panic.go:502 +0x229
vendor/github.com/gin-gonic/gin/render.JSON.Render(0xaef060, 0xc4261ef530, 0x7f00101fb2a8, 0xc425b7ac20, 0xc420dc4600, 0x7f00101fb2a8)
... 报错为: broken pipe ,这个问题归类为客户端 tcp 连接被异常kill掉,导致服务端对 socket 写入时收到了RST响应,二次写入出现了 broken pipe 现象.
2.问题分析
再次查看 nginx 日志,发现日志并未正常导出。
分析当前业务的请求链路:
三方业务 –> nginx –> api-gateway(golang server) –> backend
(1).怀疑nginx子进程由于异常被master进程kill:
但是深究并不合理,一个子进程被kill,会导致该进程的上百个请求报错,同时从 linux 查看nginx的进程启动的时间,发现近期并没有 重启 的子进程
(2).怀疑client请求连接数量,超过nginx配置 worker_connections 值,导致nginx内部tcp连接被nginx进程close.通过监控查看机器当时的qps仅800左右,nginx作为反向代理服务器,需要占用1600个fd描述符:
而nginx的worker_connections配置为1024,共16个nginx子进程,根据 linux命令 :
ps -ef | grep nginx | grep -v grep | grep -v master | awk '{print $2}' | xargs -i ls -l /proc/{}/fd | grep -E "total|socket" | awk 'BEGIN{i=0}{i++;if($1=="total"){print "fd_count:"i;i=0}}END{print "fd_count:"i}' 查看16个子进程的fd数量分布:
fd_count:24
fd_count:28
fd_count:43
fd_count:55
fd_count:78
fd_count:89
fd_count:99
fd_count:108
fd_count:123
fd_count:143
fd_count:160
fd_count:168
fd_count:197
fd_count:202
fd_count:254 #254个socket连接
fd_count:69 根据相关资料: nginx子进程最大client连接为1024/2= 512 左右,仍然可能并不是问题原因。这里做优化点,调整worker_connections配置。
3.解决方案(2021-01-14)
- 1.增加nginx error_log
- 2.增加api-gateway的panic的 request _id
- 3.修改nginx worker_connections连接配置,修改为4096
- 4.修改nginx buffer缓冲区
以上方案于1月14号上线,并继续观察。
4.线上观察(2021-01-16)
通过之前增加的日志,发现nginx报如下error日志:
//nginx机器ip
[yushaolong@p34957v nginx]$ cat error.log
2021/01/16 06:39:07 [warn] 13876#0: 4096 worker_connections exceed open file resource limit: 1024
//nginx机器ip
2021/01/16 04:11:37 [warn] 22449#0: *1022232468 a client request body is buffered to a temporary file /data/nginx/client_body_temp/0000002378, client: xx.77.xx.146, server: xx.xx.xx.cn, request: "POST /wls-wsat/CoordinatorPortType HTTP/1.1", host: "xx.xx.59.100"
2021/01/16 04:11:38 [error] 22449#0: *1022232468 writev() failed (104: Connection reset by peer) while sending request to upstream, client: xx.77.xx.146, server: xx.xx.xx.cn, request: "POST /wls-wsat/CoordinatorPortType HTTP/1.1", upstream: "#34;, host: "xx.xx.59.100" 通过日志发现 104: Connection reset by peer 是由于buffer太小导致,参考相关资料, 而buffer太小可能是导致golangServer写入nginx时panic的原因。此次需要继续调优 nginx
- 1.修改worker_rlimit_nofile 10240
- 2.增大buffer缓冲区
继续上线观察。
5.线上观察(2021-01-17)
1月17日上午api-gateway的panic问题再次重现。由于前面做了准备,这次直接登上panic服务查看日志:
//api-gateway机器ip
2021/01/17 10:45:07 [ERROR] <middlerwares.go:41> [Recovery]#panic# requestId:8e92d5a2-bac7-4d88-a05a-b1ac6a843b60,recovered:POST /user/getUserDeviceList HTTP/1.0^M
Host: xx.xx.xx.net^M
Connection: close^M
Accept-Encoding: gzip^M
Connection: close^M
Content-Length: 185^M
Content-Type: application/x-www-form-urlencoded^M
User-Agent: beegoServer^M
X-Forwarded-For: 10.209.158.198^M
X-Real-Ip: 10.209.158.198^M
^M
write tcp 127.0.0.1:8878->127.0.0.1:22705: write: broken pipe 根据日志里的request_id查询api-gateway及backend响应的日志链路:
//api-gateway.log
2021/01/17 10:45:07 [INFO] <server.go:70> [backend-proxy] requestId:8e92d5a2-bac7-4d88-a05a-b1ac6a843b60, endpointPath:/user/getUserDeviceList,backendHost:
//backend.log
2021/01/17 10:45:07 [INFO] <middleware.go:67> __Reqeust_Result__||protocol=http||requestId=8e92d5a2-bac7-4d88-a05a-b1ac6a843b60,statusCode=200,clientIP:xx.xx.xx.1
98,method:POST,path:/user/getUserDeviceList,userAgent:beegoServer,request:
..
约157KB
.. 在api-gateway的日志中发现backend已经正常响应,耗时 3412ms ,说明整个请求链路中问题确定出在 nginx–>api-gateway 这个阶段。由于之前nginx的error日志无法正常输出的问题已经修复,此次期待查看nginx的相关error.log会有所收获。但是却意外的发现 nginx此时无错误日志 。这种情况便推翻了之前的怀疑方向,因为nginx并无报错。难道由于正常超时的原因? 整理了调用链路图及相关超时配置:
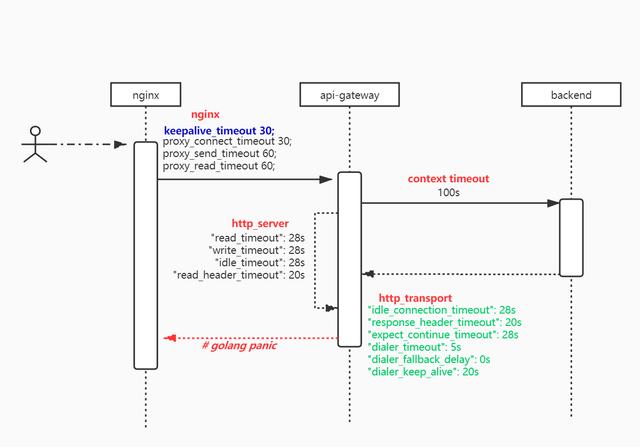
分析发现:nginx的 keepalive_timeout=30s , 而http_server连接池的维护时间 idle_timeout=28s .而此次panic时请求backend耗时3s左右,是由于超过了nginx的timout导致nginx正常关闭? 修改nginx的keepalive时间:
- 修改 keepalive_timeout 为60s
继续上线观察。
6.重要线索(2021-01-17)
1月17日下午, 另一位同学在追踪上午的问题时, 在nginx的access.log中发现了如下日志:
10.xx.158.xx – – [17/Jan/2020:10:45:07 +0800] “POST /user/getUserDeviceList HTTP/1.1” 499 0 “-” “beegoServer” “-“
这条日志显示nginx响应状态码为 499 ,表示client在请求nginx时,由于client设置了超时时间,而nginx并未在超时时间内响应,导致client主动关闭连接。据相关资料nginx 499,nginx收到499之后,会对api-gateway的连接进行关闭。难道是这个原因?细思又不合理,因为又发现nginx一天中会产生很多诸如499的状态码:
...
10.xx.171.xx - - [17/Jan/2021:00:12:02 +0800] "POST /device/updateEvent HTTP/1.1" 499 0 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1)" "-"
10.xx.139.xx - - [17/Jan/2021:00:15:02 +0800] "POST /device/updateEvent HTTP/1.1" 499 0 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1)" "-"
10.xx.xx.3 - - [17/Jan/2021:00:15:02 +0800] "POST /device/updateEvent HTTP/1.1" 499 0 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1)" "-"
10.xx.xx.198 - - [17/Jan/2021:00:30:03 +0800] "POST /device/updateStatus HTTP/1.1" 499 0 "-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1)" "-"
... 这种情况下,应该会有大量的panic出现,但是事实却是寥寥无几。然而在把所有的线索都串了起来之后,突然发现了些什么:
1.api-gateway最近的panic都来源于接口/user/getUserDeviceList
2.与client端同学沟通,他们的请求超时设为3s
3.nginx的keeptimeout为30s, 而golang的idle_timeout为28s
4.panic时,/user/getUserDeviceList请求时间都大于3s (推断)
5.panic时,nginx一定会出现499的状态码(推断) 如上,1,2,3为事实,4,5为推断。所以原因断言如下:
巧合,偶现的问题确实都是巧合,因为不同于必现。
(1) client单方面超时,nginx报499后,因为nginx存在连接池,499后并不会立即关闭socket fd. 而是查看该fd是否keeptimeout过期。
(2)nginx正巧此时keepalive_timeout超过30s,此次client的499导致nginx关闭该socket fd.
(3)而api-gateway此时正在访问后端服务,当访问后端服务结束后,由于nginx已经关闭fd,所以api-gateway第一次写入nginx时收到tcp的RST响应,第二次写入导致panic.
仅为断言,预计修改nginx的keepalive_timeout为60s,该问题不会出现。 继续观察~
7.问题定位–拨开迷雾见晴天
在问题没有被定位之前,断言是可以继续被质疑。于是内心又生出疑惑:
为什么断言nginx的499不会立即关闭proxy的fd?
为什么panic的日志里,http是1.0及connection:close?
这个问题,起初认为是client的同学在用http1.0协议,感觉很古董。但是日志里显示的用的是beego框架,beego的http协议默认是1.1。所以不能单纯的认为是 client 传来的。
深入了解后发现,这个http1.0其实是nginx请求api-gateway时带来的。[
client与nginx, nginx与api-gateway之间真的都用到长连接?
//client与nginx之间的连接
由于nginx配置了keepalive_timeout,所以nginx是支持长连接的。但是需要client使用时复用http对象,否则每次client与nginx交互都是短连。
//nginx与api-gateway
nginx与api-gateway之间,目前的调用方式其实是短连,api-gateway与后端请求建连处理结束后,连接便被nginx关闭。如果需要长连,则配置upstream及proxy_http_version如下:
upstream manager_backend {
server 127.0.0.1:8095;
keepalive 16;
}
proxy_http_version 1.1;
proxy_set_ header Connection “”;
解决了以上几个疑惑后,发现断言是不合理的。但是nginx 499状态码在请求中大量出现,为什么api-gateway的panic却是偶现?
逐渐接近了真相: [
产生panic的原因描述如下:
首先client由于自身业务超时单方面断开连接,而nginx收到client断开连接的请求时,会立即以异常(reset)的方式关闭与api-gateway之前建立的socket连接,并打印499日志。
api-gateway服务在等待backend的数据响应之后,会将响应数据按照批次,分批写入TCP buffer缓冲区中,当缓冲区写满时,会一次性将数据通过socket连接刷到nginx。
第一次通过socket连接将buffer发送给nginx时,nginx作为客户端会向api-gateway的tcp层响应RST报文,所以api-gateway第一次向nginx发送数据是不报错的,但api-gateway的tcp层会设置RST的标记。
当api-gateway作为应用层第二次通过底层tcp向nginx发送数据时,socket则会报broken pipe错误。
TCP buffer缓冲区默认大小(cat /proc/sys/net/ipv4/tcp_wmem)为4kb,而业务中大部分499的状态,其实只有100 byte 左右的响应。但panic时,会发现backend响应的数据报文超过100kb。
上述修改keepalive_timeout为60s并没有实际解决问题,解决方案:
- proxy_ignore_client_abort设为on
8.结论
以上便是记录分析本次问题时的思考过程。问题出现之后,其实解决的方向很重要。当然解决问题需要不断的探索和尝试,这也是自我学习及提高的过程。
上述若有不足之处欢迎指正。
参考
- nginx workerconnection:
- nginx 499:
- nginx proxy:
- golang buffer 8kb:


