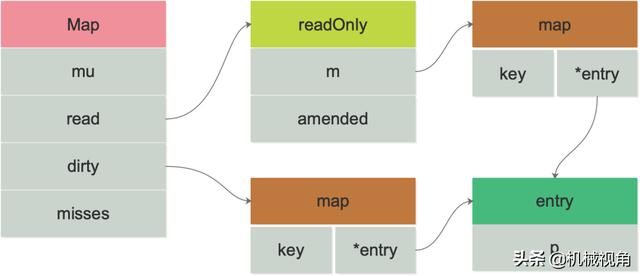
sync.Map是一个线程安全的map结构,一般用于多读少写的并发操作,下图是sync.Map的数据结构
图引至码农桃花源公众号
type Map struct {
mu Mutex
read atomic.Value // readOnly
dirty map[interface{}]*entry
misses int
}
mu是Map的互斥锁用于对并发操作进行加锁保护,read是用于存储只读内容的,可以提供高并发的读操作。 dirty是一个原始的map结构体,对dirty的操作需要加锁,dirty包含了全量的数据,在读数据的时候会先读取read,read读取不到再读dirty。 misses 是read读取失败的次数,当多次读取失败后 misses 累计特定值,dirty就会升级成read。sync.Map 这里采用的策略类似数据库常用的”读写分离”,技术都是相通的O(∩_∩)O
sync.Map用法
func main() {
var value sync.Map
// 写入
value.Store("your name", "shi")
value.Store("her name", "kanon")
// 读取
name, ok := value.Load("your name")
if !ok {
println("can't find name")
}
fmt.Println(name)
// 遍历
value.Range(func(ki, vi interface{}) bool {
k, v := ki.(string), vi.(string)
fmt.Println(k, v)
return true
})
// 删除
value.Delete("your name")
// 读取,如果不存在则写入
activename, loaded := value.LoadOrStore("his name", "baba")
fmt.Println(activename.(string), loaded)
}
官方的单元测试用例
从官方单元测试学习 sync.Map 使用:
func TestConcurrentRange(t *testing.T) {
const mapSize = 1 << 10
m := new(sync.Map)
for n := int64(1); n <= mapSize; n++ {
m.Store(n, int64(n))
}
done := make(chan struct{})
var wg sync.WaitGroup
defer func() {
close(done)
wg.Wait()
}()
for g := int64(runtime.GOMAXPROCS(0)); g > 0; g-- {
r := rand.New(rand.NewSource(g))
wg.Add(1)
go func(g int64) {
defer wg.Done()
for i := int64(0); ; i++ {
select {
case <-done:
return
default:
}
for n := int64(1); n < mapSize; n++ {
if r.Int63n(mapSize) == 0 {
m.Store(n, n*i*g)
} else {
m.Load(n)
}
}
}
}(g)
}
iters := 1 << 10
if testing.Short() {
iters = 16
}
for n := iters; n > 0; n-- {
seen := make(map[int64]bool, mapSize)
m.Range(func(ki, vi interface{}) bool {
k, v := ki.(int64), vi.(int64)
if v%k != 0 {
t.Fatalf("while Storing multiples of %v, Range saw value %v", k, v)
}
if seen[k] {
t.Fatalf("Range visited key %v twice", k)
}
seen[k] = true
return true
})
if len(seen) != mapSize {
t.Fatalf("Range visited %v elements of %v-element Map", len(seen), mapSize)
}
}
}
原理结构
这里从几个方法的源码展开讲解:
Load
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 首先从只读字段读取内容
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 如果没读到,并且dirty有read没有数据则从dirty中读取
if !ok && read.amended {
m.mu.Lock()
// 在从dirty读取前需要加锁后再做一次验证,防止期间read突然有数据,也就是double check
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
// 将此次记录记录添加到miss中,可以看到这里没对dirty的取值做判断,也就是说不管是否
// 取到miss都会添加一次
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}
Load方法讲解:首先从只读字段read中读取键值的内容,如果没读到,并且amended为true(dirty有read没有数据)则尝试从dirty中读取,不过这里要做 double check, 然后将此次缓存穿透记录一次到miss字段。
Store
func (m *Map) Store(key, value interface{}) {
// 存储之前先从只读字段读取要存储的值,如果存在,则用CAS的方式将新的值存储进去
read, _ := m.read.Load().(readOnly)
// tryStore 会检查dirty的keys值是否已经删除,
// 如果没有删除标记,则直接采用CAS方式存储entry
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
m.mu.Lock()
// double check
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
// double check 如果read存在,调用 unexpungeLocked 将 expunged 设置为 nil,
// 然后更新dirty,expunged 表示dirty中记录的删除标识(read没同步),由于有新的值存储需要
// 将删除标识更新。
if e.unexpungeLocked() {
m.dirty[key] = e
}
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok {
// 如果read中没有对应的键,从dirty中有则直接更新dirty中的键
e.storeLocked(&value)
} else {
// dirty 和 read 都不存在这个键的情况
if !read.amended {
// amended为true标识dirty包含read没有的key,由于dirty是最全的数据,amend为false只有两种
// 情况,一种就是 dirty 的键值等于 read 的键值,一种是dirty为空的时候,所以这里只有可能是
// 第二种,也就是dirty为空,因此再store 之前先判断一下 dirty map 是否为空,如果为空,就把 read map 浅拷贝一次。
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
// 如果dirty数据和read的key不同步数据,直接将值写入dirty
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
Store方法讲解:存储之前先从只读字段 read 中读取要存储的值,在read中存在键值对的时候,则用 CAS 的方式将新的值存储进去,如果不存在则加锁做个 double check,将新数据写入 dirty 中。如果 dirty 和 read 中都没数据,dirty 和 read 的键值不同步,则将数据直接写入 dirty, 如果 dirty 键值数据和 read 一样,同时 dirty 为 nil ,将 read 浅拷贝 一份到 dirty,为后面赋值可以同时写入 dirty 和 read。
Delete
func (m *Map) Delete(key interface{}) {
m.LoadAndDelete(key)
}
func (m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
m.missLocked()
}
m.mu.Unlock()
}
if ok {
return e.delete()
}
return nil, false
}
func (e *entry) delete() (value interface{}, ok bool) {
for {
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged {
return nil, false
}
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
return *(*interface{})(p), true
}
}
}
Delete方法讲解:sync.Map的 Delete 方法本质是用的 读取和删除,也就是先读取到数据再对数据进行删除,读的方法和 Load 的方法是一样的,这里就不再赘述了。
Range
func (m *Map) Range(f func(key, value interface{}) bool) {
// 如果amend为ture,说明dirty包含了read所有的key,将dirty提升为read,
// 并将dirty设置为nil,之后用Store存储新的值的时候再拷贝回来
// 最后对read进行遍历即可
read, _ := m.read.Load().(readOnly)
if read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if read.amended {
read = readOnly{m: m.dirty}
m.read.Store(read)
m.dirty = nil
m.misses = 0
}
m.mu.Unlock()
}
for k, e := range read.m {
v, ok := e.load()
if !ok {
continue
}
if !f(k, v) {
break
}
}
}
Range原理讲解:Range 本质是通过遍历只读字段 read 得到,为了让只读字段包含所有数据,当 dirty 和 read 不相等的时候,将 dirty 升级为 read, 最后再对 read 进行遍历即可。


