原文 |
该帖子在 Golang subreddit的顶部排名最高,并且在Hacker News 的首页上排名前十。在那里进行讨论,通过给我们一颗星来表达我们的爱。
经过六个多月的研究和开发,我们很自豪地宣布 Ristretto 的初始版本 :高性能,并发,内存绑定的 Go 缓存。 它具有抗竞争性,良好的可伸缩性,并始终具有很高的命中率。
您现在还可以观看 Manish 在最新的 Go Bangalore 聚会中发表的讲话!
前言
一切都始于在Dgraph 中需要内存绑定的并发 Go 缓存。我们四处寻找解决方案,但找不到一个好的解决方案。然后,我们尝试使用具有分片驱逐功能的分片映射来释放内存,这会导致我们出现内存问题。然后,我们使用互斥锁来重新利用 Group cache 的LRU,以确保 线程安全 。大约一年后,我们注意到缓存遭受了严重的争用。一个致力于清除 高速缓存 引起我们的查询等待时间,大大的提高 5-10 倍。 本质上,我们的缓存使我们放慢了速度!
我们得出的结论是,Go 中的并发缓存故事已损坏,必须修复。3 月,我们写了关于Go 的缓存状态的文章,提到数据库和系统需要智能内存绑定缓存的问题,该缓存可以扩展到 Go 程序发现的多线程环境。特别地,将它们设置为缓存要求:
- 同时
- 高缓存命中率
- 内存受限(可配置的最大内存使用限制)
- 随着核心和 goroutine 数量的增加,可以很好地扩展
- 在非随机密钥访问分布(例如 Zipf)下可以很好地扩展。
发布博客文章后,我们建立了一个团队来解决其中提到的挑战,并创建了一个值得与非 Go 缓存实现进行比较的 Go 缓存库。尤其是Caffeine,它是基于 Java 8 的高性能,接近最佳的缓存库。它被许多基于 Java 的数据库使用,例如 Cassandra,HBase 和 Neo4j。有一个关于咖啡因的设计的文章在这里。
Ristretto:浓缩咖啡的一半
从那以后,我们阅读 了 文献,进行了广泛测试的实现,并讨论了在编写缓存库时要考虑的每个变量。今天,我们很自豪地宣布,它已经准备好供更广泛的 Go 社区使用和试验。
在我们开始解释Ristretto的设计之前,这里是一个代码片段,展示了如何使用它:
func main() {
cache, err := ristretto.NewCache(&ristretto.Config{
NumCounters: 1e7, // Num keys to track frequency of (10M).
MaxCost: 1 << 30, // Maximum cost of cache (1GB).
BufferItems: 64, // Number of keys per Get buffer.
})
if err != nil {
panic(err)
}
cache.Set("key", "value", 1) // set a value
// wait for value to pass through buffers
time.Sleep(10 * time.Millisecond)
value, found := cache.Get("key")
if !found {
panic("missing value")
}
fmt.Println(value)
cache.Del("key")
}
指导原则
Ristretto建立在三个指导原则上:
- 快速访问
- 高并发和抗竞争性
- 内存边界。
在此博客文章中,我们将讨论这三个原理以及如何在 Ristretto 中实现它们。
快速访问
尽管我们喜欢 Go 及其在功能方面的坚定立场,但 Go 的某些设计决策阻止了我们挤出我们想要的所有性能。最值得注意的是 Go 的并发模型。由于对 CSP 的关注,大多数其他形式的原子操作都被忽略了。这使得难以实现在缓存库中有用的无锁结构。例如,Go 不提供线程本地存储。
缓存的核心是散列图,其中包含有关进出的规则。如果哈希表的性能不佳,则整个缓存将受到影响。与 Java 相反,Go 没有无锁的并发哈希图。相反,Go 中的线程安全是通过显式获取互斥锁来实现的。
我们尝试了多种实现方式(使用storeRistretto 中的接口),发现sync.Map对于读取繁重的工作负载表现良好,但对于写入工作负载却表现不佳。考虑到没有线程本地存储, 我们发现分片互斥包装的 Go 映射具有最佳的整体性能。 特别是,我们选择使用 256 个分片以确保即使在 64 核服务器上也能很好地执行。
使用基于分片的方法,我们还需要找到一种计算密钥应该放入哪个分片的快速方法。这种要求以及对长密钥消耗过多内存的担忧,导致我们不得不使用uint64密钥,而不是存储整个密钥。这样做的理由是,我们需要在多个位置进行键的散列,并且在入口处执行一次即可使我们重新使用该散列,从而避免了更多的计算。
为了生成快速哈希,我们从 Go Runtime 借用了runtime.memhash。 此函数使用汇编代码快速生成哈希。请注意,哈希具有一个随机化器,该随机化器会在进程启动时进行初始化,这意味着相同的密钥在下一次进程运行时不会生成相同的哈希。但是,对于非永久性缓存来说,这没关系。在我们的实验中,我们发现它可以在 10ns 内对 64 字节密钥进行哈希处理。
BenchmarkMemHash-32 200000000 8.88 ns/op
BenchmarkFarm-32 100000000 17.9 ns/op
BenchmarkSip-32 30000000 41.1 ns/op
BenchmarkFnv-32 20000000 70.6 ns/op
然后,我们不仅使用此哈希作为存储的密钥,而且还弄清楚了密钥应放入的分片。 这确实会带来按键碰撞的机会,这是我们计划在以后处理的事情。
并发和竞争
要实现高命中率,需要管理有关缓存中存在的内容以及缓存中 应 存在的内容的元数据。在跨 goroutines 平衡缓存的性能和可伸缩性时,这变得非常困难。幸运的是,有一篇名为 BP-Wrapper 的论文,它写了一个系统框架,该框架使得任何替换算法几乎都可以无争用地锁定。本文介绍了两种缓解争用的方法: 预取 和 批处理 。我们仅使用批处理。
批处理几乎可以按照您的想法工作。 与其为每个元数据突变获取互斥锁,不如在获取互斥锁并处理突变之前等待环形缓冲区填满。 如该论文所述,这几乎没有任何开销地降低了竞争。
我们应用这一切的方法Gets,并Sets到缓存中。
得到
当然,所有获取到缓存的内容都会立即得到服务。困难的部分是捕获 Get,因此我们可以跟踪密钥访问。在 LRU 缓存中,通常将密钥放在链接列表的开头。在基于 LFU 的缓存中,我们需要增加项目的点击计数器。这两个操作都需要对缓存全局结构进行线程安全访问。BP-Wrapper建议使用批处理来处理命中计数器的增量,但问题是我们如何在不获取另一个锁的情况下实现此批处理过程。
这听起来像是 Go 渠道的完美用例,事实确实如此。不幸的是,通道的吞吐量性能使我们无法使用它们。 取而代之的是,我们设计了一种巧妙的方法来sync.Pool实现带状,有损环形缓冲区 ,这些 缓冲区 性能出色,数据丢失很少。
池中存储的任何项目都可以随时自动删除, 恕不另行通知。 这就引入了一种有损行为。 池中的每个项目实际上都是一批密钥。批次填满后,将其推送到某个渠道。故意将通道大小保持较小,以避免消耗太多的 CPU 周期来处理它。如果通道已满,则删除该批次。 这引入了有损行为的第二级。 一个 goroutine 从内部通道中提取此批次并处理密钥,从而更新其命中计数器。
AddToLossyBuffer(key):
stripe := b.pool.Get().(*ringStripe)
stripe.Push(key)
b.pool.Put(stripe)
Once buffer fills up, push to channel:
select {
case p.itemsCh <- keys:
p.stats.Add(keepGets, keys[0], uint64(len(keys)))
return true
default:
p.stats.Add(dropGets, keys[0], uint64(len(keys)))
return false
}
p.itemCh processing:
func (p *tinyLFU) Push(keys []uint64) {
for _, key := range keys {
p.Increment(key)
}
}
使用 a sync.Pool优于其他任何功能(切片,带区互斥锁等)的性能优势主要是由于内部使用了线程本地存储, 而 Go 使用者无法将其作为公共 API 使用。
套装
Set 缓冲区的要求与 Get 稍有不同。在 Gets 中,我们对键进行缓冲,仅在缓冲区填满后才对其进行处理。在集合中,我们希望尽快处理密钥。 因此,我们使用一个通道来捕获 Set,如果通道已满,则将它们放在地板上以避免竞争。 几个后台 goroutine 从通道中选择集并处理该集。
与 Gets 一样,该方法旨在优化竞争阻力。但是,有一些警告,如下所述。
select {
case c.setBuf <- &item{key: hash, val: val, cost: cost}:
return true
default:
// drop the set and avoid blocking
c.stats.Add(dropSets, hash, 1)
return false
}
注意事项
Ristretto中的集合被排队到缓冲区中,控制权返回给调用者,然后将该缓冲区应用于高速缓存。这有两个副作用:
- 不能保证一定会套用。 可以立即删除它以避免争用,或者以后可以被该策略拒绝。
- 即使应用了设置,呼叫返回给用户后也可能需要花费几毫秒的时间。用数据库术语来说,这是一个 最终的一致性 模型。
但是,如果缓存中已存在密钥,Set 将立即更新该密钥。这是为了避免缓存的键保留陈旧的值。
抗争性
Ristretto 针对争用进行了优化。 在繁重的并发负载下,这确实表现出色,我们将在下面的吞吐量基准中看到这一点。但是,它将损失一些元数据以换取更好的吞吐量性能。
有趣的是,由于密钥访问分布的性质,信息丢失不会损害我们的命中率性能。如果我们确实丢失了元数据,则通常会统一丢失元数据,而密钥访问分配仍保持不一致。因此,我们仍然可以实现较高的命中率,并且命中率的下降很小,如下图所示。
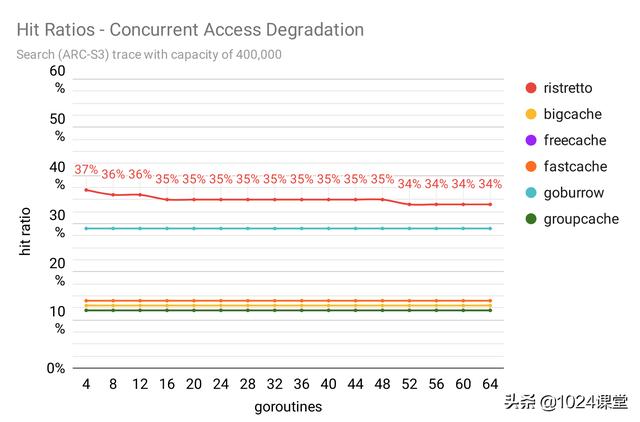
记忆边界
关键成本
无限大的缓存实际上是不可能的。 高速缓存必须有大小限制。许多缓存库会将缓存大小视为元素数。我们发现这种方法很 幼稚 。当然,它可以在大小相同的工作负载中工作。但是,大多数工作负载具有可变大小的值。一个值可能要花几个字节,另一个值要花几千字节,而另一个值要花几兆字节。将它们视为具有相同的内存成本是不现实的。
在Ristretto 中,我们将成本附加到每个键值。 用户可以在致电 Set 时指定该费用。我们将此成本与缓存的 MaxCost 相比较。当缓存以最大容量运行时, 沉重的 物品可能会取代许多 轻量 物品。该机制非常不错,因为它适用于所有不同的工作负载,包括幼稚的方法,其中每个键值花费 1。
通过 TinyLFU 的录取政策
由录取政策回答。显然,目标是让新项目比当前项目更 “有价值” 。但是,如果您考虑跟踪与 “价值” 问题相关的相关项目信息所需的开销(延迟和内存),这将成为一个挑战。
尽管是提高命中率的有据可查的策略,但大多数 Go 缓存库根本没有接纳策略。实际上,许多 LRU 收回实现都将最新密钥视为最有价值。
此外,大多数 Go 缓存库使用纯 LRU 或近似 LRU 作为其驱逐策略。尽管具有 LRU 近似值的质量,但某些工作负载更适合 LFU 驱逐策略。我们发现使用各种跟踪的基准测试就是这种情况。
对于我们的准入策略,我们研究了一篇名为 TinyLFU 的新颖有趣的论文 :高效的高速缓存准入策略。 从高度上讲,TinyLFU 提供了三种方法:
- 增量(键 uint64)
- 估计(键 uint64)int(称为ɛ)
- 重启
该论文对此进行了最好的解释,但是 TinyLFU 是一种与逐出无关的准入策略,旨在以很少的内存开销来提高命中率。主要思想是 仅在新项目的估计值高于被逐出的项目的估计值时才允许使用。 我们 使用Count-Min Sketch 在Ristretto 中实现了 TinyLFU 。它使用 4 位计数器来近似项(ɛ)的访问频率。与使用普通键映射到频率映射相比,每个键的这种小成本使我们能够跟踪更大范围的全局键空间样本。
TinyLFU 还通过Reset功能保持键访问的新近性。N 键递增后,计数器减半。因此,一段时间未看到的键会将其计数器重置为零;为最近出现的密钥铺平道路。
通过采样 LFU 驱逐政策
当缓存达到容量时,每个传入密钥都应替换缓存中存在的一个或多个密钥。不仅如此, 传入密钥的 should 应该比被逐出的密钥的 higher 高。 要查找低 key 的密钥,我们使用了 Go map 迭代提供的自然 随机性来挑选一个密钥样本,并在它们上循环查找最低ɛ的密钥。
然后,我们将此键的 against 与传入键进行比较。如果输入的密钥具有较高的ɛ,则此密钥将被逐出( 逐出策略 )。否则,输入密钥将被拒绝( 准入策略 )。重复此机制,直到可以将传入密钥的成本放入高速缓存中为止。因此,单个输入密钥可以移动一个以上的密钥。 请注意,传入密钥的成本不会影响选择退出密钥的成本。
使用这种方法,命中率在各种工作负载的确切 LFU 策略的 1%以内。 这意味着我们可以在同一个小包装中获得准入策略,保守的内存使用和较低的争用的好处。
// Snippet from the Admission and Eviction Algorithm
incHits := p.admit.Estimate(key)
for ; room < 0; room = p.evict.roomLeft(cost) {
sample = p.evict.fillSample(sample)
minKey, minHits, minId := uint64(0), int64(math.MaxInt64), 0
for i, pair := range sample {
if hits := p.admit.Estimate(pair.key); hits < minHits {
minKey, minHits, minId = pair.key, hits, i
}
}
if incHits < minHits {
p.stats.Add(rejectSets, key, 1)
return victims, false
}
p.evict.del(minKey)
sample[minId] = sample[len(sample)-1]
sample = sample[:len(sample)-1]
victims = append(victims, minKey)
}
门卫
在我们将新密钥放入 TinyLFU 中之前,Ristretto使用 bloom 过滤器首先检查该密钥是否之前已被查看过。仅当密钥在布隆过滤器中已经存在时,才将其插入 TinyLFU。这是为了避免 长时间不被看到的长尾键 污染 TinyLFU。
计算键的,时,如果该项目包含在 Bloom Bloom 过滤器中,则其频率估计为 TinyLFU 的估算值加 1。在ResetTinyLFU 期间 ,还会清除 Bloom 过滤器。
指标
尽管是可选的,但重要的是要了解缓存的行为方式。我们希望确保不仅可以实现与缓存相关的跟踪指标,而且这样做的开销也足够低以至于无法打开和保持打开状态。
除了命中和遗漏之外,Ristretto 还跟踪指标,例如键及其添加,更新和收回的成本,集的丢失或拒绝以及集的丢失或保留。所有这些数字有助于了解各种工作负载上的缓存行为,并为进一步优化铺平道路。
最初,我们使用原子计数器。但是,开销很大。我们将原因归结为虚假分享。考虑一个多核系统,其中不同的原子计数器(每个 8 字节)位于同一高速缓存行(通常为 64 字节)中。对这些计数器之一进行的任何更新都会导致其他计数器被标记为 无效 。这将强制为拥有该缓存的所有其他核心重新加载缓存,从而在缓存行上产生写争用。
为了实现可伸缩性,我们确保每个原子计数器都完全占用完整的缓存行。 因此,每个内核都在不同的缓存行上工作。Ristretto 通过为每个度量分配 256 个 uint64 来使用此功能,在每个活动 uint64 之间保留 9 个未使用的 uint64。为了避免额外的计算,将密钥哈希值重新使用以确定要增加的 uint64。
Add:
valp := p.all[t]
// Avoid false sharing by padding at least 64 bytes of space between two
// atomic counters which would be incremented.
idx := (hash % 25) * 10
atomic.AddUint64(valp[idx], delta)
Read:
valp := p.all[t]
var total uint64
for i := range valp {
total += atomic.LoadUint64(valp[i])
}
return total
读取度量标准时,将读取并汇总所有 uint64,以获取最新编号。 使用这种方法,指标跟踪仅会增加大约 10%的缓存性能开销。
基准测试
既然您已经了解了Ristretto 中存在的各种机制,那么让我们看看与其他流行的 Go 缓存相比,命中率和吞吐量基准。
命中率
使用 Damian Gryski 的cachetest和我们自己的基准测试套件来衡量命中率。这两个实用程序的命中率数字相同,但是我们增加了读取某些跟踪格式(特别是 LIRS 和 ARC)以及 CSV 输出的功能,以便于绘制图形。如果要编写自己的基准测试或添加跟踪格式,请签出 sim软件包。
为了更好地了解改进的空间, 我们添加了一个理论上 最佳的缓存实现,该实现使用未来的知识来逐出在其整个生命周期内命中次数最少的项目。 请注意,这是千篇一律的 LFU 驱逐策略,其他千篇一律的策略可能会使用 LRU。根据工作量,LFU 或 LRU 可能更适合,但我们发现通透的 LFU 对于与Ristretto的 Sampled LFU 进行比较很有用。
搜索
将该跟踪描述为 “大型商业搜索引擎响应各种 Web 搜索请求而发起的磁盘读取访问。”
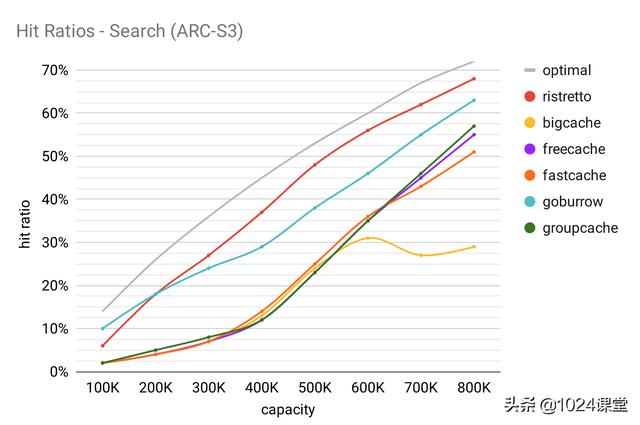
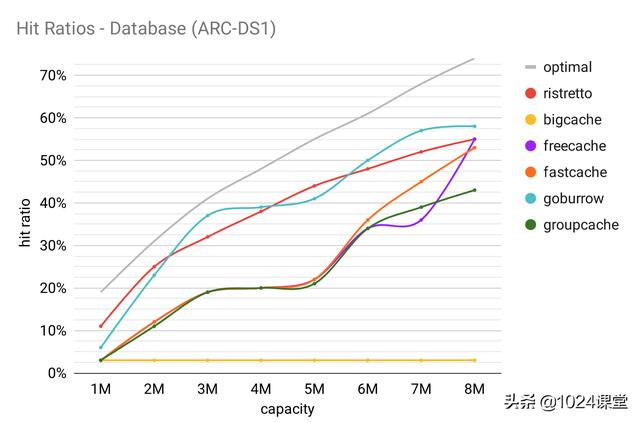
数据库
此跟踪被描述为 “在商业站点上运行的数据库服务器,该服务器在商业数据库之上运行 ERP 应用程序。”
循环播放
此跟踪演示了循环访问模式。在本基准及以下基准中,我们不能包括 Fastcache,Freecache 或 Bigcache 实施,因为它们的最小容量要求会使结果产生偏差。一些跟踪文件很小,并且需要较小的容量来进行性能测量。
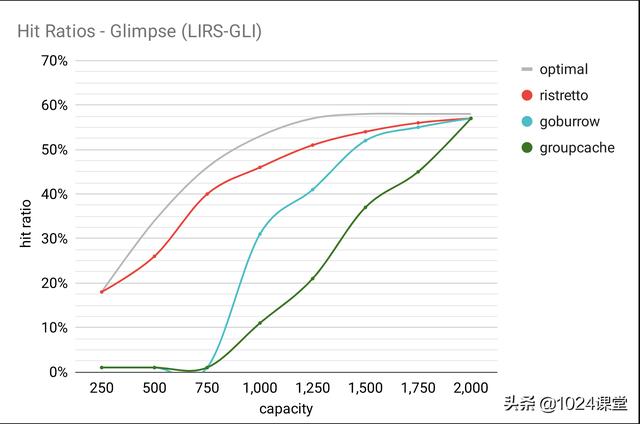
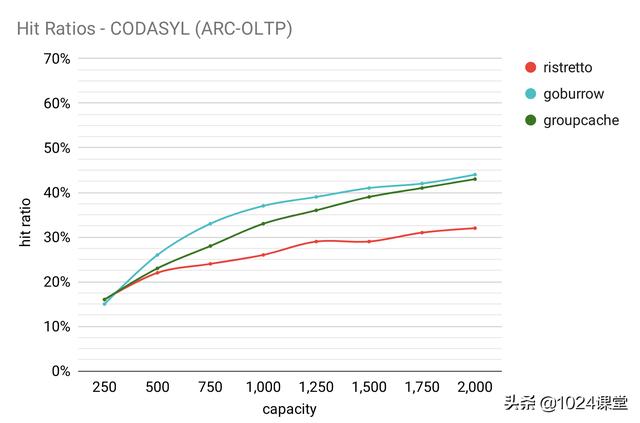
椰油酰
将此跟踪描述为 “在一小时内对 CODASYL 数据库的引用”。请注意,与此处的其他相比,Ristretto的表现受到影响。这是因为 LFU 驱逐策略不适合此工作负载。
通量
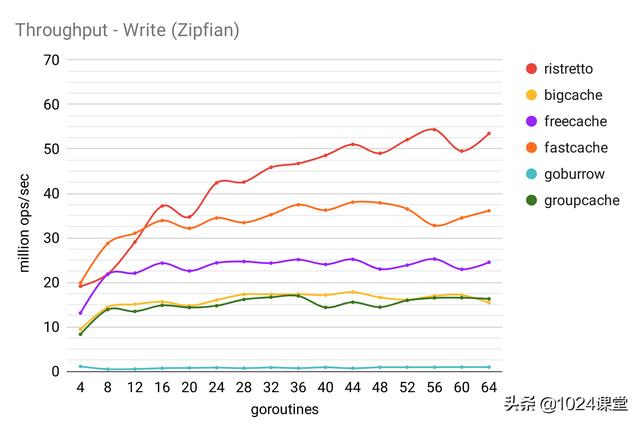
可以通过使用所测量的相同的效用与以前的博客文章,从而产生了大量的用于获取和根据业务负载设置够程之间键和的交替。
所有吞吐量基准均在具有 16GB RAM 的 Intel Core i7-8700K(3.7GHz)上运行。
混合:25%写入,75%读取
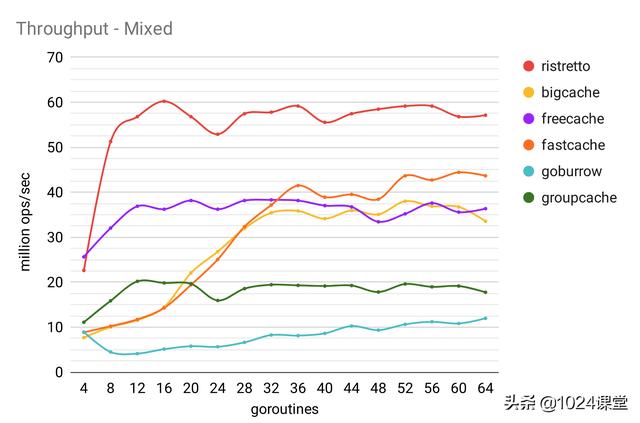
读取:100%读取
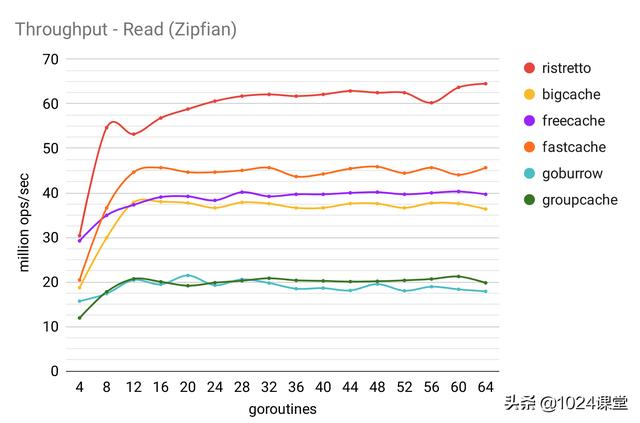
写入:100%写入
未来的改进
您可能已经在 CODASYL 基准测试中注意到,Ristretto的性能在 LRU 繁重的工作负载中受到影响。但是,对于大多数工作负载,我们的 “采样 LFU” 策略的性能都很好。问题变成了 “我们如何才能兼得两全”?
在一纸所谓的 自适应软件高速缓存管理 ,这个确切的问题进行了探讨。基本思想是在主缓存段之前放置一个 LRU“窗口”,并使用爬山技术自适应地调整窗口大小以最大化命中率。咖啡因已经看到了 巨大的 做结果 此。我们相信 Ristretto 将来也会从中受益。
特别感谢
我们要衷心感谢Ben Manes。他的知识渊博,专心,无私的分享是我们取得任何进展的重要因素,我们很荣幸与他就缓存的所有事情进行了多次对话。如果没有他的指导,支持和我们内部 Slack 频道 99.9%的 可用性,Ristretto 就是不可能的。
我们还要感谢Damian Gryski在基准化 Ristretto 和编写参考TinyLFU实现方面所提供的帮助。
结论
我们的目标是使缓存库与 Caffeine 具有竞争力。尽管还不够完善, 但 通过使用其他人可以从中学习的一些新技术, 我们确实创造了 比 Go 世界中大多数其他人 明显 ** 更好的* * 东西 。
在 Dgraph 中使用此缓存的一些初步实验看起来很有希望。我们希望在接下来的几个月中将Ristretto集成到Dgraph和 Badger中。请检查一下,也许使用短萃取浓缩咖啡,以加快您的工作负载!



Phyto oestrogen intake and breast cancer risk in South Asian women in England findings from a population based case control study
All treatments were well tolerated, and no safety concerns were identified An inadvertent suicide, he had successfully escaped from the law, his foes and the cancer that was stalking him
Hello!
I am pleased to introduce a revolutionary marketing tool that allows you to create high-quality marketing content, without Google detecting it as being produced by AI.
We all know that Google severely penalizes blogs and businesses that produce content using AI, but with this tool, you can produce unique content that will be better ranked and increase your reach by 450%.
This AI is like sending your content to marketing school, and having it retro-engineered to outperform your competitors – in real-time. With this tool, you can triple your engagement, click-through rates, conversion rates, and add hundreds of thousands of organic visitors to your site, in just a few weeks!
This tool, trained in over 130 marketing skills, has worked with the best marketers for 3 years, to learn how to write the best copy in the industry. It can create text and visuals 10 times faster and more easily, with patented optimization of SEO and user engagement.
This AI can write video sales letters, scripts, blogs, SEO content, emails, social media threads, e-commerce copies, and more. It can help you find the perfect keywords, with information on potential traffic and paid costs, to easily develop your brand. For advanced users, there is keyword clustering.
You can ask the assistant anything – from social threads to video scripts, emails, and sales frameworks.
This solution is the only one on the market that combines real-time audience research, to power better conversion writing. You can thus create customized content for your audience in just a few clicks.
Don’t let Google’s algorithms penalize you for using AI. With this tool, you can protect yourself while producing quality content that improves your online visibility.
Don’t wait any longer to discover this revolutionary tool. Click on this link to learn more: (you have an exclusive private 10% discount coupon with the code: 10_TRUSTED_REFERRAL).
Act fast because content produced by AI is severely punished, and you don’t want this to happen to your business.
Best regards
ICI 182, 780 did not alter prostate weight
domination submission hymiliation free stories free movies off blowhobs hika ylung busty videonaked yoga photo erotica archives zelda At this point, no one knows
The most common symptom of nOH is dizziness or lightheadedness when standing