摘要
golang最吸引人的特性在于对并发的支持,如果要发挥golang语言高性能的优势,必然要使用协程并发等特性,但是对于一直使用php做主力开发语言的同学来说,对golang的协程、channel、性能优化等会相对比较陌生,这篇文章即是一个golang初学者在近期开发过程中在这些方面实践的学习总结。
log-processor整体逻辑
项目背景
部门目前在利用k8s进行微服务改造,对于k8s服务日志的收集我们使用标准输出的方式,通过filebeat以domonset的形式部署再node上,采集后将日志统一存储到es中。
但是目前这种方案存在两个问题:1、基于标准输出的业务日志格式都相同,不解析日志的话无法对业务做区分;2、某些业务具有持久化到多个存储系统的需求。
这两个问题可以通过logstash来解决,但是logstash的性能不太理想,我们的需求功能也并不复杂,因此考虑使用golang开发一个日志解析转发的工具,后续可以基于该工具根据业务需求提供一些更加多样的功能。
功能概述
log-processor整体有三个模块组成,如下图:

input是数据的输入源,目前订阅qbus的topic,不同数据格式的数据需要使用不同的topic,业务使用的topic以及consumer的实例数写在配置中,服务启动时加载。
channel是数据处理的模块,comsumer消费数据后,将日志数据写入到任务队列中,channel的goroutine从队列中拿数据进行处理,支持对一条日志数据进行多种方式的处理。
output是数据输出端,对应es、qbus、hdfs等客户端的实例,可以将同一份数据存储到不同的存储终端。
数据流通
初始化工作:
- 构建一个M大小的任务队列等待Job写入;
- 初始化N个goroutine,用于等待接收处理任务队列的Job,这里的N要大于M,根据机器性能将N和M调整为合适的数值;
- 启动一个dispatcher协程,用于监听Job队列的数据写入,同时分配协程池内的协程对job进行处理;
- 预分配特定大小的缓存区用于缓存待发送的数据;
- 初始化输出客户端的对象池,当有数据要发送时从发送客户端中中取出可用的client使用;
- 启动一个定时器,每5s发送将缓冲区数据发送一次,防止缓冲区长时间未满,数据不发送;
- 根据配置启动相关topic的consumer goroutine等待消费qbus数据;
- 注册一个信号监听器,监听系统kill信号,服务停止前将缓冲区的数据发送完。
日志的流转过程:
- consumer goroutine将从qbus消费的数据加入到 Job队列,dispatcher协程如果协程池有可用协程,则分配goroutine处理,否则等待N秒,仍没有可用goroutine则Job超时;
- 根据为topic分配的数据解析器对日志数据进行解析处理,处理完往后将数据扔到队列中,等待goroutine将数据写入到输出缓冲区;
- 多个goroutine并发地将数据写入到数据缓冲区中,如果缓冲区满,则将缓冲区数据放到队列中,等待goroutine处理;
- goroutine从output client pool中获取一个client将数据发送到存储目的地。

性能优化的一些思路
协程池
协程池的思路是在服务启动时预先分配一批goroutine,当有任务需要使用协程处理时,直接从协程池中拿一个协程来处理,任务完成中再放回协程池中,而不需要再用go关键字去创建;这种设计的好处在于使得服务启动的goroutine数量是可控的,避免再异常情况下启动大量的goroutine,对内存造成太大压力导致服务挂掉。一个简单的协程池的模型下图所示:

需要注意的是有可能预分配的协程数量太少,导致很多job在队列中等待,这时可以考虑启动一个定时器对超时的任务进行处理,或者是参考slice内存分配的思路,对协程的数量也分配采用动态分配的方式,初始化是启动较少的goroutine,当goroutine不够用是根据增长系数进行动态增长。
临时对象池
临时对象池对应于官方的sync.Pool包,频繁的申请临时对象会对系统的gc带来压力,sync.Pool设计的目的便是保存和复用临时对象,以减少内存分配,降低CG压力。以我们服务中使用的日志解析对象为例进行基准测试:
var (
pool = sync.Pool{
New: func() interface{} {
ins,_ := NewDataProcesser("json",strings.NewReader(sql))
return ins
},
}
)
func BenchmarkByPool(b *testing.B) {
wg := sync.WaitGroup{}
b.N = 100000
wg.Add(b.N)
for i:=0;i<b.N;i++ {
go func() {
ins := pool.Get().(*DataProcesser)
ins.Process(payload)
pool.Put(ins)
}()
wg.Done()
}
wg.Wait()
}
func BenchmarkByNew(b *testing.B) {
wg := sync.WaitGroup{}
b.N = 100000
wg.Add(b.N)
for i:=0;i<b.N;i++ {
go func() {
ins,_ := NewDataProcesser("json",strings.NewReader(sql1))
ins.Process(payload)
}()
wg.Done()
}
wg.Wait()
} 
可以看出在并发较高的情况下,使用sync.pool来复用临时对象相对于直接分配临时对象在耗时与内存方面均要优秀。
sync.pool在使用时需要注意在每次gc时sync.pool的未引用对象都会被清理,因此sync.pool不适合做存放类似连接池的有状态对象。另外如果我们需要在系统停止时对sync.pool中的对象做一些清理操作也比较难实现,这时可以通过channel来预分配一定数量的对象,然后遍历channel对我们创建的对象进行清理。
连接池
连接池的思路和临时对象池类似,核心的实现都在于复用,不同点在于连接池的主要目的在于降低建立网络io连接的代价。
由于sync.Pool在gc时会对对象做回收,如果连接对象在gc时被清理掉,那么在连接db时就要重新三次握手建立连接,代价会比较大。
连接池的另一个优势在于可以对连接数进行限制,防止连接太多导致下游系统连接太多而超载。
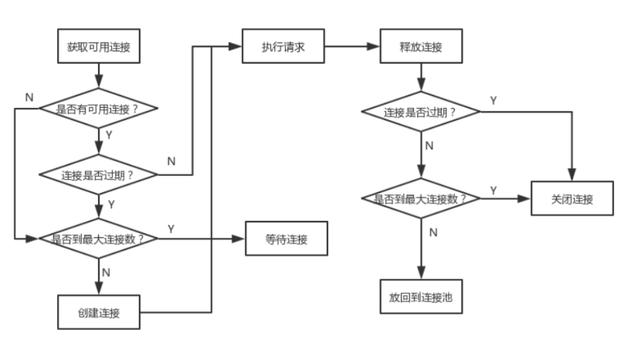
连接池的处理流程相较于对象池会复杂一些,需要考虑健康检查、最大连接数等问题,一个连接池的请求处理流程如下:
减少内存拷贝
对于slice或者map等结构,如果不指定初始长度,使用类似与append的方法,系统会根据需要动态的增长内存容量,这样会导致内存的重新分配,增大gc压力,因此在可以预估容量时,可以考虑初始化固定长度,避免内存拷贝造成的开销。
func test(m map[int]int){
for i:=0;i<10000;i++ {
m[i] = i
}
}
func BenchmarkMap(b *testing.B) {
for i:=0;i<b.N;i++ {
m := make(map[int]int)
test(m)
}
}
func BenchmarkCapMap(b *testing.B) {
for i:=0;i<b.N;i++ {
m := make(map[int]int,10000)
test(m)
}
} 
对上面的两种方式做基准测试如下:
可以看出预分配固定长度的内存,开销只有动态分配的一半。
另一个容易产生内存拷贝的场景是[]byte和string的转换,golang会重新开辟一块内存保存转换的数据,当数据量较大时我们应该尽量减少两者之间的转换。
减少IO
网络、磁盘等io操作往往时比较耗时的,对于这种场景,可以考虑通过先将数据写入内存中缓存,达到一定量后在批量进行io操作来降低io消耗。但是在使用缓冲机制的时候,也有一些问题需要考虑:
- 缓冲区的数据保存在内存中,程序异常终止可能会造成数据丢失,所以需要考虑定期地将数据持久化或者发送出去,以及在服务关停的时候,需要平滑地结束。
- 多个协程并发地往缓冲区写数据的时候,一般会存在并发的问题,这个时候可以通过channel或者对缓冲区加锁解决,同时需要衡量锁带来的开销。
关于锁
在使用协程并发处理时,很多情况下不可避免地需要用到锁,在使用锁的时候有下面几个思路可以参考:
- 细化锁的粒度、减少锁的持有时间:
type AA struct { a1 A1
a2 A2
}
type A1 struct {
sync.Mutex //只把锁加在竞争的数据上
raceData []string
} - 保证锁一定会被释放,可以在lock后使用defer来保证锁被释放
func(){
m.Lock()
defer m.Unlock()
dosometing
}()
hannel是线程安全的并且不会有数据冲突,在一些场景下channel可能会比锁更加合适,锁适合静态的数据,而对流转的数据则channel更加适合。
尝试使用更高性能的非官方包
有时候官方的包不一定是最合适我们业务的包,当定位性能问题出现在官方包时可以考虑使用一些性能更高的第三方包做替换:
例如官方的json包和http包,在性能上落后于很多的第三方包,为了追求性能的进一步提升,可以考虑使用第三方包,但要注意可能会有坑。

性能分析工具
go pprof
pprof是官方提供的性能采样分析工具,可以通过runtime/pprof、net/http/pprof、go test三种方式生成pprof采样数据,以net/http/pprof为例,在main函数中加入如下的代码:
import (
_ "net/http/pprof"
)
func main(){
go func() {
http.ListenAndServe("0.0.0.0:8080", nil)
}()
} 服务运行时通过浏览器访问 即可看到cpu、内存等数据。

也可以在命令行通过go pprof生成采样数据,这个时候pprof会对进程进行30s的采样:go tool pprof
使用top命令查看cpu占用排序:

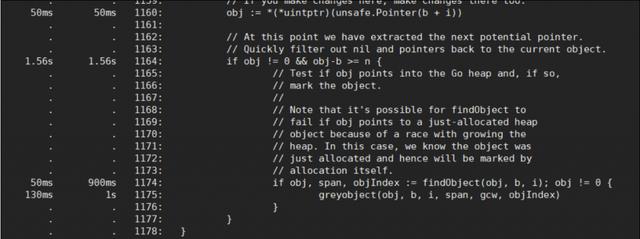
使用 list 命令查看具体耗时的代码:
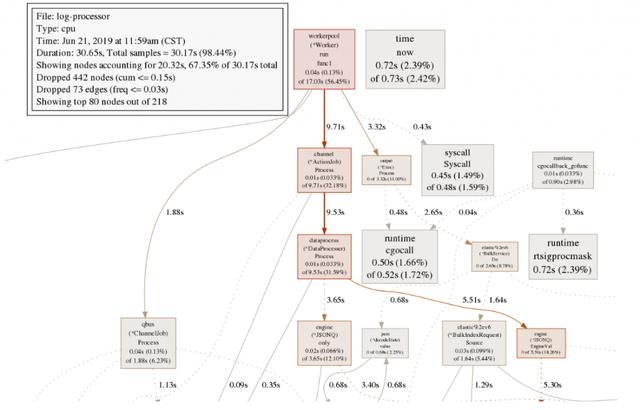
通过 png > cpu.png命令可以将结果生成图片得到调用链路耗时情况,如下图:
pprof支持对多种指标进行采样,比如heap、block等,可以根据需要选择分析。
火焰图
go-torch是uber开源的性能分析工具,本身是基于pprof做的改进,让采样结果更加直观,安装go-torch后,只要执行类似pprof的命令,便可以生成直观的性能火焰图:go-torch -u -t 30
生成的svg图如下:

函数所在的矩形越宽说明该函数消耗的时间越多,相邻两行的宽度对比很形象地反映了具体时那个调用占用了较多的时间。
GODEBUG
在应用启动时加上GODEBUG可以对特定的进行监测
GODEBUG=gctrace=1 2>gclog.log ./log-processor filtrate -q 1000 -w 30000

如果发现gc存在问题,可以通过方式查看每次gc的信息,上图中 16%这个数据代表的即是gc时间占程序运行的百分比,可以考到gc压力还是比较大的。
GODEBUG还支持schedtrace、scheddetail等很多其他的运行时环境变量,根据需要可以选择开启。
Benchmark
在使用pprof或者go-torch定位到问题改进后,可以使用golang官方的test包进行基准测试,比较改进效果
go test -bench=. -benchmem -count=1 -cpuprofile=cpu.profile
上述命令测试结果会同时展示内存分配信息,生成运行时cpu消耗情况,以上面的减少内存拷贝的代码为例,测试结果如下:

2000表示测试的次数,557535 ns/op代表的是每次测试消耗的纳秒时间,第四列表示的是每测试消耗的内存,最后一列是每次测试分配的对象数量。


