前言;
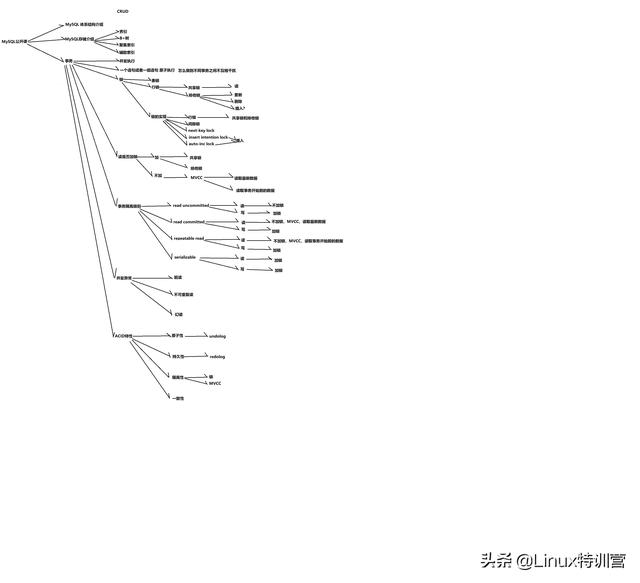
使用MySQL时候不要停留在对数据的CRUD的操作,如果大家想去大厂工作,我们需要对MySQL有哦充分的了解和认知,可后台私信:资料:一起学习领取 思维导图 详细学习教程
MySQL体系结构
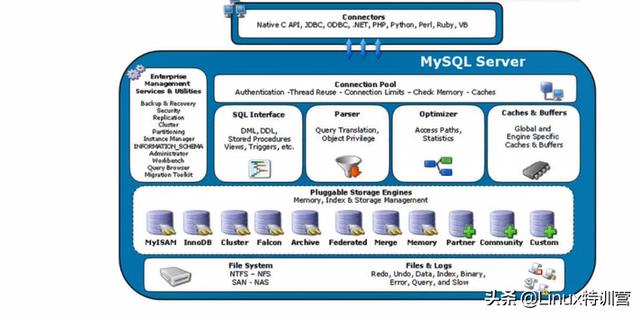
由图,可以看出MySQL最上层是连接组件。下面服务器是由连接池、管理工具和服务、SQL接口、解析器、优化器、缓存、存储引擎、文件系统组成。
连接池 :由于每次建立建立需要消耗很多时间,连接池的作用就是将这些连接缓存下来,下次可以直接用已经建立好的连接,提升服务器性能。
管理工具和服务:系统管理和控制工具,例如备份恢复、My SQL 复制、集群等
SQL接口 :接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
解析器 : SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由 Lex 和YACC实现的,是一个很长的 脚本 , 主要功能:
a . 将 sql语句 分解成数据结构,并将这个结构传递到后续步骤,以后 SQL语句 的传递和处理就是基于这个结构的
b . 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的
优化器:查询优化器,SQL语句在查询之前会使用查询优化器对查询进行优化。他使用的是“选取-投影-联接”策略进行查询。
用一个例子就可以理解: select uid,name from user where gender = 1;
这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤
这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤
将这两个查询条件联接起来生成最终查询结果
缓存器 : 查询缓存,如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
通过 LRU 算法将数据的冷端溢出,未来得及时刷新到磁盘的数据页,叫 脏页 。
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
MySQ 中 索引 包括这么几类
索引 分类
:主键索引、唯一索引、普通索引、组合索引、以及全文索引;
主键索引
非空唯一索引,一个表只有一个主键索引:在 innodb 中,主键索引的B+树包含表数据信息
;PRIMARY KEY(key) 唯一索引
不可以出现相同的值,可以有NULL值:
UNIQUE(key) 普通索引
允许出现相同的索引内容;
INDEX (key)
--OR
KEY(key[,...])
组合索引
对表上的多个列进行索引
INDEX idx(keyl,key2[,...]);
UNIQUE(keyl,key2[....];;
PRIMARY KEY(keyl,key2[,...];; 主键选择
innodb 中表是索引组织表,每张表有且仅有一个 主键 ;
1.如果显示设置PRIMARY KEY,则该设置的key为该表的主键;
2.如果没有显示设置,则从非空唯一索引中选择;
1.只有一个非空唯一索引,则选择该索引为主键;
2.有多个非空唯一索引,则选择声明的第一个为主键;
3.没有非空唯一索引,则自动生成一个6字节的_rowid 作为主键;
B+树
多路平衡搜索树, 平衡二叉树 (红黑树属于平衡二叉树)平衡二叉树是什么意思呢?
平衡是指平衡左右子树的高度,二叉就是它有两个列目;
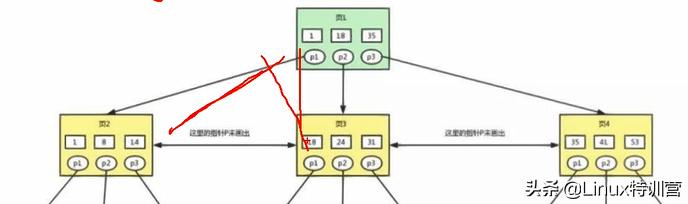
多路是最少大于两路 我们这里是三路;每个都有三路,
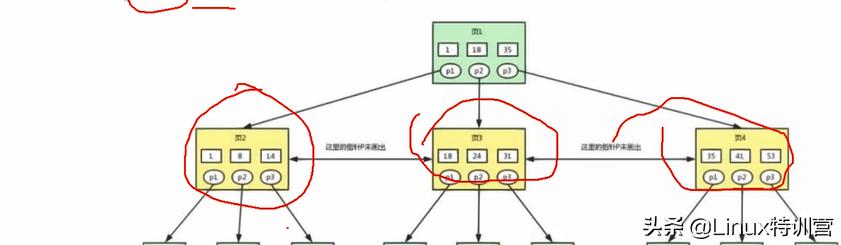
多路高度平衡搜索树 平衡二叉树(红黑树)16K每次访问一个节点都是一次磁盘iol B+描述组织磁盘当中数据 节点长度为1页(4K)
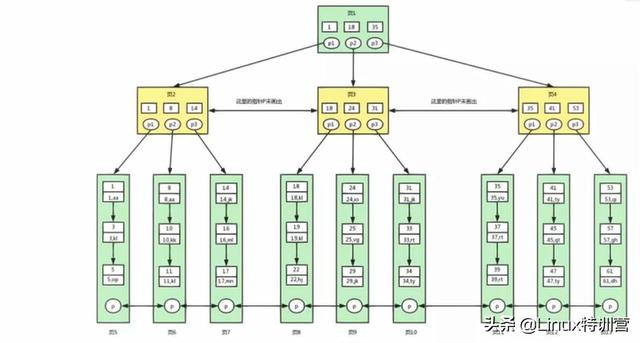
聚集索引
「 聚集索引 」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。

上图就是带有主键的表(聚集索引)的结构图。图画的不是很好, 将就着看。其中树的所有结点(底部除外)的数据都是由主键字段中的数据构成,也就是通常我们指定主键的id字段。最下面部分是真正表中的数据。 假如我们执行一个SQL语句:
select * from table where id = 1256;
首先根据索引定位到1256这个值所在的叶结点,然后再通过叶结点取到id等于1256的数据行。 这里不讲解平衡树的运行细节, 但是从上图能看出,树一共有三层, 从根节点至叶节点只需要经过三次查找就能得到结果。如下图
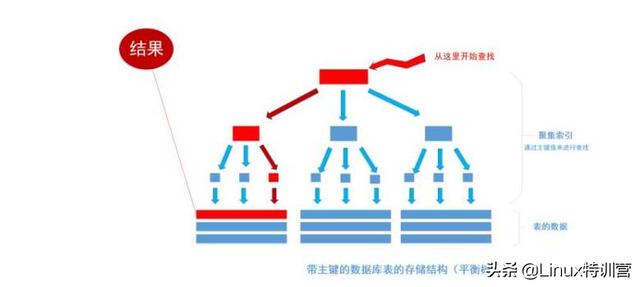
假如一张表有一亿条数据 ,需要查找其中某一条数据,按照常规逻辑, 一条一条的去匹配的话, 最坏的情况下需要匹配一亿次才能得到结果,用大O标记法就是O(n)最坏时间复杂度,这是无法接受的,而且这一亿条数据显然不能一次性读入内存供程序使用
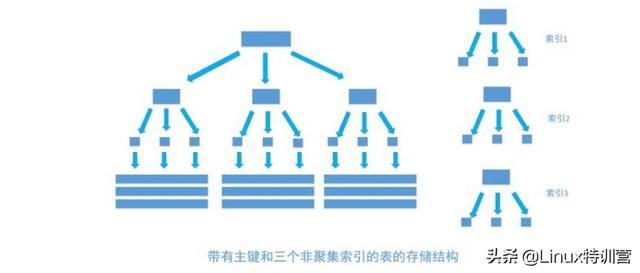
非聚集索引
非聚集索引和聚集索引一样, 同样是采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,在数据改变时, DBMS需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。 如下图
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据,如下图
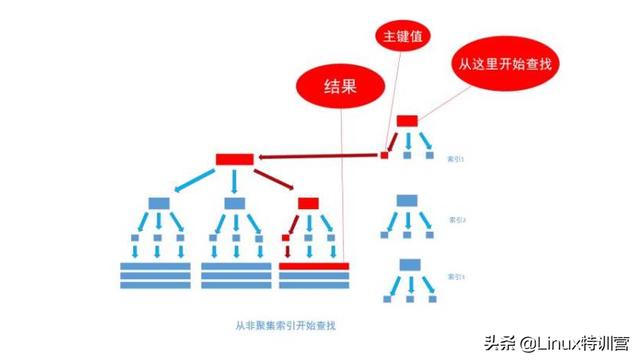
不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径 。
然而, 有一种例外可以不使用聚集索引就能查询出所需要的数据, 这种非主流的方法 称之为「 覆盖索引 」查询, 也就是平时所说的复合索引或者多字段索引查询。 文章上面的内容已经指出, 当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
先看下面这个SQL语句
create index index_birthday on user_info(birthday); //查询生日在1991年11月1日出生用户的用户名
select user_name from user_info where birthday = '1991-11-1' 这句SQL语句的执行过程如下
首先,通过非聚集索引index_birthday查找birthday等于1991-11-1的所有记录的主键ID值
然后,通过得到的主键ID值执行聚集索引查找,找到主键ID值对就的真实数据(数据行)存储的位置
最后, 从得到的真实数据中取得user_name字段的值返回, 也就是取得最终的结果
我们把birthday字段上的索引改成双字段的覆盖索引
create index index_birthday_and_user_name on user_info(birthday, user_name); 这句SQL语句的执行过程就会变为
通过非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的叶节点的内容,然而, 叶节点中除了有user_name表主键ID的值以外, user_name字段的值也在里面, 因此不需要通过主键ID值的查找数据行的真实所在, 直接取得叶节点中user_name的值返回即可。 通过这种覆盖索引直接查找的方式, 可以省略不使用覆盖索引查找的后面两个步骤, 大大的提高了查询性能,如下图

总结;
数据库索引的大致工作原理就是像文中所述, 然而细节方面可能会略有偏差,这但并不会对概念阐述的结果产生影响 。
由于时间问题今天就先介绍到这里详细教程关注+后台私信;资料;两个字可以免费领取 资料内容包括:C/C++,Linux,golang,Nginx,ZeroMQ,MySQL, Redis ,fastdfs, MongoDB , ZK , 流媒体 , CDN ,P2P,K8S,Docker,TCP/IP,协程,DPDK,嵌入式 等。。。


